Some people want to “learn AI.” Others want to build the future. If you’re in the second category, bookmark this right now – because the Generative AI Scientist Roadmap 2026 isn’t another cute syllabus. It’s the no-nonsense, industry-level blueprint for turning you from “I know Python loops” into “I can architect agents that run companies.” This is the stuff Big Tech won’t spoon-feed you but expects you to magically know in interviews.
The truth is, AI mastery isn’t one skill. It’s seven evolving worlds. Data, transformers, prompting, RAG, agents, fine-tuning, ops – each one a boss level. So instead of drowning in 10 random courses, here’s the only roadmap built for 2026 and beyond: step-by-step, skill-by-skill, project-by-project. No fluff or filler. This Generative AI Scientist Roadmap 2026 is the exact upgrade path to go from being a user to a builder to an architect to a leader.
Table of contents
- Phase 1: The Data Foundation (Weeks 1-6)
- Phase 2: The Brain – ML, DL, & Transformers (Weeks 7-14)
- Phase 3: The Operator – LLMs & Prompting (Weeks 15-18)
- Phase 4: The Builder – RAG & Graph RAG (Weeks 19-24)
- Phase 5: The Commander – Agents & Agentic RAG (Weeks 25-32)
- Phase 6: The Tuner – Fine-tuning (Weeks 33-38)
- Phase 7: The Engineer – LLMOps and AgentOps (Weeks 39-42)
- Conclusion
Phase 1: The Data Foundation (Weeks 1-6)
Goal: Speak the language of data. You cannot build AI if you cannot manipulate the data it feeds on.

Python (The AI Dialect):
Expert Addition: Learn AsyncIO. Modern GenAI is asynchronous (streaming tokens). If you don’t know async/await, your apps will be slow.
Checkout: A Complete Python Tutorial to Learn Data Science from Scratch
SQL (The Data Fetcher):
- Master the fundamentals: Learn SELECT, WHERE, ORDER BY, and LIMIT to fetch and filter data efficiently.
- Work with tables: Use JOIN to combine datasets and perform basics like INSERT, UPDATE, and DELETE.
- Summarize and transform: Apply GROUP BY, aggregates, CASE WHEN, and simple string/date functions.
- Write cleaner queries: Avoid SELECT *, use proper filters, and know basic indexing principles.
Expert Addition: Learn pgvector. Standard SQL is for text; pgvector (PostgreSQL) is for vector similarity search, which is the backbone of RAG.
Get started here: SQL: A Full Fledged Guide from Basics to Advance Level
Data Preprocessing:
- Convert raw data into a usable format for model training.
- Key Steps Include:
- Cleaning: Handling missing values, noise, and text hygiene.
- Transformation: Scaling, encoding categorical data, and normalization.
- Engineering: Creating new, meaningful features from existing ones.
- Reduction: Reducing complexity via dimensionality techniques.
- Purpose: Ensures high-quality input for reliable model performance.
Full guide: Practical Guide on Data Preprocessing in Python using Scikit Learn
Phase 2: The Brain – ML, DL, & Transformers (Weeks 7-14)
Goal: Understand how the magic works so you can debug it when it breaks.
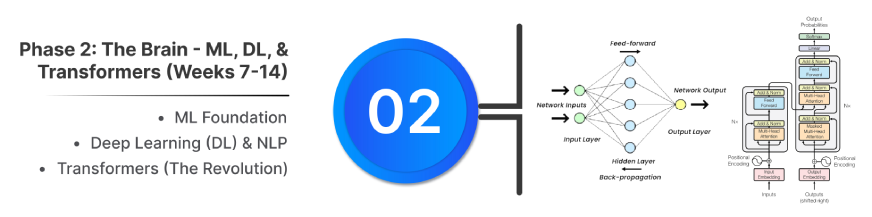
ML Foundation:
- Supervised vs. Unsupervised learning.
- Overfitting vs. Underfitting.
- Key Math: Gradient Descent (how models learn) and Loss Functions.
Also Read: Beginner’s Guide to Machine Learning Concepts and Techniques
Deep Learning (DL) & NLP:
- ANN (Foundational Model): Network of connected neurons using weights and activation functions (ReLU, Softmax, etc.).
- Sequential Networks (Memory):
- Traditional Text Representation:
- Bag-of-Words (BoW): Counts word frequency, ignoring order/grammar.
- TF-IDF: Weights word importance by document frequency vs. corpus rarity.
