
Source: Canva
Introduction
In 2018 Google AI released a self-supervised learning model called BERT for learning language representations. And then, in 2019, Yinhan Liu et al. (Meta AI) proposed a robustly optimized approach called RoBERTa (Robustly Optimized BERT-Pretraining Approach) for pretraining natural language processing (NLP) systems that improve on Bidirectional Encoder Representations from Transformers (BERT).
In this article, we will take a look a look at the RoBERTa in more detail.
Now, let’s jump right in!
Highlights
-
RoBERTa is a reimplementation of BERT with some modifications to the key hyperparameters and tiny embedding tweaks, along with a setup for RoBERTa pre-trained models.
-
In RoBERTa, we don’t need to define which token belongs to which segment or use token_type_ids. With the aid of the separation token tokenizer.sep_token (or), we can easily divide the segments.
-
CamemBERT is a wrapper around RoBERTa.
What Prompted the Researchers to Develop a RoBERTa-like Model?
The Facebook AI and the University of Washington researchers found that the BERT model was remarkably undertrained, and they suggested making several changes to the pretraining process to improve the BERT model’s performance.
RoBERTa Model Architecture
RoBERTa model shares the same architecture as the BERT model. It is a reimplementation of BERT with some modifications to the key hyperparameters and minor embedding tweaks.
The BERT’s general pre-training and fine-tuning procedures are shown in the diagram below (See Figure 1). In BERT, Except for the output layers, the same architectures are used in pre-training and fine-tuning. The same pre-trained model parameters are used to initialize models for different downstream tasks. During fine-tuning, all parameters are tweaked.
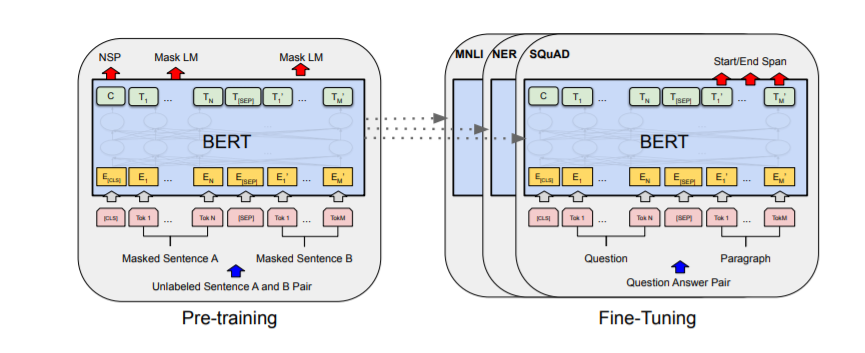
Figure 1: Architecture of BERT model
On the other hand, the RoBERTa doesn’t use the next-sentence pretraining objective, and this model is trained with much larger mini-batches and learning rates. In addition, RoBERTa uses a different pretraining scheme and substitutes a character-level BPE vocabulary for a byte-level BPE tokenizer (similar to GPT-2). Moreover, we don’t have to define which token belongs to which segment because it lacks token_type_ids as well. With the aid of the separation token tokenizer.sep_token (or ), we can easily divide the segments.
Moreover, rather than the 16GB dataset that was originally used to train BERT, RoBERTa is trained on a massive dataset that spans over 160GB of uncompressed text. The dataset for RoBERTa contains (16GB) of English Wikipedia and Books Corpus, which are used in BERT. Additional data included the Web text corpus (38 GB), CommonCrawl News dataset (63 million articles, 76 GB), and Stories from Common Crawl (31 GB). This dataset, along with 1024 running V100 Tesla GPUs for a day, was used to pre-train RoBERTa.
To create RoBERTa, the Facebook team first ported BERT from Google’s TensorFlow deep-learning framework to their framework, PyTorch.
RoBERTa is trained with i) FULL-SENTENCES without NSP loss, ii) dynamic masking, iii) large mini-batches, and iv) a larger byte-level BPE.
