Introduction
All kinds of businesses rely on data for any decision-making; keeping this in mind, knowing that the data set you are working on is of topmost quality is crucial. Bad or poor-quality data can lead to disastrous outcomes. To safeguard against such pitfalls, organizations must be vigilant in identifying and eliminating these data issues. In this article, we present a comprehensive guide to recognize and address 10 common cases of bad data.
Table of contents
What is Bad Data?
Bad data refers to data that does not meet the necessary quality standards for its intended purpose of collection and processing. Raw data obtained directly from various sources, such as social media sites or other methods, often falls into this category due to its initial low quality. To make this data usable and reliable, it requires thorough processing and cleaning to enhance its overall quality.

Why is Data Quality Important?
Data quality is essential for making informed decisions, maintaining trust, reducing costs, satisfying customers, and ensuring compliance. It plays a fundamental role in the success and sustainability of any organization in today’s data-driven world.
- High-quality data ensures that decisions made based on that data are accurate and reliable. Poor data quality can lead to wrong conclusions and potentially disastrous decisions.
- Quality data instills trust in stakeholders, customers, and partners. It enhances the credibility of the organization and its operations.
- Maintaining data quality reduces costs associated with data errors, rework, and fixing mistakes caused by poor data.
- Accurate and reliable data leads to better customer experiences and satisfaction. It enables personalized services and targeted marketing.
- Quality data enhances the efficiency and effectiveness of business processes, leading to improved productivity and performance.
- Many industries have strict regulations regarding data quality. Ensuring data meets these standards is crucial to avoid legal issues and penalties.
- High-quality data forms the foundation for meaningful data analysis, providing valuable insights for strategic planning and business growth.
- Ensuring data quality guarantees that it remains relevant and usable in the long term, preserving its value over time.
- Integration and Interoperability: Good data quality facilitates smooth integration with different systems and promotes application interoperability.
- Data quality is closely linked to data security. Accurate data ensures that sensitive information is appropriately handled and protected.
Top 10 Bad Data Issues and Their Solutions
Here are top 10 poor data issues that you must know about and their potential solutions:
- Inconsistent Data
- Missing Values
- Duplicate Entries
- Outliers
- Unstructured Data
- Data Inaccuracy
- Data Incompleteness
- Data Bias
- Inadequate Data Security
- Data Governance and Quality Management
Inconsistent Data
Inconsistent data refers to data lacking uniformity or coherence within or across different datasets. It can create significant problems, such as inaccurate analysis, unreliable insights, and flawed decision-making. It can lead to confusion, inefficiencies, and hinder the ability to draw meaningful conclusions from the information, impacting overall business operations and outcomes.

Challenges
- Inconsistent data can lead to incorrect conclusions and misinterpreting results during data analysis.
- Data inconsistencies undermine the reliability and trustworthiness of insights derived from the data.
- Poor-quality, inconsistent data can result in misguided decision-making, impacting the success of projects or initiatives.
- It can hinder the smooth integration of data from various sources and systems.
- More time and resources are required to clean and reconcile inconsistent data.
- Stakeholders may lose trust in the data and the organization’s ability to handle information effectively.
Solutions
- Establish clear data quality standards and collection, entry, and storage guidelines.
- Implement validation checks during data entry and import processes to identify and correct errors and inconsistencies.
- Use data integration tools and processes to unify data from different sources and systems, ensuring consistency across the organization.
- Regularly conduct data cleansing and normalization to identify and rectify inconsistencies and inaccuracies in the data.
- Adopt a master data management strategy to create a single, authoritative source of truth for critical data elements, minimizing duplication and inconsistencies.
Also Read: Combating Data Inconsistencies with SQL
Missing Values
Missing data refers to the absence of values or information in a dataset, where certain observations or attributes have not been recorded or are incomplete. This can occur for various reasons, such as data entry errors, technical issues during data collection, survey non-responses, or intentional data omissions.

