This article was published as a part of the Data Science Blogathon.
Introduction
The Tensorflow framework is an open end-to-end machine learning platform. It’s a symbolic math toolkit that integrates data flow and differentiable programming to handle various tasks related to deep neural network training and inference. It enables programmers to design machine learning applications utilising multiple tools, libraries, and open-source resources.
TensorFlow was created with extensive numerical computations in mind, not with deep learning in mind. Nevertheless, it proved valuable for deep learning development, so Google made it open-source.

TensorFlow takes data in tensors, multi-dimensional arrays with more excellent dimensions. When dealing with enormous amounts of data, multi-dimensional arrays come in helpful. TensorFlow code is considerably easier to execute in a distributed way across a cluster of computers when utilising GPUs because the execution mechanism is in the form of graphs.
Table Of Contents
- TensorFlow’s History
- Components of TensorFlow
- The design of TensorFlow and how it works
- Algorithms for TensorFlow
- TensorFlow vs the rest of the field
- What’s the deal with TensorFlow?
- Some Basic Python Implementation with Tensorflow
- Conclusion
TensorFlow’s History
When given a large amount of data, deep learning surpassed all other machine learning algorithms a few years ago. Google realised it could improve its services by utilising deep neural networks:
• Google search engine
• Gmail
• Photo
They created the Tensorflow framework to allow researchers and developers to collaborate on AI models. Many individuals can use it once it has been built and scaled.
It was first released in late 2015, with the first stable version following in 2017. It’s free and open-source, thanks to the Apache Open Source licence. Without paying anything to Google, you can use it, tweak it, and redistribute the updated version for a fee.
Components of TensorFlow
Tensorflow is named after the Tensor framework that it is built on. Tensors are used in every Tensorflow calculation. Any data can be represented by a tensor, an n-dimensional vector or matrix. The tensor values are all of the same data types and have a known (or partially known) shape. The shape of the data is determined by the dimensions of the matrix or array.
A tensor can be derived from either the input or output data of a calculation. TensorFlow performs all of its actions within a graph. The graph is made up of a sequence of sequential computations, and each operation is called an op node, and they are all interconnected.
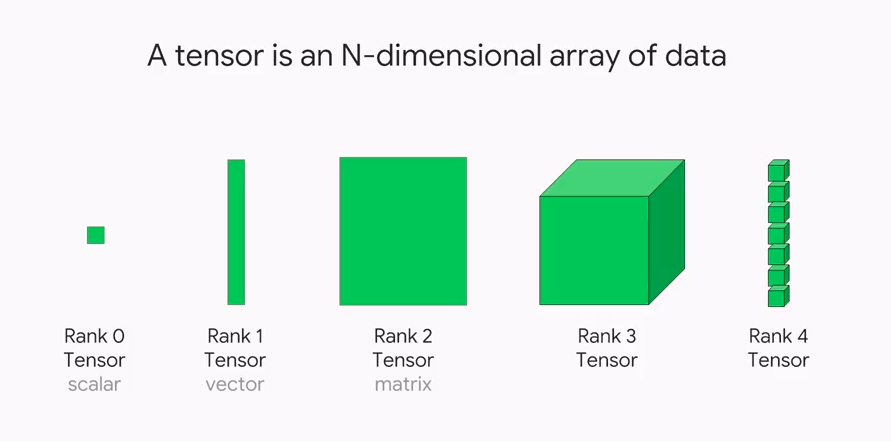
Source: Towardsdatascience
The actions and relationships between the nodes are depicted in the graph.
The values, on the other hand, are not displayed. The edge of the nodes in the Tensor is a means for populating the operation with data.
Graphs
TensorFlow is based on a graph-based architecture. This graph collects all of the training’s series computations are collected and explained in this graph. The chart has a lot of advantages:
• The graph’s portability allows computations to be saved for immediate or later use, and it was designed to run on numerous CPUs or GPUs and mobile devices.
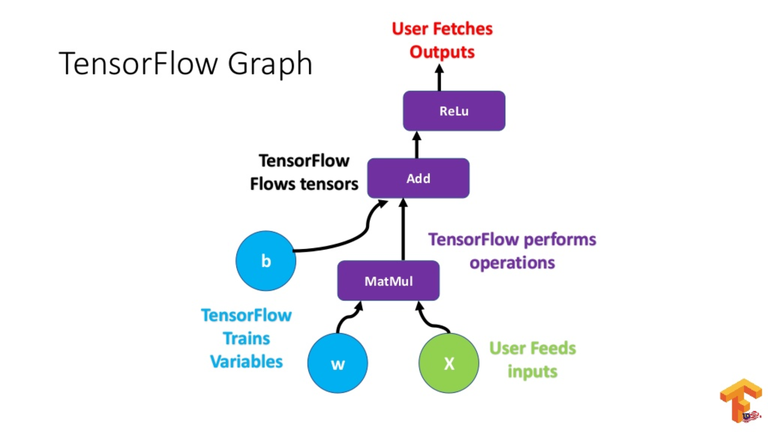
Source: Towardsdatascience.com
• The graph’s computations are entirely done by linking tensors together. Thus, it may be saved and executed later.
The Design of TensorFlow and its Working
TensorFlow allows you to design dataflow graphs and structures to specify how data flows through a chart by receiving inputs as a multi-dimensional array called Tensor. It enables you to create a flowchart of operations that can be done on these inbound and outbound inputs.
This is available to programmers thanks to TensorFlow, which is written in Python. Python is easy to learn and use, and it provides straightforward methods for specifying how high-level abstractions should be linked. TensorFlow nodes and tensors are Python objects, as are TensorFlow applications.
Python, on the other hand, does not do math operations. TensorFlow includes transformation libraries written as high-performance C++ binaries, and Python connects the components by routing data between them and providing high-level programming abstractions.
The architecture of TensorFlow is divided into three parts:
• Preparing the data
• Creating the model
• Prepare the model by training it and estimating it.
Source: Googledevelopersblog
Tensorflow derives its name from the basic concept of taking input in a multi-dimensional array, commonly known as tensors. You can create a flowchart (called a Graph) of the processes you want to run on that input, and the data is entered at one end and output at the other.
Algorithms for TensorFlow
TensorFlow supports the following algorithms:
TensorFlow 1.10 includes a built-in API for:
• tf. estimator for linear regression,LinearRegressor
• Classification:tf.estimator,LinearClassifier
• tf. estimator.DNNClassifier for deep learning classification
• Wipe and deep learning: tf. estimator
DNNLinearCombinedClassifier
• tf. Estimator (booster tree regression).
BoostedTreesRegressor
TensorFlow vs the Rest of the Field
TensorFlow can be assumed a machine learning framework that also competes with the likes of others. Three prominent frameworks, PyTorch, CNTK, and MXNet, serve many of the same objectives, and I’ve highlighted where they stand out and fall short against TensorFlow in the table below.
• PyTorch is comparable to TensorFlow in many ways, in addition to being written in Python: Many essential components are already included, as well as hardware-accelerated components under the hood, a highly interactive development model that allows for design-as-you-go work, and a highly interactive development model that provides for design-as-you-go work.

