This article was published as a part of the Data Science Blogathon
Introduction
In the previous article, we have talked about BERT, Its Usage, And Understood some of its underlying Concepts. This article is intended to show how one can implement the learned concept to create a spam classifier using BERT.
Table Of Contents
- Introduction
- Understanding Spam Emails
- Overview Of The Pipeline
- Implementing Spam Detection
Understanding Spam Emails
Let’s suppose you got up in the morning and opened your Gmail and found a mail saying something like:
“Hey, you have won an iPhone 10 in the luck draw conducted by amazon yesterday. To receive the prize please log in to your account and claim your gift.”
Seeing mail you first checked the sender and you found him to be genuine, and you happily rushed to the site and logged in and found there was no prize at all. Feeling sad you returned to your works.
A few hours later you received a message stating there has been a recent transaction from your bank account and you are shocked how it happened. After telling the incident to the bank, they told you have been spammed and millions are facing the same difficulty, sounds terrible right!
But my friends luckily for you google has some type of mechanism to find these emails and separate them in its SPAM folder(see fig 1.1).
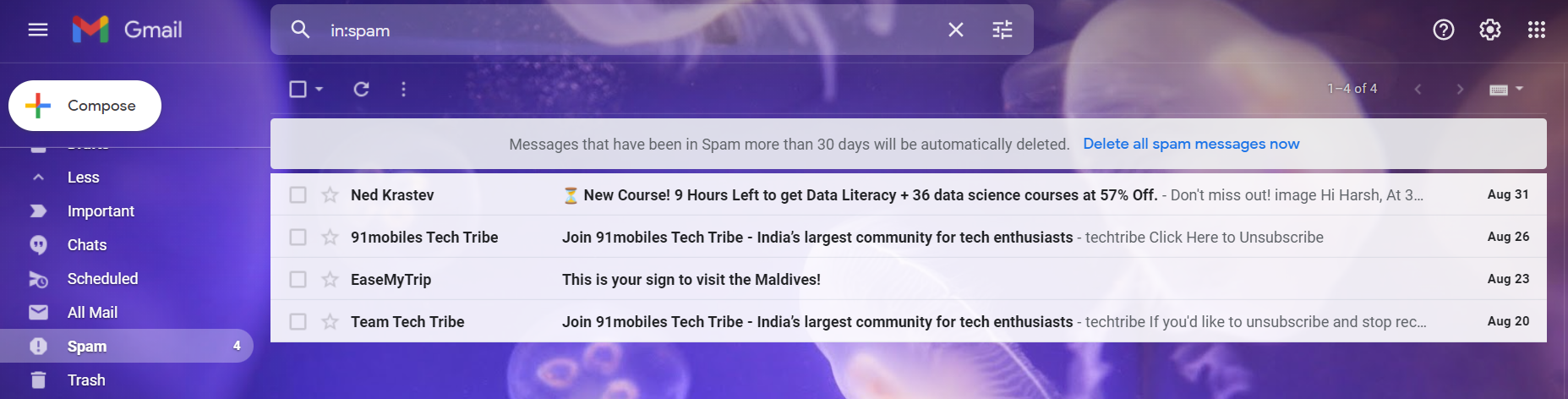
Spam emails are unwanted emails share in bulk intending to gather data/ do phishing/ perform social engineering/ start an attack and a lot more – mostly for bad causes. Usually, these are in form of advertisement and marketing stuff.
Since these are sent in bulk, each one will have a similar underlying pattern and format, so what the mechanism of google does is finds these underlying patterns and separates them.
This method is generally called spam classification and uses a model which is trained on spam and not a spam set of data.
