This article was published as a part of the Data Science Blogathon.
What we want is a machine that can learn from experience. — Alan Turing
There’s been enough advancement in the field of Computer Vision. We have now some state-of-the-art image classifiers, object detectors, text detection models, etc. so someone had to explore the other areas of the field, one of those areas concerns GANs. The first example of GAN was written by Ian Goodfellow after returning from a pub (imagine the productivity of the guy 😂).
Now on Instagram and Facebook, we see some black and white images being coloured and some old images being moved, that is the magic of GANs which can generate some whole new images/videos that we have never seen before but we can not question its reality.
So to have a friendly introduction let’s talk GANs.
Get ready to ignite your passion at the highly anticipated DataHack Summit 2023! Join us from August 2nd to 5th at the prestigious NIMHANS Convention Center in vibrant Bengaluru. Brace yourself for a data extravaganza like no other! Prepare to be blown away by mind-blowing workshops that will expand your knowledge, gain invaluable insights from industry experts, and network with fellow data enthusiasts who share your passion. Stay one step ahead of the game, stay in the loop on the latest trends, and unlock boundless possibilities in the world of data science and AI. Mark your calendars, secure your spot, and get ready for an unforgettable experience at the DataHack Summit 2023. Click here for more details!
What are GANs?
We all heard of RNNs, that is also used as text generator and can generate one word or one letter at a time. Can this thing be done for images? Yes, there are techniques like Fully Visible Belief Networks (later renamed as Auto-Regressive Models) that generate one pixel at a time which can lead to a fully generated image (looks real but is not). but is there any way of generating the whole image in one shot? The answer is yes again. GANs are the models used for generating an entire image at a time.
How GANs Work?
GANs are made up of two different components Generator and Discriminator. In Generative Adversarial Networks, Adversarial means opposite or in another way Generator and Discriminator are in competition with each other in order to produce realistic images.
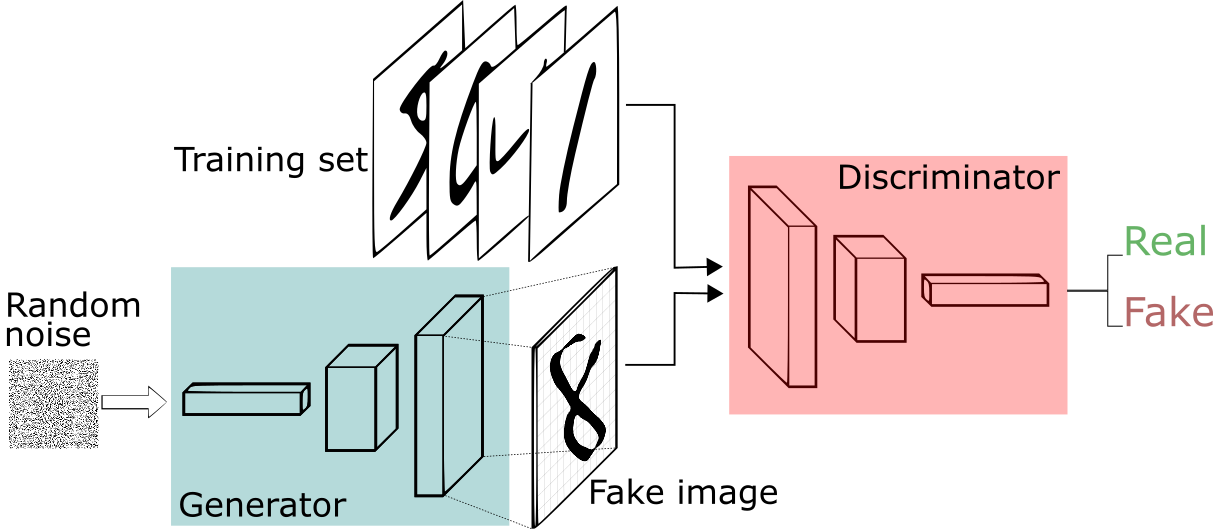
The Generator is a neural network that uses a differentiable function, it takes random noises as input and passes those noises through the differentiable function, and transforms/reshapes them in order to make them recognizable. It tries to produce real images which are totally dependent on the input noises. But the question is how this generator produces the right image? It should be trained first in order to produce realistic images right?
The training process of GANs is different from that of CNNs, where we train the model on multiple images along with their output classes, in GANs there is no output associated with each input image. We just show the model a bunch of images and ask the model to produce some new images that come from the same probability distribution.
So we pass random noises through Generator Network that produces the output images by selecting features from the input set. There is another network used by GANs called Discriminator, which guides the Generator if the produced image is real or not. The Discriminator is a regular neural network that just does the classification task. It is trained with half of the real images and half of the fake (generated) images where real images are assigned the probability near 1 while fake images are assigned probability near 0.
Meanwhile, the Generator is trained just the opposite, it tries to generate the images where Discriminator would assign it to near 1. Over a span of time Generator is forced to produce more realistic images which can easily fool Discriminator.
