This article was published as a part of the Data Science Blogathon.
Introduction
This article focuses on the high paced growing field of Artificial Intelligence and its implementation in the real-time world based on two papers. It talks about the recognition process of license plate characters using Machine Learning (ML) and Deep Learning (DL). The techniques used are k-Nearest Neighbors (kNN) and Convolutional Neural Network (CNN) respectively.
Thus, performance, result, and methodology are discussed. Each of the 36 characters is trained using these algorithms in different environments. Accuracy is extracted from the training and testing data. This autonomous system is used in traffic monitoring for recognizing the license plate of vehicles. The by-product also includes usage in crime investigations, surveillance systems, toll, and parking lot management. Hence, this system can aid in tracking the vehicle owners’ identities and charge them accordingly based on the violation.
(Picture Courtesy: References)

Region Clustering
CHALLENGES of LICENSE PLATE RECOGNITION
In recent years, this technology of license plate recognition is getting implemented at a fast pace. All these use-cases are implied in real-time environments replacing the human eye with computer vision. This raises problems such as
a) motion blurred effect due to fast-paced vehicle
b) excessive light due to external headlights/reflections
c) poor illumination due to night time or broken street lights
d) plate contamination due to malfunctioning street/building lights
e) low resolution due to dust/rain/hardware
f) tilted image due to camera angle
g) character contours like various font style/size
h) segmentation level due to plate background/texture/natural light
i) similar characters such as D-0-Q-U, 2-Z, S-5, B-8–3, and C-G

Some Challenges after capturing an image of License Plate
Since there is no way to control these environmental factors, we have to ensure the algorithm prediction is accurate and robust enough to handle. As read both the techniques yielded almost the same accuracy around 87%. But it is expected to improve the accuracy as much as possible because it can lead to the false acquisition of citizens for acts they didn’t commit. Hence, both the papers try to increase accuracy by using Contour and Segment extraction methods respectively.
ALGORITHM
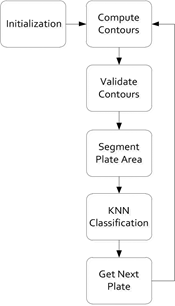
kNN Flowchart
Contour extraction is used for classification in [1] using the kNN technique of ML. After getting the plate image, the contours of the plate are computed. If found valid depending on their size, the plates are segmented into detected contour. These contours are classified using kNN. kNN is the easiest and widely used classification algorithm. In kNN, the training data set is stored in an array/vector. These attributes stored consist of independent variables. Whenever classification is required, a varying combination of these attributes is generated to form a dependent variable. These dependent variables are stored in various categoric classes.
If a variable doesn’t belong to any class then kNN is used. So, classification is done by taking k samples of known classes. These samples are compared with their neighbors by taking distances on similar parameters. These distances could be Euclidean, Manhattan or Minkowski known as weights. In this paper, k = 1 where only one neighbor is identified. ‘k’ is the number of neighbors taken into consideration for classification. Classification can be done based on either distance or number of samples belonging to a class. But this method leads to overfitting when k = 1, and is hence susceptible to noise. Whereas in the case of k = T, over smoothing or underfitting is observed where T is maximum samples.
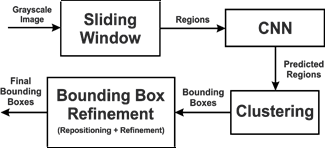
CNN Flowchart
The segmentation method is used in [2] to perform character recognition in CNN of DL. This is detected using CNN and a sliding window (SW) for refinement. SW feeds regions to CNN for detection. And CNN distinguishes between character and non-character region. This creates refined fixed size bounding boxes to increase accuracy for segmentation. Character segmentation is a key feature because the real-time environment contains defective inks, noises, angled orientation, and illumination.
In CNN, weights and biases are assigned to various aspects of the image. This helps in differentiating images from others through a network of layers. After acquiring an image, the grayscale of that image is taken and fed to the SW. This fixed box detects various regions from the image and forwards it to CNN for prediction. The classification of bounding boxes region is done by the clustering algorithm.
Clustering involves the grouping of data with similar attributes. CNN is developed from two-dimensional data in Multi-Layer Perceptron (MLP). CNN has two steps, feedforward, and backpropagation for the learning process. There are hidden layers to filter images using Rectified Linear unit (ReLU) convolution.