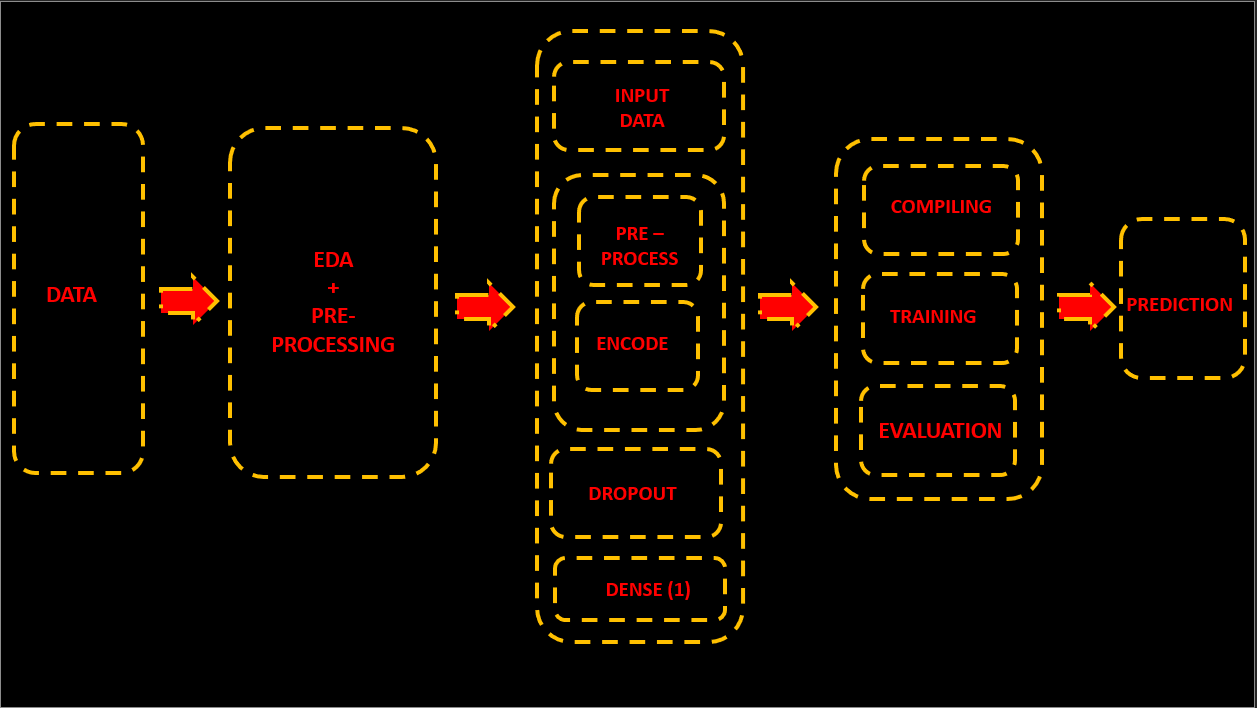
The Pipeline Overview for Spam Detection Using BERT
To build the system ourselves we are going to follow these procedures:
1. Load Data – We will be loading our data which is simple [2 categories(ham and spam) along with corresponding emails] CSV file. The file can be found here
2. EDA – Perform some EDA to get a feel of what data looks like – statistics here!
3. Pre Processing – Based on the results of EDA we will be going to apply some preprocessing to the data to make it model friendly
4 – Model Creation – We will use Functional API* to build our Deep Learning Model which will consist of
- INPUT – Will create an input layer that will take in all the pre-processing data and pass it to bert_processor.
- BERT PREPROCESSOR – Process our input text to be in the format which encoder accepts. (adds MASK AND ENCODINGS).
- BERT ENCODER – Feed our processed text to the bert model which will eventually generate a contextualized word embedding for our training data.
- DROPOUT – Add a dropout layer that will randomly drop out a few neurons from the network to take care overfitting problem.
- SOFTMAX – At last we will add a softmax layer to predict data in 2 categories.
- + 2 more generic steps.
5- Model Evaluation – Further we will check how the model performs on the test data and plot some relevant charts and metrics based on the observations.
6- Predict Data – Finally we will predict our own emails using the model.
Here is a general visualization of the flow of logic:
Functional API
A way to create models with more flexibility and complexity than traditional sequential models. Complexity includes- Shared layers, Multiple Inputs – Outputs, and much more.
Here is how one can quickly create a model using functional API:
Layer1 = Input(shape = (shape), name = 'layer_name') Dense = Dense(num_units = units, activation = activation, name = 'dense')(Layer1) model = Model(inputs = [Layer1], outputs = [Dense])
So all you have to do is pass the last previous layer as an input to the current layer and finally call the create the model using Model(inputs, outputs).