Source: Pytorh.org
• CNTK, or the Microsoft Cognitive Toolkit, employs a graph structure to represent data flow, similar to TensorFlow, but focuses on deep learning neural networks. Many neural network jobs are handled faster using CNTK.
• Amazon’s adoption of Apache MXNet as the leading deep learning framework on AWS
What’s the Deal with TensorFlow?
TensorFlow has APIs in both C++ and Python.
The coding process for machine learning and deep learning was substantially more complicated before the development of libraries. To create a neural network, set up a neuron, or programme a neuron, this library provides a high-level API that eliminates the need for sophisticated coding. All of the above duties are being completed by the library. TensorFlow also provides Java as well as R integration.
TensorFlow shows compatibility with CPUs as well as GPUs.
Deep learning applications are pretty complex, and the training procedure necessitates a significant amount of computing. Because of the high data size takes a long time and involves multiple iterative processes, mathematical calculations, matrix multiplications, and other steps.
Some Basic Python Implementation with Tensorflow
Setting up TensorFlow
import tensorflow as tf
print("TensorFlow version:", tf.__version__)
Loading a Dataset
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0
Building a Machine Learning Model
model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28)), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(10) ])
Training and Evaluating your Model
model.fit(x_train, y_train, epochs=5) model.evaluate(x_test, y_test, verbose=2) probability_model = tf.keras.Sequential([ model, tf.keras.layers.Softmax() ])
Conclusion
In this article about tensorflow in deep learning, we covered the basic Introduction to the TensorFlow module in Python and a summary of the history of TensorFlow. We also covered other critical terminologies related to TensorFlow like tensors, graphs etc. We also covered the various components of TensorFlow and the design and working of the TensorFlow. Lastly, we covered the basic python implementation of TensorFlow.
Read more articles on our blog.
My name is Pranshu Sharma, and I am a Data Science Enthusiast. Thank you so much for taking your precious time to read this blog. I hope you liked my article on tensorflow in deep learning. Feel free to point out any mistake(I’m a learner after all) and provide respective feedback or leave a comment.
Email: [email protected]
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.
Aspiring Data Scientist | M.TECH, CSE at NIT DURGAPUR






I am so happy your website and me very good