This article was published as a part of the Data Science Blogathon.
Introduction
Logos, also known as trademarks, are critical to a firm. Each firm has its unique logo that contributes to the company’s public perception. From the toothpaste we use to the slippers we wear, logos surround us in our day-to-day life.
“It’s a habit of mine now, noticing labels, logos, shoes.”
~ Michael Jordan
They are everywhere in such an insane amount that we cannot help but notice them. Moreover, over the years, Logo Detection began gaining widespread attention because of its various applications. Its applications range from marketing to security. With its attention, many open source models and blogs are available for logo detection. So why another post on logo detection?
To understand the why, we must understand the existing approaches toward logo detection.
Logo detection is a part of a broader family of object detection; in other words, its an application of object detection. Furthermore, generally in object detection tasks, we are to predict the bounding box for objects in an image.

For an object detection model, the training data we need to provide consists of the image we want to detect, the bounding box coordinates, and the label of the bounding box. It is the same for logo detection.
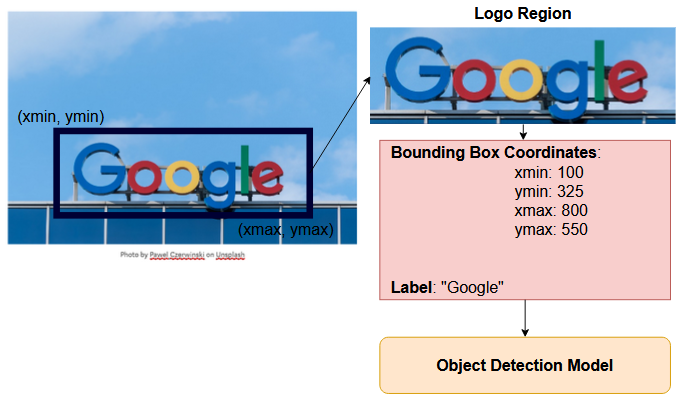
Most of the existing open source logo detection models use brand names as the label; for example, A apple logo will have “Apple” as the label. That is where we found a problem that we would like to solve.

You might ask, what’s the problem with using brand names as the label for logo detection?
Despite gaining widespread attention, there is still a lack of research in logo detection. Not many logo detection models are available that will detect whether the image has a logo or not. This blog proposes a model that, if a logo is present in an image, can identify and predict the bounding box around it regardless of which brand it represents.

With new businesses being registered daily, keeping track of each brand’s logo is challenging. Class Imbalance problems aside, it’s also hard to find sufficient data for each brand to keep our model up to date. This might create difficulties in identifying new brands in the image during inference. For example: suppose a new brand, “XYZ,” with its new logo, comes into the market, and our model is not trained on that. Obviously, during inference, we won’t be able to detect its logo.
And what if we simply want to detect the logos in the image and do not care which brand it belongs to. For example, suppose an image is given, and we just want to correctly identify the bounding boxes around the logos in the image irrespective of whether that logo belongs to “Apple” or “Google.” That’s the problem we want to address in this blog.

Approach
A Machine learning pipeline is used to construct and automate machine learning workflows. It contains steps like preparing data, training and validating the model, etc. We also follow a similar workflow for the logo detection model development.
 Source: https://docs.microsoft.com/en-us/azure/machine-learning/service/concept-ml-pipelines
Source: https://docs.microsoft.com/en-us/azure/machine-learning/service/concept-ml-pipelinesThe changes we make are in the preparation of the data. We created an end to -end pipeline to detect whether a given image has a logo or not, and if the logo is present, predict the bounding box. It’s a classic object detection pipeline; the difference we purpose is in the annotation process. A standard object detection model requires at least two object classes for it to work. But presently, the logo detection datasets have the brand name for the object class; using brand names for object class has the following disadvantages:

- Firstly the datasets will not consist of all the brands. Therefore we will never have sufficient training data. Curating such large-scale data will take lots of time. Apart from that, we also have to keep track of all new brands registering daily, which will create a problem in identifying new brands in the image during inference.
- The datasets we create might be prone to imbalance which again creates that problem during inference. For example, We might have more images from one brand than the other.
- We have to keep training each day to keep up to date.
To solve this problem, we annotated the data; differently, we divided logos into two classes:
- Text logos: Logos with text in it
- No Text logos: Logos with no text in them.