Implementing Spam Detection Using BERT
To start we will first download a readily available dataset which can be downloaded from the link given earlier. Once you downloaded it will look something like this:

Here ham – Good Mails and Spam – Spam mails. Our job will be to build a model which can train on the data and return prediction when given new inputs.
Loading Dependencies
So, first of all, we are going to import few libraries namely:
- Tensorflow_hub: Place where all TensorFlow pre-trained models are stored.
- Tensorflow: For model creation
- Pandas: For data loading, manipulation and wrangling.
- Tensorflow_text: Allows additional NLP text processing capabilities outside the scope of tensorflow.
- Skelarn: For doing data splitting
- Matplotlib: For visualization support
import tensorflow_hub as hub import pandas as pd import tensorflow_text as text import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split import tensorflow as tf import numpy as np
Loading Data
Now we will just load our data into a pandas dataframe ‘df‘ using its read_csv() method/fn and view the first 5 samples using the head() method:
# load data
df = pd.read_csv('/content/spam_data.csv')
df.head()
Executing the above code returns a data frame with the first 5 samples:
Image By Author
Spam Detection Exploratory Data Analysis
We will now do some of the Exploratory – Data Analysis to check how data is distributed along 2 categories. This will give us a feel if we need to do some type of preprocessing over data or is it on the same scale.
To perform this operation we will just be grouping the data based on category and call value_counts() method on it like:
# check count and unique and top values and their frequency df['Category'].value_counts()
This returns no of samples of each class as :
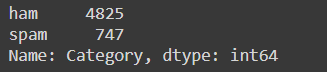
Clearly, the data is imbalanced and there are more good emails(ham) than spam emails. This may lead to a problem as a model may learn all the features of the ham emails over spam emails and thus always predict all emails as ham(OVERFITTIN!). So before proceeding, we need to take care of that.
Downsampling Data
Downsampling is a technique where the majority class is downsampled to match the minority class. Since our data has only one column(feature) it ok to use it.
We perform downsampling by just picking any random 747 samples from the ham class. Here is the code to do that:
1) We first calculated the percentage of data that needs to be balanced by dividing minority (spam) by majority(ham) :
# check percentage of data - states how much data needs to be balanced print(str(round(747/4825,2))+'%')
>> 0.15%
It came out to be 15% of data that needs to be balanced.
2) We then create 2 new datasets namely ham and spam and filtered the data having categories as spam and ham and append it to the respective dataset and finally printed their shape to confirm the filtering and creation:)
# creating 2 new dataframe as df_ham , df_spam
df_spam = df[df['Category']=='spam']
df_ham = df[df['Category']=='ham']
print("Ham Dataset Shape:", df_ham.shape)
print("Spam Dataset Shape:", df_spam.shape)
>> Spam Dataset Shape: (747, 2) Ham Dataset Shape: (4825, 2)
Seems like filtering and separation were successful:)
3) Now we will sample the ham dataset using the sample() method with the shape of our spam dataset and to be more specific load it into a new dataframe df_ham_downsampled and print its shape to cross verify.
# downsampling ham dataset - take only random 747 example # will use df_spam.shape[0] - 747 df_ham_downsampled = df_ham.sample(df_spam.shape[0]) df_ham_downsampled.shape
>> (747, 2)
4) Finally we will concatenate our df_ham_downsampled and df_spam to create a final dataframe called df_balalnced.
