Overview
- Presenting 21 open source tools for Machine Learning you might not have come across
- Each open-source tool here adds a different aspect to a data scientist’s repertoire
- Our focus is primarily on tools for five machine learning aspects – for non-programmers(Ludwig, Orange, KNIME), model deployment(CoreML, Tensorflow.js), Big Data(Hadoop, Spark), Computer Vision(SimpleCV), NLP(StanfordNLP), Audio, and Reinforcement Learning(OpenAI Gym)
Introduction
I love the open-source machine learning community. The majority of my learning as an aspiring and then as an established data scientist came from open-source resources and tools.
If you haven’t yet embraced the beauty of open-source tools in machine learning – you’re missing out! The open-source community is massive and has an incredibly supportive attitude towards new tools and embracing the concept of democratizing machine learning.
You must already know the popular open-source tools like R, Python, Jupyter notebooks, and so on. But there is a world beyond these popular tools – a place where under-the-radar machine learning tools exist. These aren’t as eminent as their counterparts but can be a lifesaver for many machine learning tasks.
In this article, we will look at 21 such open-source tools for machine learning. I strongly encourage you to spend some time going through each category I have mentioned. There is a LOT to learn beyond what we typically learn in courses and videos.
Note that many of these are Python-based libraries/tools because let’s face it – Python is as versatile a programming language as we could get!
We have divided the Open Source Machine Learning Tools into 5 Categories:
- Open Source Machine Learning Tools for non-Programmers
- Machine Learning Model Deployment
- Big Data Open Source Tools
- Computer Vision, NLP, and Audio
- Reinforcement Learning
1. Open Source Machine Learning Tools for Non-Programmers
Machine learning can appear complex to people coming from a non-programming and non-technical background. It’s a vast field and I can imagine how daunting that first step can appear. Can a person with no programming experience ever succeed in machine learning?
As it turns out, you can! Here are some tools that can help you cross the chasm and enter the famed machine learning world:
- Uber Ludwig: Uber’s Ludwig is a toolbox built on top of TensorFlow. Ludwig allows us to train and test deep learning models without the need to write code. All you need to provide is a CSV file containing your data, a list of columns to use as inputs, and a list of columns to use as outputs – Ludwig will do the rest. It is very useful for experimentation as you can build complex models with very little effort and in no time and you can tweak and play around with it before actually deciding to implement it into code.
- KNIME: KNIME lets you create entire data science workflows using a drag and drop interface. You can essentially implement everything from feature engineering to feature selection and even add predictive machine learning models to your workflow this way. This approach of visually implementing your entire model workflow is very intuitive and can be really useful when working on complex problem statements.

- Orange: You do not have to know how to code to be able to use Orange to mine data, crunch numbers and derive insights. You can perform tasks ranging from basic visualization to data manipulation, transformation, and data mining. Orange has lately become popular among students and teachers due to its ease of use and the ability to add multiple add-ons to complement its feature set.
There are a lot more interesting free and open-source software that provide great accessibility to do machine learning without writing (a lot of) code.
On the other side of the coin, there are some paid out-of-the-box services you can consider, such as Google AutoML, Azure Studio, Deep Cognition, and Data Robot.
2. Open Source Machine Learning Tools for Model Deployment
Deploying machine learning models is one of the most overlooked yet important tasks you should be aware of. It will almost certainly come up in interviews so you might as well be well-versed with the topic.
Here are some frameworks that can make it easier to deploy that pet project of yours to a real-world device.
- MLFlow: MLFlow is designed to work with any machine learning library or algorithm and manage the entire lifecycle, including experimentation, reproducibility, and deployment of machine learning models. MLFlow is currently in alpha and has 3 components – tracking, projects, and models.