We annotate the data concerning these two classes; this mitigates our previous problem of brand dependency.
Why use this approach?
Rather than creating our own data set and custom model, this approach lets us use already available datasets and object detection models. Conveniently looking at all the logos, it makes sense to divide logos into two groups logos with text in them and logos without the text. Also, we have to give at least two classes to train on for any object detection model.
We identified two datasets for our problem LogoDet-3K: A Large-Scale Image Dataset for Logo Detection and Visually29K: a large-scale curated infographics dataset.
Annotation
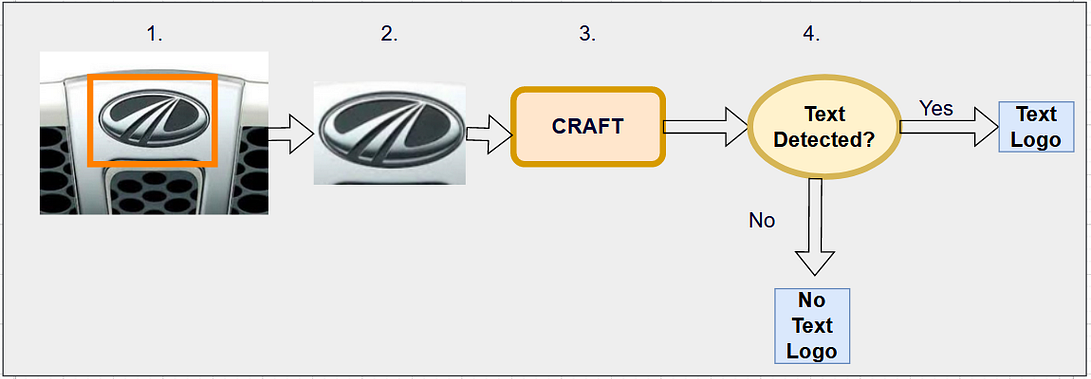
We used the following steps to annotate the data:
- Extracted the bounding box coordinates from the already available annotated logo datasets.
- Cropped the image for that bounding box to get that particular region
- Gave cropped logo image as input to the text detection model. We used CRAFT: Character-Region Awareness For Text detection as the text detector.
- If text is detected, we label that particular bounding box as “Text”. Else we label the bounding box as “NoText”.
Datasets
LogoDet-3K: A Large-Scale Image Dataset for Logo Detection

LogoDet-3k is a large-scale high-quality logo detection dataset consisting of 3000 logo categories, 158,652 images, and 194,261 bounding boxes. In this dataset, according to our approach, we observe three types of images:
- Images that contain only text logos.

2. Images that contain only no text logos.

3. Images that contain both text and no text logos.

After we finish the process, we observe a severe class imbalance between text bounding boxes and no text bounding boxes, with no text bounding being the limiting class. To compensate for this imbalance, we next use the Visually29K dataset.
Visually29K: a large-scale curated infographics dataset
Visually29K consists of 28,973 infographics to cover a fixed set of 391 tags (filtered down from free-form text). They provide a bounding box for icons in the infographics from the dataset. As icons are very similar to no text logos, we use that to compensate for the imbalance of no text logos; in simple words, use the icons as no text logos. Hence we proceed to annotate the Visually29K dataset similar to how we annotated the LogoDet-3K dataset.
After the annotation step, we now proceed to train our model.
Model
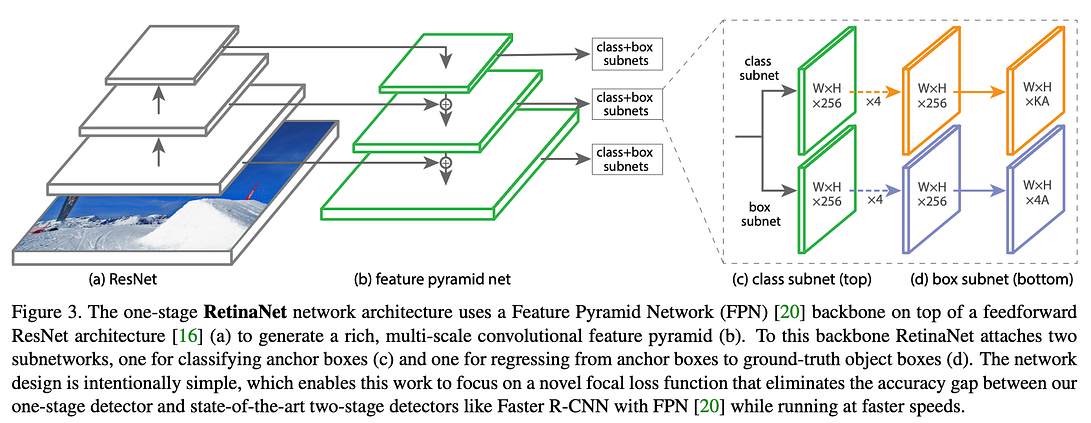
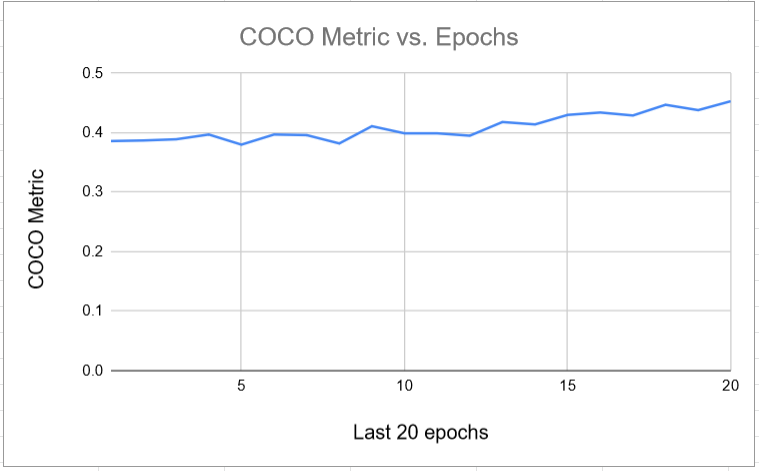
We use the icevision library for our model training and inference purposes. We use mmdetection’s retinanet architecture for the object detection model with a pre-trained resnet50_fpn_1x as its backbone. The Metric used was COCOMetric.
Training