# concating both dataset - df_spam and df_ham_balanced to create df_balanced dataset df_balanced = pd.concat([df_spam , df_ham_downsampled])
Checking the value counts again projects downsampling we have done-)
df_balanced['Category'].value_counts()
Returns:
>> spam 747 ham 747 Name: Category, dtype: int64
Printing few samples wouldn’t hurt either – 10 samples
df_balanced.sample(10)
Returns – Evenly distributed data of spam and ham (no in cade of head)
| Category | Message | |
|---|---|---|
| 5164 | spam | Congrats on 2 mobile 3G Videophones R yours. call… |
| 1344 | ham | Crazy ar he’s married. Ü like gd-looking guys … |
| 1875 | spam | Would you like to see my XXX pics they are so … |
| 907 | spam | all the latest from Stereophonics, Marley, Di… |
| 3848 | spam | Fantasy Football is back on your TV. Go to Sky… |
| 4973 | ham | I’m fine. Hope you are well. Do take care. |
| 1540 | ham | You’re not sure that I’m not trying to make a… |
| 1312 | ham | U r too much close to my heart. If u go away i… |
| 4086 | spam | Orange brings you ringtones from all-time Char… |
| 3010 | spam | Update_Now – 12Mths Half Price Orange line ren… |
Preprocessing of Spam Detection Data
One Hot Encoding Categories
As can be seen, we have only text as categorical data, and the model doesn’t understand them. So instead of text, we can just assign integer labels to our class ham and spam as 0 and 1 respectively, and store it in new column spam. This is called- Hot-Encoding
To achieve this we will just be filtering the column category and perform operations:
- 1 – If a category is a ham/ not spam
- 0 – if the category is spam
The best part is that we can use the one-liner lambda function to achieve the following result and apply it to the dataframe for all values.
Lambda Fn Syntax = [lambda x : value expression else value]
So we can use the following code to achieve the desired result:
# creating numerical repersentation of category - one hot encoding df_balanced['spam'] = df_balanced['Category'].apply(lambda x:1 if x=='spam' else 0)
For checking the result we can now just print few samples as :
# displaying data - spam -1 , ham-0 df_balanced.sample(4)
Returns :
| Category | Message | spam | |
|---|---|---|---|
| 2100 | spam | SMS SERVICES. for your inclusive text credits,… | 1 |
| 5120 | spam | PRIVATE! Your 2003 Account Statement for 078 | 1 |
| 4590 | ham | Have you not finished work yet or something? | 0 |
| 2066 | ham | Cos daddy arranging time c wat time fetch ü ma… | 0 |
Modification to the data frame was successful.
Performing Train Test Split
Now as our data is processed, we can feed it to the model, but if we do so it may be that model will learn the patterns of the data, and when we evaluate it will always predict the right results, which leads to biasing of the model. So we will follow the train test strategy.
Train Test Split Strategy:
It states out of all data (population) a large amount of data goes in for training(about80%) which has inputs(Messages) and Labels(1/,0) and the remaining 20% will not be fed to the model. When we further do evaluation we can just predict on that 20% and see how it performs as the model will not be biased now.
* Note :- it is generally considered to split data as 80:20 as good ratio but can be experimented:)
The above can be achieved using the train_test_split fn of sklearn.
# loading train test split
from sklearn.model_selection import train_test_split
X_train, X_test , y_train, y_test = train_test_split(df_balanced['Message'], df_balanced['spam'],
stratify = df_balanced['spam'])
Here we first loaded the fn from sklearn.model_selection module and performed the split and set stratify to select almost equal no samples from the dataset.
Here:
- X_train, y_train – training inputs and labels – Training Set
- X_test, y_test – testing inputs and labels – Testing Set
This marks the end of the pre-processing part and now our model is ready for training. But before that, we need to generate word embedding and that’s what we are going to see in the next section:)
Model Creation
Downloading Prerequisites
To create our model we will first download the bert preprocessor and encoder(for more info refer to the previous article ) as it allows us to use them as function pointers where one can feed our inputs and get the processed output and embedding. Also, this helps in better readability of the code.
# downloading preprocessing files and model
bert_preprocessor = hub.KerasLayer('https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3')
bert_encoder = hub.KerasLayer('https://tfhub.dev/tensorflow/bert_en_uncased_L-12_H-768_A-12/4')
Here :
- bert_preprocessor – preprocessor
- bert_encoder – main model (layers – 12 , Hidden Layers – 768 and Attention – 12)
Creating Model
Having downloaded the bert model, we can now use Keras Functional API to build our model.
text_input = tf.keras.layers.Input(shape = (), dtype = tf.string, name = 'Inputs') preprocessed_text = bert_preprocessor(text_input) embeed = bert_encoder(preprocessed_text) dropout = tf.keras.layers.Dropout(0.1, name = 'Dropout')(embeed['pooled_output']) outputs = tf.keras.layers.Dense(1, activation = 'sigmoid', name = 'Dense')(dropout)
# creating final model model = tf.keras.Model(inputs = [text_input], outputs = [outputs])
A couple of points to notice here: –
- text_input: As our model data shape can be anything so we will pass shape parameters as shape(), its data type as tf. string, and name as Inputs.