- Embeddings: Dense vectors that capture semantic meaning and relationships (e.g., $King – Man + Woman \approx Queen$).
Checkout: Free course on NLP and DL basis
Transformers (The Revolution):
- Foundation: Based on the 2017 paper “Attention Is All You Need.” It is the core of modern LLMs (GPT, Llama).
- Core Innovation: Self-Attention Mechanism. This allows the model to process all tokens in parallel, assigning a weighted importance to every word to capture long-range dependencies and context resolution efficiently.
- Structure: Uses Multi-Head Attention and Feed-Forward Networks within an Encoder-Decoder or Decoder-only stack.
- Key Enabler: Positional Encoding ensures the model retains word order information despite parallel processing.
- Revolutionary: Enables faster training and better handling of long text sequences than previous architectures (RNNs).
Expert Addition: Understand “Context Window” limits and “KV Cache” (how LLMs remember previous tokens efficiently).
Also Read: Guide to Transformers
Phase 3: The Operator – LLMs & Prompting (Weeks 15-18)
Goal: Master the current state-of-the-art models in this step of the Generative AI Scientist Roadmap 2026.

LLM Literacy
Expert Addition: Learn about Inference Providers like Groq (super fast) and OpenRouter (access to all models via one API).
Prompt Engineering:
- Zero-Shot: Request the task directly from the model without any preceding examples (ideal for simple, well-known tasks).
- Few-Shot: Enhance accuracy and formatting by providing the model with 2-5 input-output examples within the prompt.
- Chain-of-Thought (CoT): Instruct the model to “think step-by-step” before answering, significantly improving accuracy in complex reasoning tasks.
- Tree-of-Thought (ToT): A sophisticated method where the model explores and evaluates multiple possible reasoning paths simultaneously before selecting the optimal solution (best for strategic or creative planning).
- Self-Correction: Force the model to review and revise its own output against specified constraints or requirements to ensure higher reliability and adherence to rules.
Expert Addition: System Prompting- Use a high-priority, invisible instruction set to define the model’s persona, persistent rules, and safety boundaries, which is crucial for consistent tone and preventing undesirable behavior.
Also Read: Guide to Prompt Engineering
Phase 4: The Builder – RAG & Graph RAG (Weeks 19-24)
Goal: Stop hallucinations. Make the AI “know” your private data.

RAG (Retrieval Augmented Generation)
RAG is a core technique for grounding LLMs in external, up-to-date, or private data, drastically reducing hallucinations. It involves retrieving relevant documents or chunks from a knowledge source and feeding them into the LLM’s context window along with the user’s query.
To make this entire process work end-to-end, a set of supporting components ties the RAG pipeline together.
- Orchestration Framework (LangChain & LlamaIndex): These frameworks are used to glue together the entire RAG pipeline. They handle the full data lifecycle – from loading documents and splitting text to querying the Vector Database and feeding the final context to the LLM. LangChain is known for its wide range of general tools and chains, while LlamaIndex specializes in data ingestion and indexing strategies, making it highly optimized for complex RAG workflows.
- Vector Databases: Specialized databases like ChromaDB (local), Pinecone (scalable cloud solution), Milvus (high-scale open-source), Weaviate (hybrid search), or Qdrant (high-performance) store your documents as numerical representations called embeddings.
- Retrieval Mechanism: The primary method is Cosine Similarity search, which measures the “closeness” between the query’s embedding and the document embeddings.
- Expert Addition: Hybrid Search: For best results, rely on Hybrid Search. This combines Vector Search(semantic meaning) with Keyword Search (BM25) (term frequency/exact matches) to ensure both conceptual relevance and necessary keywords are retrieved.
Graph RAG
Graph RAG (The 2026 Standard): As data complexity grows, RAG evolves into systems that understand relationships, not just similarity. Agentic RAG and Graph RAG are crucial for complex, multi-hop reasoning.
- Graph RAG (The 2026 Standard): This technique moves beyond vectors to find connected things rather than just similar things.
- Concept: It extracts entities (e.g., people, places) and relationships (e.g., WORKS_FOR, LOCATED_IN) to build a Knowledge Graph.
- Tool: Graph databases like Neo4j are used to store and query these relationships, allowing the LLM to answer complex, relational questions like, “How are these two companies connected?”
Also Read: How to Become a RAG Specialist in 2026?