METHODOLOGY
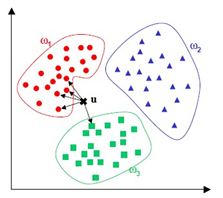
2-D kNN Clustering of Classes
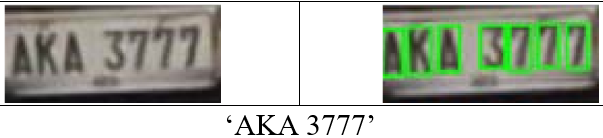
Character separation based on Contour
In [1], the contour extraction process is followed for plate recognition. After obtaining the plate image, contours are computed for validation of sized characters from an image. Then the plates are segmented into respective contours. Using the kNN algorithm, the classification of characters is done. This is done by assigning a class to 36 different alphanumeric characters consisting of 26 letters and 10 digits. All these characters of different contours are used as a training set of standard font.
Each contour is assigned a class. Multiple training data were assigned to improve accuracy but limited the amount of training to reduce computational time. This was done by increasing instances. With the use of localized plate images, testing and validation was carried out. By detecting contours the characters were separated from each other after resizing the plate image.
If the detected contour falls under any class then it was subjected to classification by kNN. By use of Euclidean distance, the attributes were compared pixel by pixel of dimensions of the resized image. The decision for character assignment was done by majority voting of kNN. Thus, the output of the process is a string.
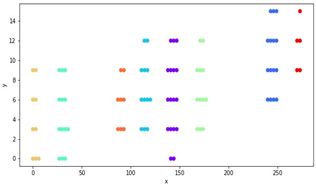
Segmentation of predicted Regions

Obtaining a single bounded box from each cluster
CNN algorithm is used in [2] to predict segmented regions with an SW to detect the presence of characters. These are then classified by the clustering technique. The SW is a technique to extract a region from an image matrix. In this paper window size of 25*60 is used to extract over a 94*300 image. These 3174 extracted regions are fed to CNN for classification of character or non-character regions.
Three convolution layer filters along with the ReLU activation function which has 128 neurons are set there. Out of which 2 neurons are with Softmax function. Where softmax function is logistic function generalizing multiple dimensional data to probabilities summing to be 1. This resulted in many regions detected as characters due to multiple centroids. Hierarchical Agglomerative Clustering (HAC) was applied to separate these centroids.
HAC is a bottom-up approach determining the distances between these centroids for elimination. This elimination was done based on the minimum distance set for every sub-cluster. After the bounding box of characters is fixed, refinement by setting average limits to boxes. It is done to avoid bad precision leading to bad segmentation. And for refinement shrinking and expanding concept is used on coordinates of boxes.
INFERENCE
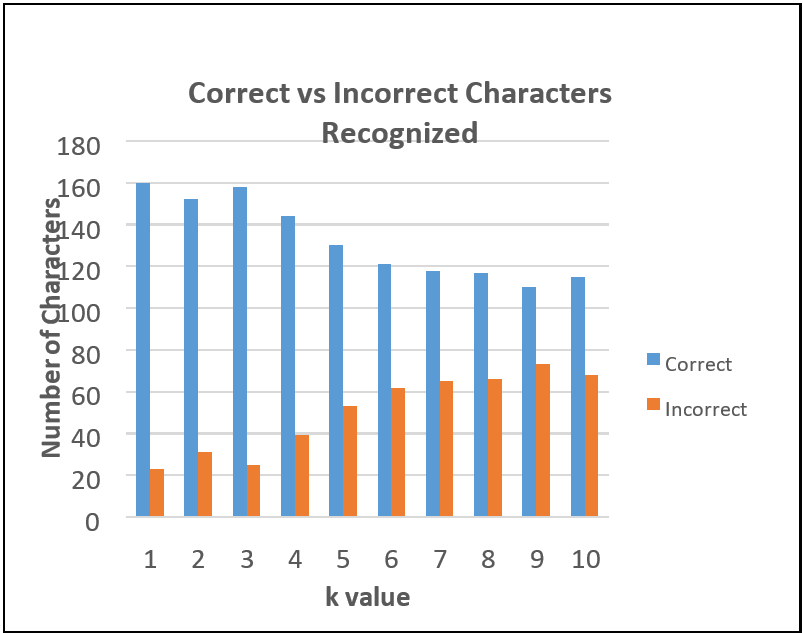
In [1] the technique achieved 87.43% accuracy after experimenting on 30 license plates containing 183 characters. It was observed that the increasing value of k decreased the accuracy of character recognition. The results were maximum at k = 1 (1NN). Compared with the Artificial Neural Network (ANN), the accuracy obtained was 86.34%. For being fit for real-time systems, processing at 30 fps is required minimum. So, this system runs at 0.034 seconds per frame which is near to the required rate.