- dropout:- For the dropout layer, we have set dropout rate 0.1 – 10% of neurons will randomly shut off and passed embedding dictionary pooled_output as an input to this layer i.e simply passing entire training data embeddings to the dropout layer.
- outputs: Sigmod as activation as the problem is a binary in nature problem, however, relu can also be used
- model: Our model inputs will be an array, so used [] in inputs and outputs.
Printing the model summary returns the model architecture and no of the trainable and non-trainable parameters (weights):
# check the summary of the model model.summary()
As can be seen, there are over 109,482,241 parameters that are from the BERT model itself and are non-trainable. This gives the feel of what this LRM is:)
Compiling And Training Model
As a generic step in the model building, we will now compile our model using adam as our optimizer and binary_crossentropy as our loss function. /For metrics, we will use accuracy, precession, recall, and loss.
Metrics = [tf.keras.metrics.BinaryAccuracy(name = 'accuracy'),
tf.keras.metrics.Precision(name = 'precision'),
tf.keras.metrics.Recall(name = 'recall')
]
# compiling our model
model.compile(optimizer ='adam',
loss = 'binary_crossentropy',
metrics = Metrics)
And now comes the best part, training our model. For training, we will just fit the model with the training set and let it run for 10 epochs(one can experiment with it), and store the result in the history variable.
history = model.fit(X_train, y_train, epochs = 10)
Now let’s see the result which was returned:
It looks like we have a 91% accurate model and have a good precession and recalls so we can now evaluate our model.
Precision is defined as the fraction of relevant instances among all retrieved instances.
Recall sometimes referred to as ‘sensitivity, is the fraction of retrieved instances among all relevant instances.
A perfect classifierhas precision and recall both equal to 1Refrence : Precesion & Recall
Model Evaluation
Evaluating Model
To evaluate our model we will simply use the model’s evaluate method feeding it testing data and labels to get a rough estimate of how the model is performing.
# Evaluating performance model.evaluate(X_test,y_test)
Output
It is similar to training results which may lead to the wrong interpretation of the model. So we need a better way to understand how our model is performing and usually, classification reports and confusion matrices are the way to go.
Plotting Confusion Matrix and Classification Reports
We can use the sklearn confusion matrix and classification report which takes in actual labels(y_test) and predicted labels(y_pred) and returns an array of numbers which we will be plotting using seaborn’s heatmap and matplotlib.
# getting y_pred by predicting over X_text and flattening it y_pred = model.predict(X_test) y_pred = y_pred.flatten() # require to be in one-dimensional array , for easy manipulation
# importing confusion maxtrix from sklearn.metrics import confusion_matrix , classification_report # creating confusion matrix cm = confusion_matrix(y_test,y_pred) cm
>> array([[174, 13],
[ 17, 170]])
Here we are just predicting X_test to get y_pred(prediction) and flattening it to reshape it to a one-dimensional vector and feeding it to the confusion _matrix function and storing the result in cm.
Plotting results returns a nice looking graphs as :
# plotting as a graph - importing seaborn import seaborn as sns
# creating a graph out of confusion matrix
sns.heatmap(cm, annot = True, fmt = 'd')
plt.xlabel('Predicted')
plt.ylabel('Actual')
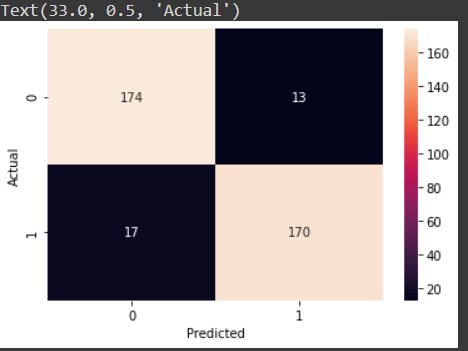
As can be seen for X-axis – We have Predicted Values, For Y-axis – We have Actual Values. Also at diagonal, we have model correct predictions.