Phase 5: The Commander – Agents & Agentic RAG (Weeks 25-32)
Goal: Move from “Chatbots” (passive) to “Agents” (active doers).
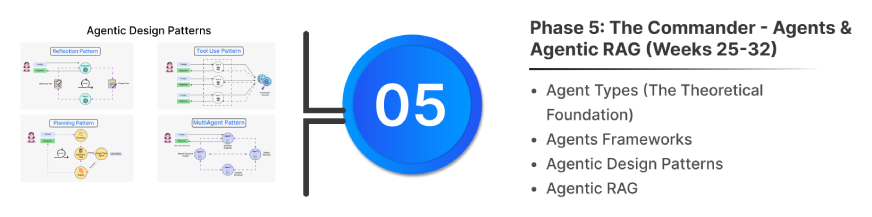
Agent Types (The Theoretical Foundation):
These classifications represent how intelligent an agent can be and how complex its decision-making becomes. While Simple Reflex, Model-Based Reflex, Goal-Based, and Utility-Based Agents form the foundational categories, the following types are now becoming increasingly popular:
- Learning Agents: Improves its performance over time by learning from experience and feedback, adapting its behavior and knowledge.
- Hierarchical Agents: Organized in a multi-level structure where higher-level agents delegate tasks and guide lower-level agents, enabling efficient problem-solving.
- Multi-Agent Systems: A computational framework composed of multiple interacting autonomous agents (like CrewAI or AutoGen) that collaborate or compete to solve complex tasks.
Also Read: Guide to Types of AI Agents
Agents Frameworks
- LangGraph (The State Machine):
- Focus: Mandatory for 2026. Enables complex loops, cycles, and conditional branching with explicit state management.
- Best Use: Production-grade agents requiring reflection, retries, and deterministic control flow (e.g., advanced RAG, dynamic planning).
- Allows an agent to check its work and decide to repeat or branch to a new step.
- CrewAI (The Team Manager):
- Focus: High-level abstraction for building intuitive multi-agent systems based on defined roles, goals, and backstories.
- Best Use: Projects that naturally map to a human team structure (e.g., Researcher to Writer to Critic).
- Excellent for quick, collaborative, and role-based agent design.
- AutoGen (The Conversation Designer):
- Focus: Building dynamic, conversational multi-agent systems where agents communicate via flexible messages.
- Best Use: Collaborative coding, debugging, and iterative research workflows that require self-evolving dialogue or human-in-the-loop oversight.
- Ideal for peer-review style tasks where the workflow adapts based on the agents’ interaction.
Also Read: Top 7 Frameworks for Building AI Agent
Agentic Design Patterns
These are the established best practices for building robust, intelligent agents:
- ReAct Pattern (Reasoning + Action): The fundamental pattern where the agent interleaves Thought (Reasoning), Action (Tool Call), and Observation (Tool Result).
- Multi-Agent Pattern: Designing a system where specialized agents cooperate to solve a complex problem using distinct roles and communication protocols.
- Tool Calling / Function Calling: The agent’s ability to decide when and how to call external functions (like a calculator or API).
- Reflection / Self-Correction: The agent generates an output, then uses a separate internal prompt to critically evaluate its own result before presenting the final answer.
- Planning / Decomposition: The agent first breaks the high-level goal into smaller, manageable sub-tasks before executing any actions.
Checkout: Top Agentic AI Design Patterns for Architecting AI Systems
Agentic RAG:
- Definition: RAG enhanced by an autonomous AI agent that plans, acts, and reflects on the user query.
- Workflow: The agent decomposes the question into sub-tasks, selects the best tool (Vector Search, Web API) for each part, and iteratively refines the results.
- Impact: Solves complex queries by being dynamic and proactive, moving beyond passive, linear retrieval.
Phase 6: The Tuner – Fine-tuning (Weeks 33-38)
Goal: When prompting isn’t enough, change the model’s brain.
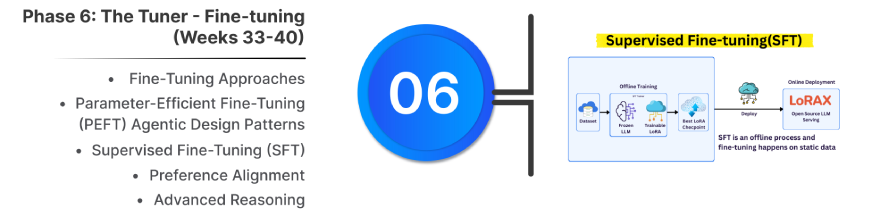
Fine-tuning adapts a pre-trained model to a specific domain, persona, or task by training it on a curated dataset.