Challenges
- Missing data can introduce bias into the analysis, leading to skewed conclusions and inaccurate representations of the population under study.
- The absence of data can result in misinterpretation of variable relationships, potentially concealing crucial dependencies and trends.
- Missing values reduce the effective sample size, limiting the usability of size-specific software or functions designed to handle complete datasets.
- It causes a decrease in dataset richness and completeness, leading to a loss of valuable information and insights.
- Incomplete Analysis: Missing values may disrupt data analyses, affecting the ability to draw meaningful conclusions and hindering the validity of statistical inferences.
- It compromises predictive models’ accuracy and reliability, reducing their ability to make accurate forecasts or classifications.
- The presence of missing values may introduce sampling biases, affecting the representation of different subgroups within the dataset.
Solutions
- By using imputation methods to create complete data matrices with estimates generated from mean, median, regression, statistics and machine learning models. One can use single or multiple imputations.
- Analyze the pattern of missing data, which may lie in different types, such as: Missing Completely at Random (MCAR), Missing at Random (MAR) or Missing Not at Random (MNAR).
- Use weighting techniques to identify the impact of missing values on the analysis.
- Adding more data may fill in the missing values or minimize the impact.
- Focus on the issue in the beginning to avoid bias.
Duplicate Entries
Duplicate entries refer to instances in a dataset where identical or nearly identical records exist for a given entity. These duplicates can arise due to data entry errors, system glitches, data migration processes, or merge operations.
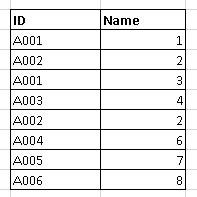
Challenges
- Duplicate data can distort statistical measures, leading to inaccurate data analysis and affecting the reliability of insights.
- They can cause overestimation or underestimation of attributes, leading to erroneous conclusions.
- It undermines data integrity, resulting in a loss of accuracy and reliability in the dataset.
- Duplicate entries increase storage requirements, leading to unnecessary costs and wastage of resources.
- Handling duplicate data increases the processing load on systems, impacting the efficiency of data processing and analysis.
- Managing and organizing duplicate data requires additional effort and resources for data maintenance and quality control.
Solutions
- Input or set a unique identifier to prevent or easily recognize duplicate entries.
- Introduce data constraints to ensure data integrity.
- Perform regular data audits.
- Utilize fuzzy matching algorithms for the identification of duplicates with slight variations.
- Hashing helps in the identification of duplicate records through labeling.
Outliers
Outliers are extreme values or observations seen lying far away from the main dataset. Their intensity can be large or small and may be rarely seen in data. The reason for their occurrence is data entry mistakes and measurement errors accompanied by genuine extreme events in data.

Significance
- Outliers can significantly impact statistical measures and lead to skewed data analysis, misinterpreting results.
- It can lead to misleading insights, as they may not represent the typical behavior of the data and can distort patterns and trends.
- It can adversely affect the performance of predictive models, leading to less accurate and reliable predictions.
- It can complicate data normalization techniques, making it challenging to scale data appropriately.
- It can disproportionately influence the calculation of measures like mean and median, leading to inaccurate central tendency representation.
- Distinguishing between genuine anomalies and outliers can be difficult, affecting the effectiveness of anomaly detection systems.
- They can distort data visualizations, making it harder to understand patterns and relationships in the data.
Solutions
- State a specific threshold value according to domain knowledge pr statistical method.
- Truncate or cap extreme values to reduce the impact of outliers.
- Apply logarithmic or square root transformations.
- Use robust regression or tree-based models.
- Remove the values with careful consideration if they pose an extreme challenge.
Unstructured Data
Unstructured data refers to data that needs a predefined structure or organization, presenting challenges to analysis. It arises from various sources, such as changes in document formats, web scraping, the absence of a fixed data model, and data collected from digital and analog sources using different techniques. Handling unstructured data requires specialized approaches to extract valuable insights and meaningful patterns from this diverse and dynamic information landscape.

Challenges
- Unstructured data lacks a predefined format, making applying traditional analysis methods challenging.
- It is often highly dimensional, containing multiple features and attributes, making it complex to handle and analyze.
- It can come in diverse formats, languages, and encoding standards, complicating data integration efforts.
- Extracting valuable information from unstructured data requires specialized techniques such as Natural Language Processing (NLP), audio processing, or computer vision.
- It leads to a lack of accuracy and verifiability, creating difficulties in integration and generating irrelevant or incorrect information.
- Storing and processing unstructured data can be resource-intensive, requiring scalable infrastructure to handle large volumes of diverse data sources.
Solution
- Use metadata for additional information for efficient analysis and integration.
- Create ontologies and taxonomies for a better understanding.
- Process images and videos through computer vision for feature extraction and object recognition.
- Implement audio processing techniques for transcription, noise and irrelevant content removal.
- Use advanced techniques for processing and information extraction from textual data.
Data Inaccuracy
Data inaccuracy refers to errors, mistakes, or inconsistencies in a dataset, rendering the information unreliable and incorrect. Inaccuracies can stem from various sources, such as data entry errors, technical glitches, data integration issues, or outdated information. These inaccuracies can lead to flawed analysis, misguided decision-making, and unreliable insights. Data accuracy is essential to ensure the credibility and trustworthiness of information, especially in data-driven environments where organizations heavily rely on data for strategic planning, business operations, and customer interactions. Regular data quality checks and validation processes are vital to identify and rectify inaccuracies and maintain the overall integrity of the data.

Challenges
- Inaccurate data can lead to flawed decisions and strategies, impacting the overall success of an organization.
- It can result in unreliable insights and misinterpretation of trends and patterns.
- It leads to poor customer experiences, damaging trust and satisfaction.
- It can result in non-compliance with regulations and legal requirements.
- Addressing inaccuracies requires time and resources, leading to inefficiencies and increased costs.
- Inaccurate data can cause challenges in integrating information from different sources, affecting data consistency and reliability.
Solution
- Data cleaning and validation (most important)
- Automated data quality tools
- Validations rules and business logic
- Standardization
- Error reporting and logging added
Data Incompleteness
The absence of attributes crucial for analysis, decision-making and understanding is referred to as missing key attributes. These generate due to data entry errors, incomplete data collection, data processing issues or intentional data omission. The absence of complete data plays a key role in disrupting comprehensive analysis, evidenced by multiple issues faced in its presence.