The key differences between RoBERTa and BERT can be summarized as follows:
- RoBERTa is a reimplementation of BERT with some modifications to the key hyperparameters and minor embedding tweaks. It uses a byte-level BPE as a tokenizer (similar to GPT-2) and a different pretraining scheme.
- RoBERTa is trained for longer sequences, too, i.e. the number of iterations is increased from 100K to 300K and then further to 500K.
- RoBERTa uses larger byte-level BPE vocabulary with 50K subword units instead of character-level BPE vocabulary of size 30K used in BERT.
- In the Masked Language Model (MLM) training objective, RoBERTa employs dynamic masking to generate the masking pattern every time a sequence is fed to the model.
- RoBERTa doesn’t use token_type_ids, and we don’t need to define which token belongs to which segment. Just separate segments with the separation token tokenizer.sep_token (or ).
- The next sentence prediction (NSP) objective is removed from the training procedure.
- Larger mini-batches and learning rates are used in RoBERTa’s training.
Evaluation Results of RoBERTa
i) Training with dynamic masking:
The original BERT implementation performs masking during data preprocessing, which results in a single static mask. This approach was contrasted with dynamic masking, in which a new masking pattern is created each time a sequence is fed to the model. Dynamic masking was on par with or slightly better than static masking.
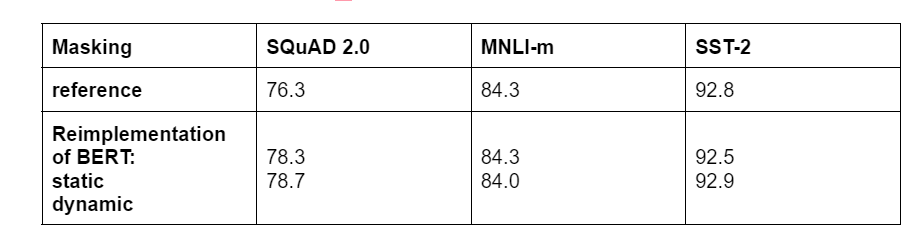
Table 1: Comparison between static and dynamic masking for BERTBASE .
Considering the above results, the dynamic masking approach is employed for pretraining RoBERTa.
ii) FULL-SENTENCES without NSP loss:
Next, training without the NSP loss and training are compared with blocks of text from a single document (doc-sentences). It was found that this setting works better than the originally published BERTBASE results and that dropping off the NSP loss matches or slightly improves downstream task performance.
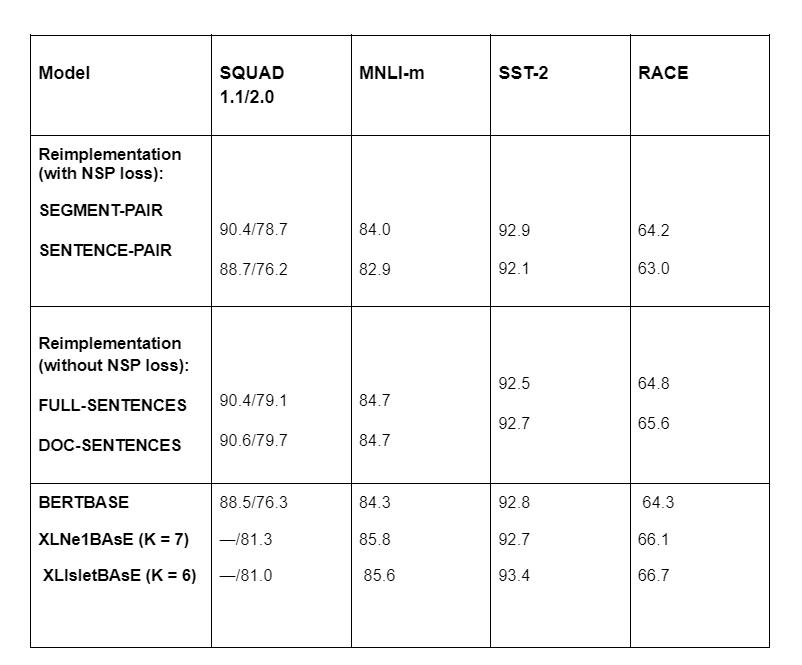 Table 2: Table illustrating the performance of RoBERTa with and without NSP loss
Table 2: Table illustrating the performance of RoBERTa with and without NSP loss
It was noted that restricting sequences that come from a single document (DOC-SENTENCES) performs slightly better than plugging sequences from multiple documents (FULL-SENTENCES). However, since the DOC-SENTENCES format results in variable batch sizes, FULL-SENTENCES are used in RoBERTa for easier comparison.