1. Fine-Tuning Approaches
- LLMs (70B+): Used to inject proprietary knowledge or improve complex reasoning; requires strong compute.
- SLMs (1–8B): Tuned for specialized, production-ready tasks where small models can outperform large ones on narrow use cases.
2. Parameter-Efficient Fine-Tuning (PEFT)
- PEFT: Trains small adapter layers instead of the whole model.
- LoRA: Industry standard; uses low-rank matrices to cut compute and memory.
- QLoRA: Further reduces memory by 4-bit quantization of frozen weights.
3. Supervised Fine-Tuning (SFT)
- Teaches new behaviors using (prompt, ideal response) pairs. High-quality, clean data is essential.
4. Preference Alignment
Refines model behavior after SFT using human feedback.
- DPO: Optimizes directly on preferred vs. rejected responses; simple and stable.
- ORPO: Combines SFT + preference loss for better results.
- RLHF + PPO: Traditional RL-based approach using reward models.
5. Advanced Reasoning
GRPO: Improves multi-step reasoning and logical consistency.
Phase 7: The Engineer – LLMOps and AgentOps (Weeks 39-42)
Goal: Move from “It works on my laptop” to “It works for 10,000 users.” Transition from writing scripts to building robust, scalable systems.

Deployment & Efficient Serving
- The API Layer: Don’t just run a Python script. Wrap your agent logic in a high-performance, asynchronous web framework using FastAPI. This allows your agent to handle concurrent requests and integrate easily with frontends.
- Inference Engines: Standard Hugging Face pipelines can be slow. For production, switch to optimized inference servers:
- vLLM: Use this for high-throughput production environments. It utilizes PagedAttention to drastically increase speed and manage memory efficiently.
- llama.cpp: Use this for running quantized models (GGUF) on consumer hardware or edge devices with limited VRAM.
Observability (The “Black Box” Problem)
- You cannot debug an Agent with print() statements. You need to visualize the entire chain of thought.
- Tools: Integrate LangSmith, LangFuse, or Arize Phoenix.
- What to track: View the “trace” of every decision, inspect intermediate inputs/outputs, identify where the agent entered a loop, and debug latency spikes.
Evaluation (LLM-as-a-Judge)
- Stop relying on “vibe checks” or eyeballing the output. Treat your prompts like code.
- Frameworks: Use RAGAS or DeepEval to build a testing pipeline.
- Metrics: Automatically score your application on “Faithfulness” (did it make things up?), “Context Recall” (did it find the right document?), and “Answer Relevance.”
Cost & Governance
- Token Management: Track usage per user and per session to calculate unit economics.
- Guardrails: Implement basic safety checks to prevent the agent from going off-topic or generating harmful content before the cost is incurred.
The “Fast Track” Milestone Projects
To stay motivated, build these 4 projects as you progress:
- Project Alpha (After Phase 3): A Python script that summarizes YouTube videos using the Gemini API.
- Project Beta (After Phase 4): A “Chat with your Finance PDF” tool using RAG and ChromaDB.
- Project Gamma (After Phase 5): An Autonomous Researcher Agent using LangGraph that browses the web and writes a blog post.
- Capstone (After Phase 7): A specialized Medical/Legal Assistant powered by Graph RAG, fine-tuned on domain data, with full LangSmith monitoring.
Conclusion
If you follow this roadmap with even 70% seriousness, you won’t just “learn AI,” you’ll outgrow 90% of the industry sleepwalking through outdated tutorials. The Generative AI Scientist Roadmap 2026 is designed to turn you into the kind of builder companies fight to hire, founders want to partner with, and investors quietly scout for.
Because the future isn’t going to be written by people who merely use AI. It will be built by those who understand data, command models, architect agents, fine-tune brains, and ship systems that actually scale. With the Generative AI Scientist Roadmap 2026, you now have the blueprint. The only thing left is the part no roadmap can teach, showing up every single day and levelling up like you mean it.
Data Analyst with over 2 years of experience in leveraging data insights to drive informed decisions. Passionate about solving complex problems and exploring new trends in analytics. When not diving deep into data, I enjoy playing chess, singing, and writing shayari.