Is GANs Training Similar To CNNs?
Normal CNNs have some loss/cost function that it wants to minimize in order to improve the accuracy, for that we change the parameters which lead to the optimal weights. Training GANs is somewhat similar to CNN’s but with some major changes, here we have two loss/cost functions associated with both Generator and Discriminator, these Loss functions are opposite to each other. The whole training process of GANs can be explained by the value function where Generator wants to minimize its value function, and Discriminator wants to maximize its value function.

We can easily understand the value function using Saddle Point.
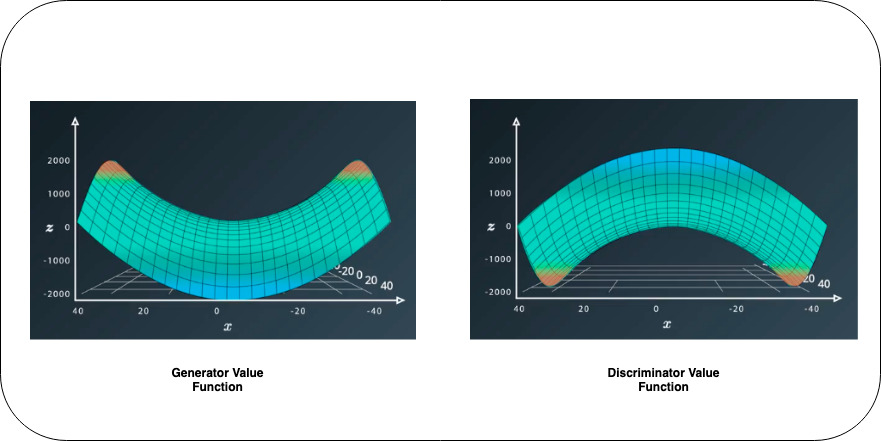
When you see the Generator Value Function we reach the optimal point by going to the minimum of the saddle while for Discriminator we achieve the same by going at the top (maximum peak) of the reverse saddle. This explains that for GANs training we need to have two optimization techniques for both Generator and Discriminator, which would work simultaneously.
There is no Convolution or Recurrent layer used for its training, it’s just matrix multiplication followed by activation functions (leaky relu, tanh, and sigmoid being most preferable). For better training, we should have at least one hidden layer for both Generator and Discriminator. And preferred optimizer for GANs is the Adam optimizer.
Application of GANs:
GANs are used in several places, currently, they are just being used as a fun activity but more serious use can be seen in the future. Currently, GANs are used in the following use cases:
1. Generate Cartoon Characters: Using GANs one can generate cartoon characters by just passing random noises, those characters look something like the one that Graphics Designer would make – https://github.com/mnicnc404/CartoonGan-tensorflow
2. Image to Image Translation: Using one normal image to generate the cartoonized/artistic paintings or vice versa – https://github.com/phillipi/pix2pix
3. Face Aging: This is something that you might have seen a lot on social media apps, where one can convert the images to younger or older selves – https://github.com/ZZUTK/Face-Aging-CAAE
4. Image Colourisation: Using GANs, black and white images are being converted to colored images – https://github.com/jantic/DeOldify
5. Image to Live Video: It can convert still images to short videos with some algorithmic tweaks.
6. 3D object Generation: Just like a 2D image GANs are also capable of generating 3D videos.
For more use-cases you can check out this exciting blog:
https://machinelearningmastery.com/impressive-applications-of-generative-adversarial-networks/
Hey there! There’s something truly special just for you before you head out. Brace yourself for a mind-blowing data adventure at the DataHack Summit 2023. We’ve curated an incredible lineup of workshops that will revolutionize your data game! From Mastering LLMs: Training, Fine-tuning, and Best Practices, Exploring Generative AI with Diffusion Models to Build Scalable Machine Learning Model (and many more), these workshops are an absolute game-changer. Picture yourself diving into immersive, hands-on experiences that will equip you with practical skills and real-world knowledge, ready to be applied immediately. This is your chance to connect with industry leaders, forge valuable connections, and unlock exciting career opportunities. Grab your spot now and secure your place at the highly anticipated DataHack Summit 2023.
Resources
There are some research papers that you can go through for the mathematical understanding of the GANs, one of them is written by the creator of GANs.
- Generative Adversarial Nets Paper: https://arxiv.org/pdf/1406.2661.pdf
- Improved Techniques for Training GANs: https://video.udacity-data.com/topher/2018/November/5bea0c6a_improved-training-techniques/improved-training-techniques.pdf
in the next one, we would use GAN to generate images using python and torch.
References
Udacity Deep Learning: https://www.udacity.com/
Thanks for reading this article do like if you have learned something new, feel free to comment See you next time !!! ❤️
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.
Applied Machine Learning Engineer skilled in Computer Vision/Deep Learning Pipeline Development, creating machine learning models, retraining systems, and transforming data science prototypes to production-grade solutions. Consistently optimizes and improves real-time systems by evaluating strategies and testing real-world scenarios.