- Apple’s CoreML: CoreML is a popular framework that can be used to integrate machine learning models into your iOS/Apple Watch/Apple TV/MacOS app. The best part about CoreML is that you don’t require extensive knowledge about neural networks or machine learning. A win-win!
- TensorFlow Lite: TensorFlow Lite is a set of tools to help developers run TensorFlow models on mobile (Android and iOS both), embedded, and IoT devices. It is designed to make it easy to perform machine learning on devices, “at the edge” of the network, instead of sending data back and forth from a server.
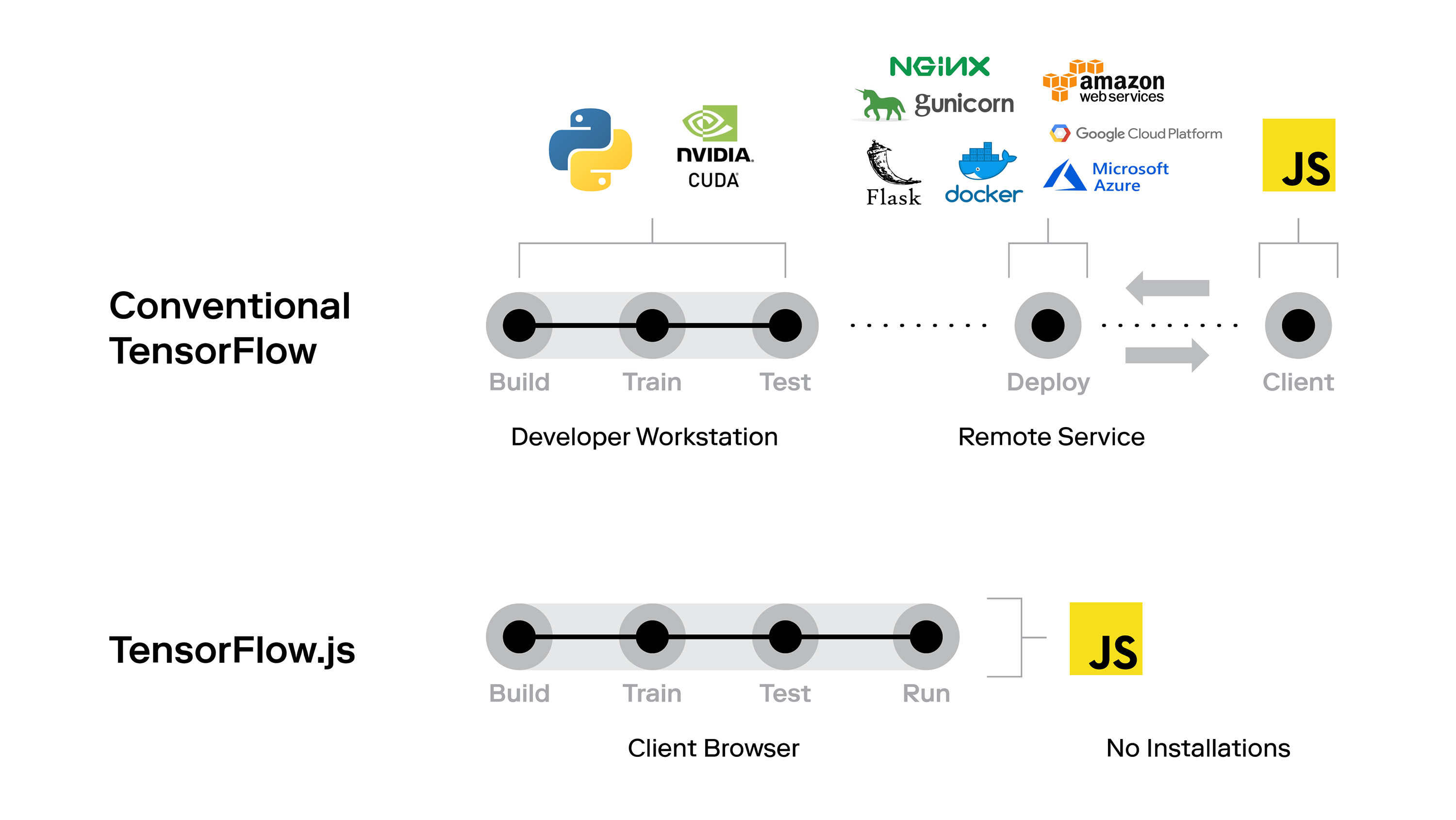
- TensorFlow.js – TensorFlow.js can be your go-to choice for deploying your machine learning model on the web. It is an open-source library that lets you build and train machine learning models in your browser. It’s available with GPU acceleration and also automatically supports WebGL. You can import existing pre-trained models and also re-train entire existing machine learning models in the browser itself!
3. Open Source Machine Learning Tools for Big Data
Big Data is a field that treats ways to analyze, systematically extract information from, or otherwise, deal with datasets that are too large or complex to be dealt with by traditional data processing application software. Imagine processing millions of tweets in a day for sentiment analysis. This feels like a humongous task, doesn’t it?
Don’t worry! Here are some tools that can help you work with Big Data.
- Hadoop: One of the most prominent and relevant tools for working with Big Data is the Hadoop project. Hadoop is a framework that allows for the distributed processing of large datasets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage.
- Spark: Apache Spark is considered as a natural successor to Hadoop for big data applications. The key point of this open-source big data tool is that it fills the gaps of Apache Hadoop concerning data processing. Interestingly, Spark can handle both batch data and real-time data.
- Neo4j: Hadoop may not be a wise choice for all big data-related problems. For example, when you need to deal with a large volume of network data or graph related issues like social networking or demographic pattern, a graph database may be the perfect choice.

4. Open Source Machine Learning Tools for Computer Vision, NLP, and Audio
“If we want machines to think, we need to teach them to see.”
– Dr. Fei-Fei Li on Computer Vision
- SimpleCV: You must have used OpenCV if you’ve worked on any computer vision project. But have you ever come across SimpleCV? SimpleCV gives you access to several high-powered computer vision libraries such as OpenCV – without having to first learn about bit depths, file formats, color spaces, buffer management, eigenvalues, or matrix versus bitmap storage. This is computer vision made easy.