However, few frames exceeded the maximum limit but were compensated by the fast processing of other frames. Thus, here kNN was used as a classifier to compute the classification of the extracted contours. This is done by finding the Euclidean distance between the attributes of the training and validation data set. This data set was nothing but the matrix of pixels from input images fed to the algorithm through the camera. The process starts by segmenting the plate image into individual characters.
These characters are separated by bounding boxes. These boxes were subjected to classification in the kNN algorithm with the help of a template training data set. Moreover, the accuracy of both the system remains the same practically. So, the kNN was at par with accurate pre-existing techniques.
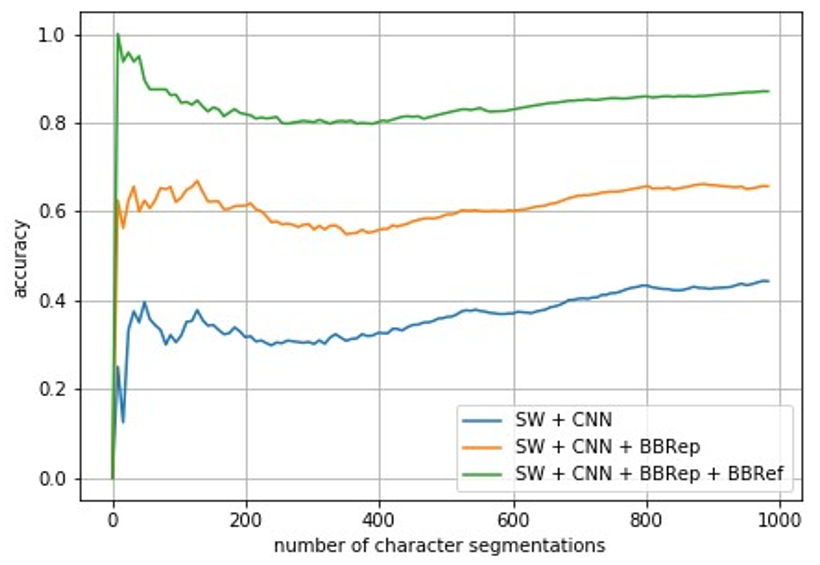
We read accuracy of 87.06% in [2] technique. They segmented characters to detect plates using CNN and SW with bounding box refinement. The model was tested against 138 license plates containing 982 characters of which 855 characters successfully segmented. So, we can rely more on this technique than kNN as it was only tested against 30 images. CNN was used to distinguish the character and non-character regions. The SW with a 2-pixel stride was used to extract regions.
These extracted regions were fed to the CNN model with probability output based on two classes. The threshold was set to 0.95 for the character value class. To perform HAC, clustering was done for potential ground truth. Single box from mean values of x and y coordinates of bounding box was taken and refinement was done. The bounding box was determined as true segmented if the Intersection over Union (IoU) value exceeded 0.75.
IoU is the ratio of the area of the intersection to the union. Three combinations were tested SW and CNN which yielded an accuracy of 44.29%. But by adding bounding box repositioning (BBRep), accuracy increased to 65.68%. And finally after adding refinement (BBRef) accuracy was 87.06% with 855 successful segmentations. Hence, IoU shifted to higher values after adding repositioning and refinement.
REFERENCES
[1] A. R. F. Quiros et al., “A kNN-based approach for the machine vision of character recognition of license plate numbers,” TENCON 2017–2017 IEEE Region 10 Conference, Penang, 2017, pp. 1081–1086, doi: 10.1109/TENCON.2017.8228018.
[2] A. T. Musaddid, A. Bejo and R. Hidayat, “Improvement of Character Segmentation for Indonesian License Plate Recognition Algorithm using CNN,” 2019 International Seminar on Research of Information Technology and Intelligent Systems (ISRITI), Yogyakarta, Indonesia, 2019, pp. 279–283, doi: 10.1109/ISRITI48646.2019.9034614.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.




Where I can get a source code to test it. Like GitHub link or anything else