This article was published as a part of the Data Science Blogathon
Introduction
We are living in an era of data. Every day we generate thousands of terabytes of data. This data can be the sales records of a company, the activity of users on an application, your payment history, etc. Using this data, we are creating thousands and thousands of machine learning and deep learning models day by day to find solutions to modern problems. These problems include future sales prediction, fraudulent activity detection, the presence of diseases in patients, and so on. The accuracy and efficiency of these models highly depend on the data we feed to these models. As we are reaching closer to the era of Artificial Intelligence, the hunger for data for these models is increasing too, to achieve outstanding performance. A deep analysis is done on data and so it is important to structure and maintain the data properly in appropriate ways so that it could be accessed and modified easily.
In this article, we will be going to learn about different file formats. We will learn about how the same data can be stored in different file formats and which file format should be preferred for a specific application. We will also learn about row and columnar ways of storing data, how they two are different from each other and what could be the reason behind choosing one over the other.
Propriety vs Free file formats
A propriety file format is a specific file format that is owned and used by the company. Reading and editing in these file formats require propriety software. This is to ensure that the users cannot read, modify or copy the source code and resell it as their own product.
Free file formats on the other hand are open source and can be read using open-source software. Data present in these file formats can be read, changed, modified by users, and can be used for their own purpose using simple tools and libraries. We will be going to cover only open file formats in this article.
We start with one of the most common and favorite file formats for storing textual data of all time that is CSV.
CSV (Comma Separated Values)
CSV is one of the most common file formats for storing textual data. These files can be opened using a wide variety of programs including Notepad. The reason behind using this format over others is its ability to store complex data in a simple and readable way. Moreover, CSV files offer more security as compared to file formats like JSON. In python, it is easy to read these types of files using a special library called Pandas.

import pandas as pd
file_csv = pd.read_csv("File.csv")
print(file_csv.head())Note- If the CSV file is zipped in a format like gzip, bc, zip, etc, we can add a further argument as written in the 4th line of the code(as a comment). However, the zip file must contain only one file.
JSON (JavaScript Object Notation)–
It is a standard format for storing textual data based on JavaScript object index. It is basically used for transmitting data in web applications. Unlike CSV, JSON allows you to create a hierarchical structure of your data. JSON allows data to be stored in many data types including strings, arrays, booleans, integers, etc.
JSON formats are easy to integrate with APIs and can store a huge amount of data efficiently. They provide scalability and support to relational data.
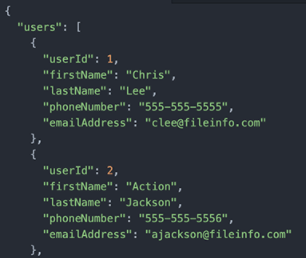
import pandas as pd
# Reading json file using pandas
file_json = pd.read_json("file.json")#replace file with actual file name
# printing the top 5 entries present in the csv file
print(file_json.head())
XML (Extensible Markup Language)
This file format has a structure similar to HTML and it is used to store data and transfer data without being dependent on software and hardware tools. XML language is Java compatible and any application that is capable of processing it can use your information, whatever the platform is.
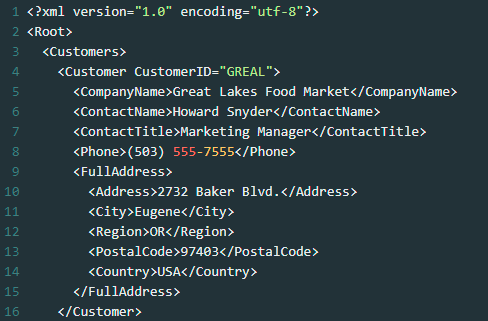
import pandas as pd
# Reading a xml file using pandas
file_xml = pd.read_xml("file.xml")#replace file with actual file name
# printing the top 5 entries present in the csv file
print(file_xml.head())
Note: Pandas read_xml function is available in the latest pandas version 1.3.0 So you might have to upgrade pandas. You can do that with the below command
pip3 install --upgrade pandasYAML ( YAML Ain’t Markup Language) –
YAML is a data serialization language that is mainly used for human interaction. It is a superset of JSON which means it includes all the features of JSON and more. Unlike other file formats, YAML uses indentation as part of its formatting like python. The benefits of using YAML over other file formats are:
- Files are portable and transferable between different programming languages.
- Expressive and extensive format
- Files support a Unicode set of characters

import pyyaml
from yaml.loader import SafeLoader
# Open and load the file
with open('Sample.yaml') as file:
data = yaml.load(file, Loader=SafeLoader)
print(data)
Parquet
Parquet is a binary file format that allows you to store data in a columnar fashion. Data inside parquet files are similar to RDBMS style tables but instead of accessing one row at a time, we are accessing one column at a time. This is beneficial when we are dealing with millions and billions of records having a very little number of attributes.
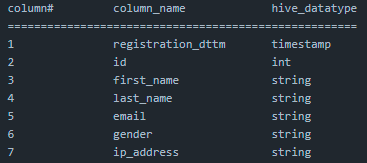
import pyarrow.parquet as pq
# Read the table using pyarrow
table = pq.read_table('example.parquet')
# Convert the table to pandas dataframe
table = table.to_pandas()
# print the table
print(table.head())
Row vs columnar file formats
Most of the files we use in our daily life are present in row file formats where we are searching each record before moving to the next. Data present in these formats are easy to read and modify as compared to columnar formats like parquet. But when we are dealing with a huge number of records, simple operations like searching and deletion cost a considerable amount of time. To deal with the problem, we use columnar file formats
Why use columnar file formats
In columnar formats, Instead of accessing each record, we access each column. Suppose the size of each entry to be 100 bytes. Let’s say, there were 10 records in the table but we only needed to access two. For 1 billion records it takes about 1000 seconds to go through the whole database at a speed of 100MB/s. But, if we search through the columns instead of searching by each record, it would take 2/10 * 1000s that is 200 seconds to do the whole computation. So, a lot of time could be saved using columnar file formats. Other than that columnar representation of data provides better compressibility of data and columns can be compressed using different methods. So it further leaves with some scope of improvement.
Data compression techniques
- Gzip – This file format is used for data and file compression. It is based on DEFLATE algorithm which is based on Huffman and LZ77 coding. This is a lossless way of compression. The amazing thing is that it allows multiple files to be compressed as a single archive. It provides a better compression ratio than other compression formats at the cost of a slower speed. It is the best for storing data that don’t need to be modified frequently.
- Snappy – These file formats provide faster compression but fail to provide a better compression ratio than Gzip. However, this compression format can be best suitable to compress data that require frequent modification.
Conclusion
There are various file formats available for storing data and creating your own datasets. But choosing one depend upon the requirements and the type of data. To choose a format that is best suitable for your application, you should at least be aware of the available options. Other than that, you should be aware of your priorities like data security, size of data, speed of operations, etc. For example, if data security is the highest priority it is better to use CSV files over JSON, or maybe choosing propriety file format could be the best option.
Hi there. Writing and exploring are some of my hobbies. I love Machine learning because of its endless applications and scope for improvement. I enjoy problem-solving and learning about new things. I believe to learn any new skill one should have the will to learn it. Ask the right questions and the rest, Google search will take care of it. In my free time, I like listening to music and jamming on my guitar.
You can connect with me on LinkedIn, and send me any suggestions or questions. I'll be happy to reply.
Keep Learning