Challenges
- It leads to problems in detecting meaningful patterns and relationships within data.
- The results lack valuable information and insights due to defective data.
- The development of bias and problems with sampling is common due to the non-random distribution of missing data.
- Incomplete data leads to biased statistical analysis and inaccurate parameter estimation.
- Key impact is seen in the performance of machine learning models and predictions.
- Incomplete data results in miscommunication of results to stakeholders.
Solutions
- Collect more data to easily fill in the gaps in poor data.
- Recognise the missing information through indicators and handle it efficiently without compromising the process and result.
- Look for the impact of missing data on analysis outcomes.
- Find out the errors or shortcomings in the data collection process to optimize them.
- Perform regular audits to look for errors in the process of data collection and collected data.
Data Bias
Data bias is the presence of systematic errors or prejudice in a dataset leading to inaccuracy or generation of results inclined toward one group. It may occur at any stage, such as data collection, processing or analysis.

Challenges
- Data bias leads to skewed analysis and conclusions.
- Generates ethical concerns when decisions are in favor of a person, community or product or service, helping them.
- Biased data leads to unreliable predictive models and inaccurate forecasts.
- It impacts the process of generalizing the findings leading to a broader population.
Solution
- Use bias metrics for tracking and monitoring bias in the data.
- Do add data from diverse groups to avoid systematic exclusion.
- Implement ML algorithms capable of bias reduction.
- Perform it to assess the impact of data bias on analysis outcomes.
- Audit and conduct data profiling regularly.
- Clearly and precisely document the data for transparency and to easily address the biases.
Inadequate Data Security
Inadequate data security refers to insufficient measures and safeguards to protect sensitive and valuable data from unauthorized access, theft, or breaches. It occurs when organizations fail to implement proper security protocols, encryption, access controls, or keep their software and systems up-to-date. Inadequate data security can lead to data breaches, data loss, identity theft, financial fraud, and reputational damage. Organizations must prioritize data security and proactively protect their data from threats and cyberattacks.

Challenges
- Inadequate data security leaves data vulnerable to breaches, making it essential to identify and address potential weak points in the system.
- Sophisticated cyber attacks demand advanced and efficient management techniques to effectively detect and prevent security breaches.
- Ensuring data security while complying with evolving data protection laws and regulations poses complex challenges for organizations.
- It requires educating each staff member about cybersecurity best practices to mitigate the risk of human errors and insider threats.
- It can lead to financial losses from data breaches, legal penalties, and reputational damage.
- Data breaches due to inadequate security erode customer trust, leading to a loss of clientele and potential business opportunities.
Solutions
- Requires encryption of sensitive data at rest and in transit for protection from unauthorized access.
- Implement strictly controlled access for the employees based on their roles and requirement.
- Deploy security measures with built-in firewalls and installation of IDS.
- Put in the multi-factor authentication for additional security.
- Take data backup it mitigates the impact of cyber attacks.
- Assess and enforce data security standards for third-party vendors.
Data Governance and Quality Management
Data governance concerns policy, procedure and guideline establishment to ensure data integrity, security and compliance. Whereas, data quality management deals with processes and techniques to improve, assess and maintain the accuracy, consistency and completeness of poor data for reliability enhancement.

Challenges
- Fragmented data makes it challenging to integrate and maintain consistency across the organization.
- Balancing data sharing and privacy while handling sensitive information poses significant challenges.
- Gaining buy-in and alignment for data governance initiatives can be complex, especially in large organizations with diverse stakeholders.
- Identifying and establishing clear data ownership can be challenging, leading to potential data management conflicts.
- Transitioning from ad-hoc data practices to a mature data governance framework requires time and concerted efforts to ensure effectiveness and sustainability.
Solutions
- It includes profiling, cleansing, standardization, data validation and auditing.
- Automate the process of validation and cleansing.
- Regularly monitor data quality and simultaneously address the issues.
- Create a mechanism such as forms or ‘raise a query’ option for reporting data quality issues and suggestions.
Conclusion
Recognizing and addressing poor data is essential for any data-driven organization. By understanding the common cases of poor data quality, businesses can take proactive measures to ensure the accuracy and reliability of their data. Analytics Vidhya’s Blackbelt program offers a comprehensive learning experience, equipping data professionals with the skills and knowledge to tackle data challenges effectively. Enroll in the program today and empower yourself to become a proficient data analyst capable of navigating the complexities of data to drive informed decisions and achieve remarkable success in the data-driven world.
Frequently Asked Questions
Q1. What are the 4 data quality issues?
A. The four common data quality issues seen in wrong data are the presence of inaccurate, incomplete, duplicate and outdated data.
Q2. What are the factors that can cause poor data quality?
A. The factors responsible for poor data quality are incomplete data collection, lack of data validation, data integration issues and data entry errors.
Q3. What does bad data look like?
A. Bad data is seen to comprise duplicate entries, missing values, outliers, contradictory information and other such presence.
Q5. What are the 5 characteristics of data quality?
A. The five characteristics of data quality are accuracy, completeness, consistency, timeliness and relevance.