iii) Training with large batches:
Training with large batch sizes accelerates optimization and increases task accuracy. In addition, distributed data-parallel training makes it easier to parallelize large batches. When the model is tuned properly, large batch sizes can make the model perform better at a given task.
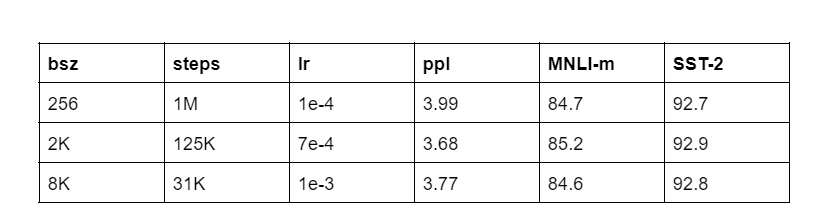
Table 3: Comparison of Performance of the RoBERTa on different tasks with varying Batch Sizes
iv) A larger byte-level BPE:
Byte-pair encoding is a hybrid of character-level and word-level representations that can handle the large vocabularies common in natural language corpora. Instead of using the character-level BPE vocabulary of size 30K used in BERT, RoBERTa uses a larger byte-level BPE vocabulary with 50K subword units (without extra preprocessing or tokenization of the input).
All these findings highlight the importance of previously unexplored design choices in BERT training and help distinguish the relative contributions of data size, training time, and pretraining objectives.
Key Achievements of RoBERTa
RoBERTa model delivered SoTA performance on the MNLI, QNLI, RTE, STS-B, and RACE tasks (back then) and an improved performance gain on the GLUE benchmark. With a score of 88.5, RoBERTa took the top spot on the GLUE leaderboard.
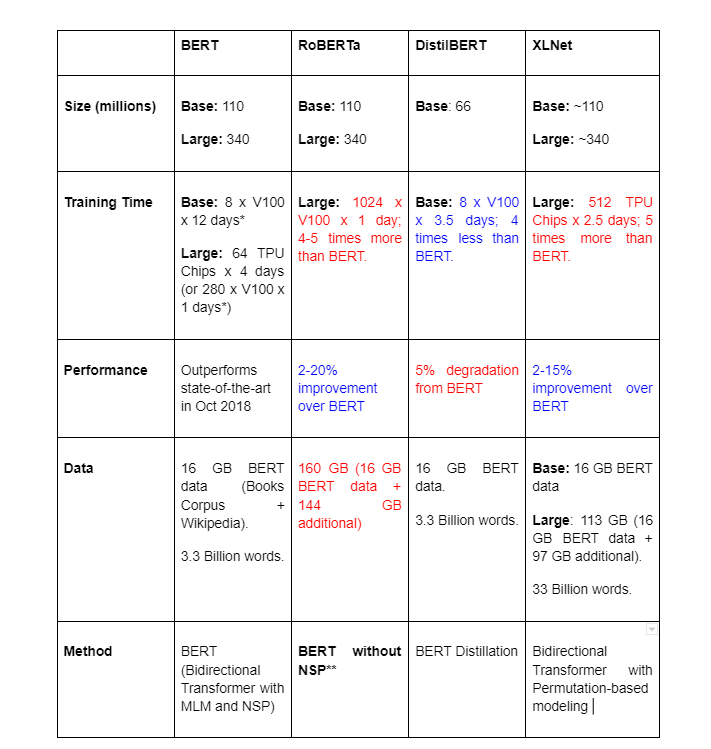
Table 4: Comparison of BERT and successive improvements over it
Drawbacks of RoBERTa
Training such models can be prohibitive and have a large carbon footprint.
