Overview
- Geospatial data is goldmine right now and kepler.gl is a wonderful Python library for visualizing this geospatial data
- Learn how to use kpler.gl, how to visualize geospatial data, and go through a real-world case study here
Introduction
Check out this aesthetically pleasing 3D geospatial map of New York created entirely in a Jupyter Notebook using Python:
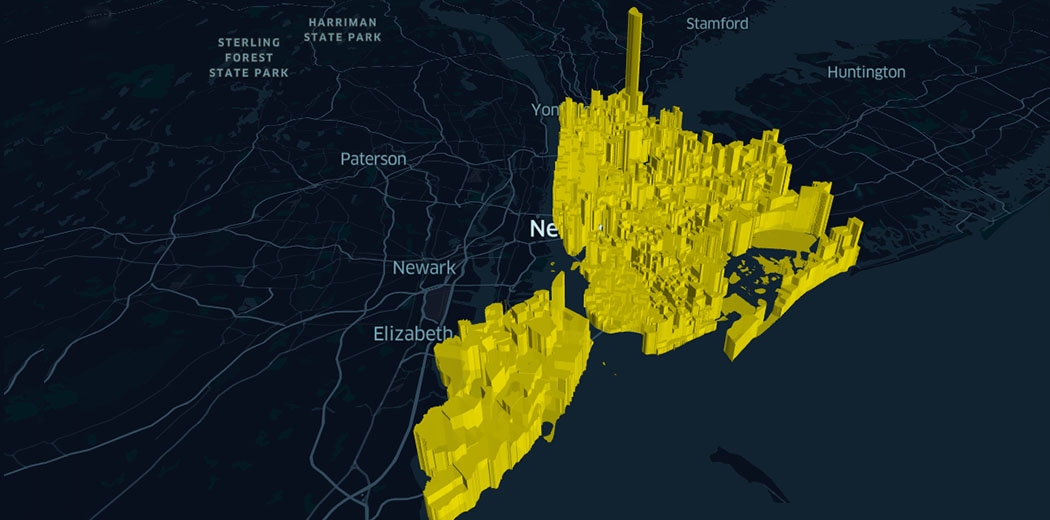
A wonderful visualization! I especially like the lines around the city and how they intertwine and present a very accurate image of how the map of city actually looks. Analyzing geospatial data in Jupyter notebooks is one of my favorite projects and I had a blast creating this for our community.
There are so many applications of working with geospatial data – location tracking, location-based marketing, and advertising, connecting you to the nearest rider or delivery person (you know what I’m talking about!), among other use cases. The sky is the limit as far as utilizing geospatial data is concerned. In fact, this field is really starting to gain prominence in the industry so the best time to learn about it is now.
Here, we’ll learn how to visualize geospatial data using a Python library called kepler.gl. It’s a powerful tool for working with geospatial data as we’ll soon see. We will, of course, apply kepler.gl on a dataset to give you an idea of how you can implement it.
Table of Contents
- What is kepler.gl for Geospatial Analysis?
- Installing kepler.gl on your Machine
- Visualizing Taxi Trips in New York City
- Visualizing Census Tracts of New York City
- Saving the Maps
What is kepler.gl for Geospatial Analysis?
Have you heard of the word ‘kepler’ before? It might sound familiar to a lot of you and you might be thinking of this:

Or him:

You’re right on either count but our kepler.gl is neither of them. This is a Python library for visualizing geospatial data in Jupyter notebooks!

Kepler.gl is a high-performance web-based tool created by the Uber’s Visualization Team for visual exploration of large scale geospatial datasets.
It is built on top of deck.gl – another framework for visual exploratory data analysis of large datasets by Uber. The most amazing thing about kepler.gl is that it can also be used inside our Jupyter notebook, which makes it a handy tool for everyone in the data science community.
It is my go-to tool for geospatial data visualization, and I’m sure it will be yours too after reading this article. And yes, we’ll create the visualization we saw in the introduction section. So let’s get going!
Installing kepler.gl on your Machine
Kepler.gl does not come installed by default. Therefore, you have to install it manually on your machine. Installing it is similar to any other Python library – just run the following command:
!pip install keplergl
That’s it! You’re now all set to dive into the world of geospatial visualizations.
Visualizing Taxi Trips in New York City using kepler.gl
Understanding the Problem Statement
Problem Statement: Taxis are a vital part of New York City. Everyday many people use it to move around the city. Therefore, it is important to visualize these trips for further analysis.
So, we have to visualize the taxi trips in New York, and you know what? Kepler.gl is just perfect for this task.
Data Description
We know our end goal, but we will not reach there without data, so let’s understand the dataset we have. The data includes taxi records for 15 January 2015 taken from here. Let’s import our dataset and take a look at it:
import pandas as pd
df=pd.read_csv('data.csv')
print('Shape=>',df.shape)
print(df.head())
The dataset contains 12 columns and 97,000+ rows. Let’s see the columns we have in our dataset:

Our dataset includes features such as taxi pickup and dropoff time, latitude, longitude, trip distance, fare, tip, passenger count, and total amount paid to the driver. Now, let’s check if our dataset contains any null values:

Great! We do not have any null values in our dataset. We are now ready to visualize this data.
Plotting base map and adding the dataset
Now we know about the dataset, so let’s start working with kepler.gl. For creating maps using kepler.gl, we first have to create a map object using KeplerGl() class. This can take 3 arguments – height (optional), data (optional) and config (optional). The height is the height of the kepler.gl widget, data is the data to be added to the map, and config is the configuration file of kepler.gl map:
Great! It’s time to add data to this. Data can be added to a kepler.gl map by using the add_data() method of the map object. This method takes two arguments – data and name. It accepts data as CSV, GeoJSON, Pandas, and geopandas dataframe. The name argument is used for assigning the name to the dataset in the configuration of the map:
You see how easy it is to add data to the map. And a fantastic aspect of kepler.gl is that it automatically identifies the patterns in the dataset and creates plots for it. If you noticed, there are many controls on the left side of the map. We’ll look at each one of them in the next section.
Customizing Maps in kepler.gl
We had to write some code for creating the map and adding data to it, but now we don’t have to write a single line of code for creating visualizations and performing data analysis. That makes it the most beginner-friendly visualization tool out there.
There are a total of four things that you need to know about for customizing maps and performing data analysis:
- Layers
- Filters
- Interactions
- Base map
Layers
Let’s start by understanding the layers section. The layers section contains options to modify the layers. Now, you might be wondering what a layer is? Well, a layer in the kepler map is a layer of visualization that can be created, modified, and deleted according to the use case. Below I have demonstrated how you can modify a layer.
Kepler provides many types of layers that you can create for data analysis. You can read more about them here.
You just saw how easy it is to modify the layers. You’ll later see that how easy it is to work with other features of kepler.gl. Now you know how to modify layers, let’s understand about filters.
Filters
As you might have already guessed, filters are used for filtering the data, and that’s exactly why this feature exists. Many times during the data analysis process, we have to filter our dataset to gain insights from it. Below I have filtered the pickup locations based on the trip distance.
You can see above that I have created a window of 5 miles and filtered the taxi pickup points according to it. There are many other types of filters that you can use based on the column selected for filtering the data.
Interactions
Interactions panel is used for modifying the interaction between the mouse pointer and map. You can use it to modify the tooltip, add geocoder to the map, add brush for selecting a part of the map and get coordinates for the location of the mouse pointer in latitude and longitudes.
In the above video, I have modified the tooltip and also used other features of interactions panel. These are very helpful in the scenarios when you want to show more information with the movement of the cursor on the map. Now let’s check out the base map tab.
Base map
The base map tab has options to modify the base map. But what is a base map?
A base map is a map present at the base of all the layers in kepler.gl. Remember when we created our map object and visualized it earlier? That is the base map. The base map is very helpful in representing the information. They also add beauty to the visualizations built on top of it:
You can see above how the color of the base map can set our visualization apart. You can not only change the base map but also modify the elements of a base map. My favorite base maps are dark and light because they help in setting the contrast.
In reality, the choice of base map totally depends on the visualization that we are creating.
If you noticed in the previous videos, there is a 5th tab too. That’s the config tab that contains the configuration of the kepler map.

This configuration is used for reproducing the kepler.gl maps. One thing you need to keep in mind that the name of data added should remain the same, which is “New York City Taxi Trips” in this case. Since you now know about controls and terminologies of kepler.gl, let’s jump to the next section in which we’ll create some beautiful visualizations and experience the power of kepler.gl.
Visualizing the Taxi Trips using kepler.gl
In terms of visualization, kepler.gl has already made our task easier by finding some patterns in the data and creating visualizations for it. You can see this in the video below. It has already plotted the pickup and dropoff points of the trips on the map. Also, it has visualized the trips using layers of arcs and lines:
I deleted the lines layer because it didn’t look appealing compared to arcs. In the above video, we saw that initially, the arcs didn’t look informative. But everything turned upside down when we saw it in 3D. That’s why I love kepler.gl, it allows you to create visualizations in 3D without writing any piece of code.
Also, if you noticed, there was one arc going very far away from the New York City. It was an outlier that wouldn’t have been revealed if we hadn’t used Kepler. Therefore, geospatial visualizations are essential. They can reveal certain aspects of data that can’t be revealed in the tabular form.
And, the feature of having separate colors for source and target of arcs not just made our arcs more explanatory but also acted as a cherry on top of the cake. Our visualization now looks so beautiful that I can use it as my screensaver right now!
One more thing – the interaction brush allowed us to take a look at the trips taken from a specific area of New York, which can help us in identifying the busiest areas of the city.
But wait! All these visualizations are identified and created by kepler.gl. We haven’t created something yet, so let’s rectify that. A good visualization that I can think of would be a heatmap of pickup locations, which will give us information about the locations where people had their pick-ups.
Creating a heatmap is also easy in kepler.gl. These are the following steps that we need to follow to create a heatmap of pickup locations:
- Add new layer
- Select type as a heatmap
- Select columns containing latitude and longitude of pickup locations
- Select the color palette for heatmap
- Select the radius size of data points
- Tweak other parameters
Great! We have successfully created our heatmap. But there is a catch here – since the data was collected at different timestamps throughout the day, our heatmap shows all the pickup locations on that day. We can add more granularity to our map by using filters.
Here, I used filters and selected the column containing the timestamp of pickups for filtering the dataset. And, now we can look at the heatmap of pickup locations at different instances of that day. This visualization gives us information about the busiest parts of the new york city at different hours of the day.
In the next section, we’ll create the same visualization that you saw in the introduction.
Visualizing the Census Tracts of New York City using kepler.gl
Understanding the Problem
Problem Statement: Census tracts are the geographic regions defined for the purpose of taking a census. Visualizing them can provide us information about the distribution of population throughout New York City.
The problem statement is pretty straightforward. We just have to create a visualization that can demonstrate the distribution of population throughout New York City. A 3D map showing the census tracts is perfect for this purpose. So let’s create one.
Data Description
We will be working with a dataset containing the 2010 census tract map combined with population data of New York City taken from here.
The dataset chosen is in the GeoJSON format. GeoJSON is a format based on the JavaScript Object Notation (JSON) format used for encoding a variety of geometric features. It uses various geometric types like Point, LineString, Polygon, MultiPoint, and others.
Since our dataset is in a different format this time, therefore we’ll use a different library for handling this dataset. We’ll use geopandas for this.
Geopandas is a Python library that makes working with geospatial data in python easier. Geopandas combines various top-notch libraries like numpy, shapely, fiona, geopy, descartes, matplotlib, and Pandas obviously. If you know how to use Pandas then you won’t face any problems while using it.
So, let’s import the libraries and take a look at our dataset:

Our dataset contains information such as population, neighborhood tabulation area code (ntacode), community development block grant eligibility (cdeligibil), borough code (boro_code), area of the census tract (shape_area), and others for 2,166 census tracts of New York City.
If you notice above, there is a column named geometry. It contains the geometric information of the census tracts, i.e., it contains the shape of census tracts as POLYGON. You can read more about other features of the dataset here.
Now, let’s plot our dataset and see if it is correct without using kepler.gl.

Geopandas has got your back here. You can use the plot() function of geopandas to take a look at the GeoJSON:

Great! This looks like New York City. We have our dataset ready now, so let’s jump to the visualization part.
Visualizing Census Tracts
You already know what our first step will be – we have to create a map, and then we’ll add data to it:
If you noticed, I haven’t used the add_data() method here. I have just passed the data to KeplerGl(). It is another way of adding data to it. Also, kepler.gl has already detected the geometry column and plotted it, but it doesn’t look appealing, and also it is not in 3D. So let’s make it:
You can see above that we didn’t have to do much to plot the census tracts in 3D. Finally, now you have created a 3D map of the census tracts, and it looks exactly like what I showed to you earlier. So there you have your 3D map that looks amazingly beautiful.
Saving your Geospatial Visualization
There are two ways to save your visualizations. First, by saving the widget state of the Jupyter notebook and second by exporting map as HTML. So let’s look at the first way:
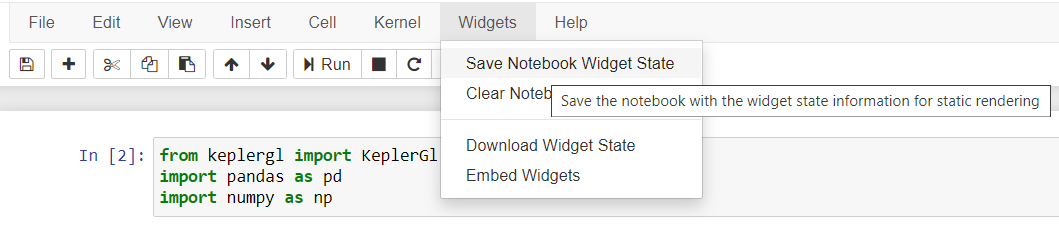
Just click on the Save Notebook Widget State button, and there you have your map saved in the Jupyter notebook. Now let’s take a look at the second method. This one requires you to run a line of code:
Note: This saves only the visible layers and also hides the left panel. If you want to customize the resulting map and see all the layers, then you need to run the following code:
End Notes
Finally, we have arrived at the end of this article. Now, I can say that you know how to use kepler.gl for visualizing geo-location datasets.
For more in-depth analysis, I highly recommend reading their documentation, which is beautifully crafted and easy to read. Also, subscribe to Analytics Vidhya’s YouTube channel for getting amazing videos related to machine learning and data science.
You can reach out to me with your queries and thoughts in the comments section below.
He is a data science aficionado, who loves diving into data and generating insights from it. He is always ready for making machines to learn through code and writing technical blogs. His areas of interest include Machine Learning and Natural Language Processing still open for something new and exciting.




Excellent Abishek, I like it ,can you pls help me to learn this through online meeting.
Thank you, Parthasarathi. If you have any query related to any part of the article, I'll be happy to solve that here.
Good One, Abhishek I got stuck with the error in Folium, I'm following you in github as AshPrasad, Birmingham UK. Got a question I have posted you error at the end of covid problem.
Thank you, Ashwini. I'm glad that you liked my work. I have replied to your query.