- Tesseract OCR: Have you used creative apps that let you scan documents or shopping bills by using the camera of your smartphone or deposit money in your bank account by just taking a picture of a cheque? All such applications use what we call an OCR or Optical Character Recognition software. Tesseract is one such OCR engine that has the ability to recognize more than 100 languages out of the box. It can be trained to recognize other languages as well.
- Detectron: Detectron is Facebook AI Research’s software system that implements state-of-the-art object detection algorithms, including Mask R-CNN. It is written in Python and powered by the Caffe2 deep learning framework.

- StanfordNLP: StanfordNLP is a Python natural language analysis package. The best part about this library is that it supports more than 70 human languages! It contains tools that can be used in a pipeline to
- Convert a string containing human language text into lists of sentences and words
- Generate base forms of those words, their parts of speech and morphological features, and
- Give a syntactic structure dependency parse

- BERT as a Service: All of you NLP enthusiasts would have already heard about BERT, the groundbreaking NLP architecture from Google, yet you probably haven’t come across this very useful project. Bert-as-a-service uses BERT as a sentence encoder and hosts it as a service via ZeroMQ, allowing you to map sentences into fixed-length representations in just two lines of code.
- Google Magenta: This library provides utilities for manipulating source data (primarily music and images), using this data to train machine learning models, and finally generating new content from these models.
- LibROSA: LibROSA is a Python package for music and audio analysis. It provides the building blocks necessary to create music information retrieval systems. It is used a lot in audio signal preprocessing when we are working on applications like speech-to-text using deep learning, etc.
Open Source Tools for Reinforcement Learning
RL is the new talk of the town when it comes to Machine Learning. The goal of reinforcement learning (RL) is to train smart agents that can interact with their environment and solve complex tasks, with real-world applications towards robotics, self-driving cars, and more.
The rapid progress in this field has been fueled by making agents play games such as the iconic Atari console games, the ancient game of Go, or professionally played video games like Dota 2 or Starcraft 2, all of which provide challenging environments where new algorithms and ideas can be quickly tested in a safe and reproducible manner. Here are some of the most useful training environments for RL:
- Google Research Football: Google Research Football Environment is a novel RL environment where agents aim to master the world’s most popular sport—football. This environment gives you a great amount of control to train your RL agents, watch the video to know more:
- OpenAI Gym: Gym is a toolkit for developing and comparing reinforcement learning algorithms. It supports teaching agents everything from walking to playing games like Pong or Pinball. In the below gif you see an agent which is learning to walk.

- Unity ML Agents: The Unity Machine Learning Agents Toolkit (ML-Agents) is an open-source Unity plugin that enables games and simulations to serve as environments for training intelligent agents. Agents can be trained using reinforcement learning, imitation learning, neuroevolution, or other machine learning methods through a simple-to-use Python API.

- Project Malmo: The Malmo platform is a sophisticated AI experimentation platform built on top of Minecraft, and designed to support fundamental research in artificial intelligence. It is developed by Microsoft.
End Notes
As it must have been evident by the above set of tools that open source is the way to go when we consider data science and AI-related projects. I have probably just scratched the tip of the iceberg but there are numerous tools available for a variety of tasks that make life easier for you as a data scientist, you just need to know where to look.
In this article, we have covered 5 interesting areas of data science that no one really talks much about ML without code, ML deployment, Big data, Vision/NLP/Sound and Reinforcement learning. These 5 areas, I personally feel have the most impact when the real-world value of AI is taken into account.
What are the tools that you think should have been on this list? Write your favorites below for the community to know!
Sanad is a Senior AI Scientist at Analytics Vidhya, turning cutting-edge AI research into real-world Agentic AI products. With an MS in Artificial Intelligence from the University of Edinburgh, he’s worked at top research labs tackling multilingual NLP and NLP for low-resource Indian languages. Passionate about all things AI, he loves bridging the gap between deep research and practical, impactful products.






Very insightful and a crisp gist !!
Hey Preeti, I'm glad you found this article useful!
Hello :) Nice list. I would like to see more tools , it is hard to find them though. some hard tasks are : LINT and debug data processing, pre processing and analysis automated code analysis tools - ml visualisation of code , etc. any dimension transcending tools - allowing multiplexing or demultiplexing of dimensions in ML data, like 2d input to 3d output, linear text to sets of 2d arrays etc. polynomial decomposition and root finding tools - it is very usefull to express NN into sets of LFSR (linear feedback shift register) defined polynomials as this is what is easy to be encoded straight into chips. weights can be very long, and defined by structure of LFSR. while only military can order big wafers packed with LFSR's trained on a cluster, amateurs can still use FPGA's wchich have enough capacity nowadays to allow fairly complex tasks. associative arrays extraction tools - associative arrays can be implemented on fairly simple hardware (and clusters) and their design can be pre defined to follow specific axioms, wchich makes them not only debug-able but also semantical. most datasets and NN can be translated into associative array, given proper toolset. CAM tools for circuit design - most tools are proprietary, but few simple opensource tools can be reached. sorry for bit chaotic set , writting from travel :) greetings