Can we Make a Direct Comparison between RoBERTa and XLNeT?
Well, I think this can be best answered with the help of an excerpt straight from (RoBERTa) research paper’s coauthor’s conversation with a Commentor. Myle Ott, a study’s co-author, joined a Reddit comment thread about this research work, providing more context and responding to several queries. One commenter remarked that the comparison with XLNet was not quite “apples-to-apples.” Ott concurred, stating:
“In addition to the differences you already mentioned, XLNet and RoBERTa’s data sizes and composition differ. We ultimately decided against comparing this work directly to XLNet-large since we will need to retrain XLNet on our data.”
How to Use RoBERTa in Projects?
Huggingface’s Transformers library provides a variety of pre-trained RoBERTa models in different model sizes and for different tasks. To provide an example, in this post, we will be focusing on how to load the model and perform emotion classification.
We will need a RoBERTa model fine-tuned on the task-specific dataset for this. So we will use a pre-trained model (“cardiffnlp/twitter-roberta-base-emotion“) from the hub.
We must first install and import all the necessary packages and load the model from RobertaForSequenceClassification (which has a classification head) and tokenizer from RobertaTokenizer.
!pip install -q transformers
#Importing the necessary packages import torch from transformers import RobertaTokenizer, RobertaForSequenceClassification
#Loading the model and tokenizer model_name = "cardiffnlp/twitter-roberta-base-emotion" tokenizer = RobertaTokenizer.from_pretrained(model_name) model = RobertaForSequenceClassification.from_pretrained(model_name)
#Tokenizing the input
inputs = tokenizer("I love my cat", return_tensors="pt")
#Retrieving the logits and using them for predicting the underlying emotion
with torch.no_grad():
logits = model(**inputs).logits
predicted_class_id = logits.argmax().item()
model.config.id2label[predicted_class_id] >> Output: Optimism
The output is “Optimism,” which is right given the pre-defined labels of the classification model we used. We can use another pre-trained model or fine-tune one to get results that output more appropriate labels.
Conclusion
To summarize, in this article, we learned the following:
- The RoBERTa model shares the BERT model’s architecture. It is a reimplementation of BERT with some modifications to the key hyperparameters and tiny embedding tweaks.
- RoBERTa is trained on a massive dataset of over 160GB of uncompressed text instead of the 16GB dataset originally used to train BERT. Moreover, RoBERTa is trained with i) FULL-SENTENCES without NSP loss, ii) dynamic masking, iii) large mini-batches, and iv) a larger byte-level BPE.
- Most performance gains result from better training, more powerful computing, or increased data. While these have value, they often trade off computation efficiency for prediction accuracy. There is a need to develop more sophisticated, capable, and multi-task fine-tuning methods that can improve performance using fewer data and computing power.
- 4. We can not directly compare XLNET and RoBERTa since we will need to train XLNET on data used for training the RoBERTa model.
That concludes this article. Thanks for reading. If you have any questions or concerns, please post them in the comments section below. Happy learning!
Link to Research Paper: https://arxiv.org/pdf/1907.11692.pdf
Link to Original Code: https://github.com/pytorch/fairseq
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I'm a Researcher who works primarily on various Acoustic DL, NLP, and RL tasks. Here, my writing predominantly revolves around topics related to Acoustic DL, NLP, and RL, as well as new emerging technologies. In addition to all of this, I also contribute to open-source projects @Hugging Face.
For work-related queries please contact: [email protected]