Through the graph we can see that out of a total, 174 times the mail was ham (0) and the model predicted it right and for 170 times it was spam and model predicted spam(1), so overall we have created a good model, however one can experiment with the parameters, layers and network architecture to increase it
Classification report is also plotted similarly:
# printing classification report print(classification_report(y_test , y_pred))
Returns:
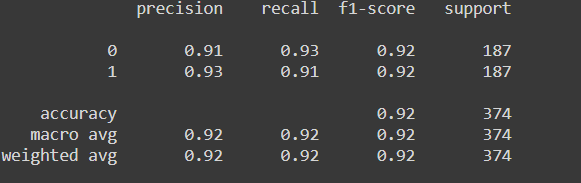
Here also it is evident that the model is a good one as recall and accuracy us good:)
Model Prediction for Spam Detection Using BERT
Now let’s check how the model performs on real-world data.
Here I have a collection of few spam and ham emails:

Let’s see how it performs on it:
predict_text = [
# Spam
'We’d all like to get a $10,000 deposit on our bank accounts out of the blue, but winning a prize—especially if you’ve never entered a contest',
'Netflix is sending you a refund of $12.99. Please reply with your bank account and routing number to verify and get your refund',
'Your account is temporarily frozen. Please log in to to secure your account ',
#ham
'The article was published on 18th August itself',
'Although we are unable to give you an exact time-frame at the moment, I would request you to stay tuned for any updates.',
'The image you sent is a UI bug, I can check that your article is marked as regular and is not in the monetization program.'
]
test_results = model.predict(predict_text)
output = np.where(test_results>0.5,'spam', 'ham')
Here all we have done is:
- Created a list that contains all the sentences.
- Predicted the sentence category using our model and stored the result in variable ‘test_result‘.
- Created a lambda function for filtering values greater than ‘as spam’ else, not ‘spam’ using NumPy. where which ideally searches for the values and stores them in the ‘outputs‘.
Now let’s check the result:
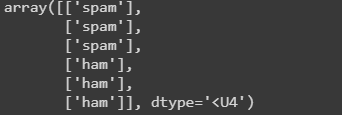
Image By Author
As can be seen, it classified all our data correctly. So congrats on making it this far.
Endnote
I know this has been a very long article, but I intended to capture every small detail and make it more understandable to even beginners. Also if you were following along, you now know the following:
- A systematic procedure to work on Deep Learning Projects.
- Some of the Data Science concepts such as file i/o using pandas, down-sampling, confusion matrix, classification reports, and plotting them using seaborn.
- How to use functional API to create complex models.
- How to load and use the BERT model very easily(literally in 5 lines of code).
- And lastly got some info in the world of spams and spammers.
I think these are great feats to achieve. What do you think? let me know in the comments below:)
Also if you liked the efforts and learned something consider sharing this article with others. You can also connect to me on my LinkedIn or Instagram page.
References
For knowledge diggers, here are the relevant links that may help you follow along with the article:
Collab File:- For codes and documentation refer here.
BERT Details(in-depth):- BERT (Bidirectional Encoder Representation From Transformers), For a visual representation refer here.
Keras Functional API – To learn more about functional API refer here.
SkLearn: For info on sklearn refer here.
Inspiration: A humble and respectful thanks to code basics which inspire me to write the content.
* All Images Are My Own:)
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.
A dynamic and enthusiastic individual with a proven track record of delivering high-quality content around Data Science, Machine Learning, Deep Learning, Web 3.0, and Programming in general.
Here are a few of my notable achievements👇
🏆 3X times Analytics Vidhya Blogathon Winner under guides category.
🏆 Stackathon by Winner Under Circle API Usage Category - My Detailed Guide
🏆 Google TensorFlow Developer ( for deep learning) and Contributor to Open Source
🏆 A Part Time Youtuber - Programing Related content coming every week!
Feel free to contact me if you wanna have a conversation on Data Science, AI Ethics & Web 3 / share some opportunities.