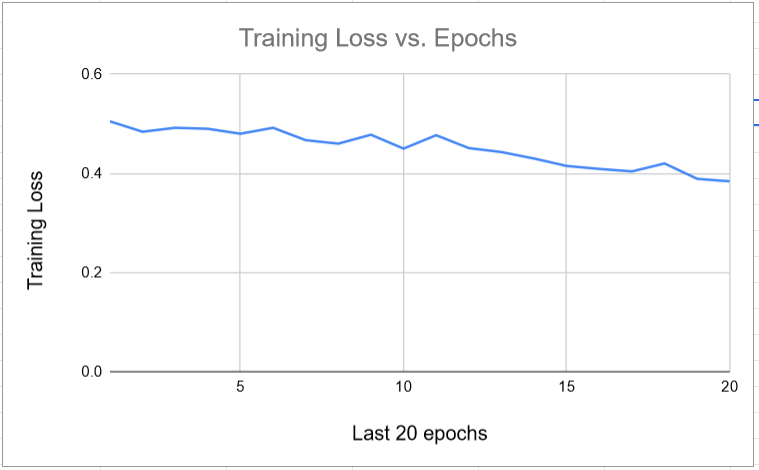
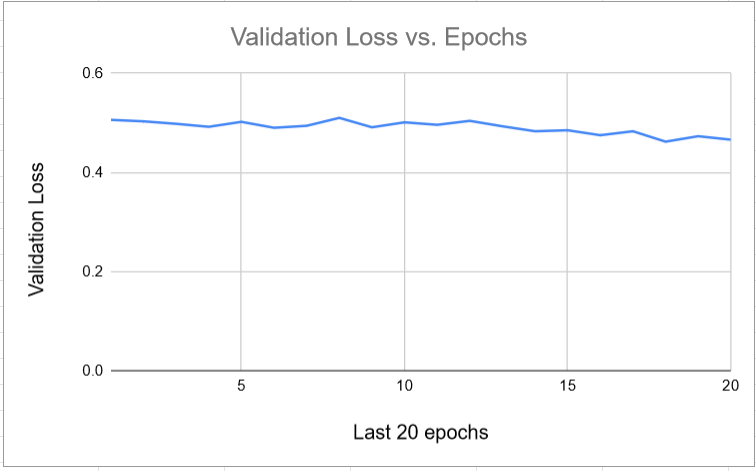
For the training process, first, a custom data parser is used that will parse our data and present it to the model for training and testing purposes. We first train our data on 30,000 images. Later we increase the number of images to 53000. The 30,000 images only include images from LogoDet-3K, and 53,000 contain images from LogoDet-3K and Visually29K. We train them for 30 epochs and 50 epochs, respectively.
Later it is found that the validation loss or Metric is not increasing significantly, so training is stopped.
Inference
We saved the checkpoints from the previous step, letting the 30k images checkpoint be checkpoint 1 and the 53k images be checkpoint 2. So we find that checkpoint 1 is more inclined toward text logos; it might be because we did not check for imbalance at that moment, but the 30K images dataset was imbalanced towards text logos. And checkpoint 2 detected more no text logos. We later created an ensemble of checkpoint 1 and checkpoint 2 for our final model.

Results
Some good cases


Some bad cases


Conclusion
An enormous number of companies are in the market, each with its logo and brand name. It isn’t easy to develop a logo detection model with brand names as the classes. In this case, we have to reduce the number of classes. In this blog, I describe an approach of reducing the number of classes to train a generic logo detection model that detects a logo if it is present in the image.
Some of the key takeaways from the article are:
1. Logo detection with brand names as classes creates lots of problems. We need to reduce the number of classes to develop a model for general use to resolve these issues.
2. Logos can be divided into two classes logos with text and logos without text. We can annotate some existing datasets according to those two classes and train an object detection model.
3. Some of the approach’s shortcomings might be that it won’t tell which brand the logos belong to. Second, there might be false positives because we are using the VisuallyData dataset, which is a dataset for icons. Subsequently, our logo detection model might recognize icons as logos.
This marks the end of this blog!
A big thanks to Divyam Shah and Shashank Pathak!
Check out the GitHub repository for the code: https://github.com/LaotechLabs/LOGOS. This project is open-sourced, if you wish, you are welcome to collaborate with us on the project :)!
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.






