This article was published as a part of the Data Science Blogathon.
In the last article A Friendly Introduction to KNIME Analytics Platform I provided a brief insight into the open-source software KNIME Analytics Platform and what it is capable of. With the help of a customer segmentation example, I showed the general functions of KNIME Analytics Platform.
This article takes up a topic that was briefly mentioned at the end of the last article: Components. I’ll provide an in-depth explanation of what components are, what functionalities they have, and why they are useful. Additionally, I’ll show you how to create and setup your very own component within a few steps.
Component vs. Metanode in KNIME
A component is not to be confused with a metanode. At first glance, they might look similar as they both incorporate a group of nodes. However, the only purpose of metanodes is to visually improve your workflow by collapsing logical groups of nodes. This gives the workflow a clearer structure, which is especially helpful when sharing the workflow with your peers.
Components on the other hand have sophisticated characteristics, which make them a very powerful feature in KNIME Analytics Platform. They encapsulate functionalities, even very complex functionalities, that can be reused in other workflows at any time. In the following, I will highlight the aspects which differentiate a component from a metanode.
1. Components have an Interactive View
First of all – what is an Interactive View? There are nodes in KNIME Analytics Platform – View nodes, Widget nodes, and Interactive Widget nodes – that are used to visualize data, for example as charts or plots. The charts and plots these nodes create can be observed via the Interactive View. You can access it by right-clicking the node and selecting Interactive View (Fig. 1).
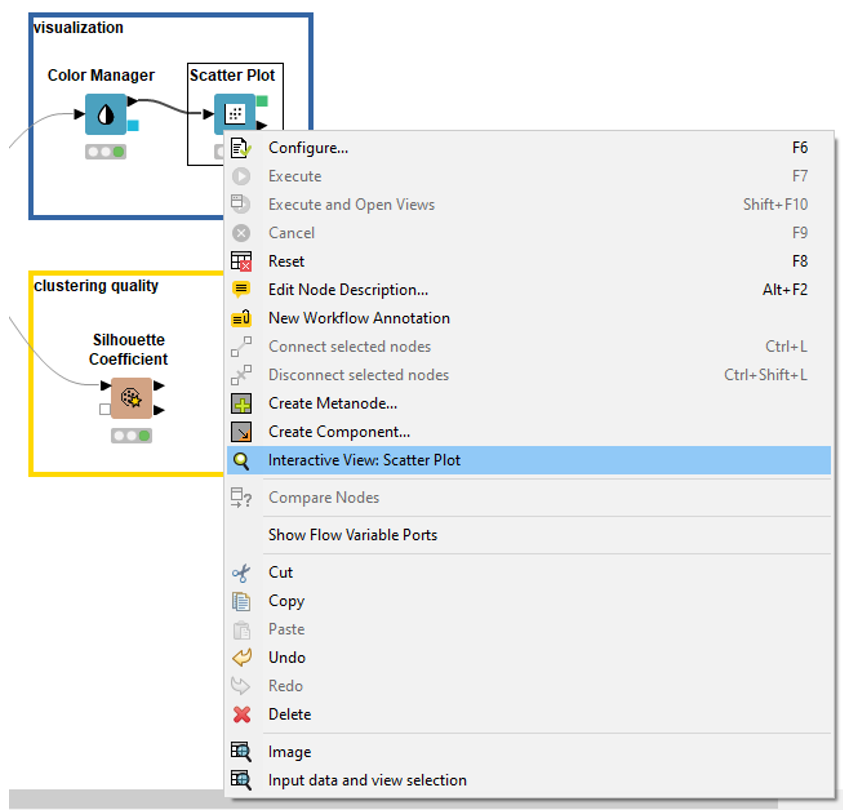
In the case of the Scatter Plot node, a separate window pops up displaying the scatter plot, where you can, for example, zoom in and out, change the attributes displayed on the x- and y-axis, or rename the plot and its axes.
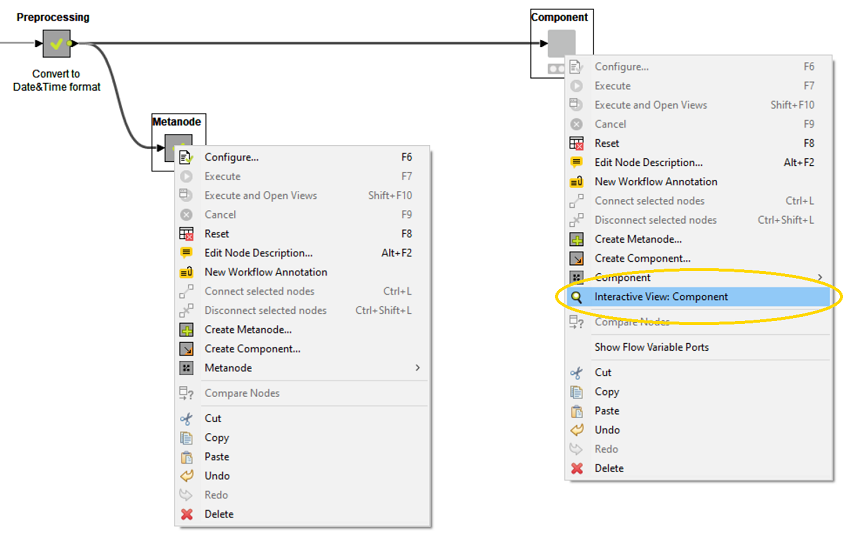
As soon as a component contains a node with an Interactive View, this interactive view becomes part of the component’s interactive view and can be accessed from a web browser when running on the KNIME Server. Metanodes, on the other hand, do not have that feature (Fig. 2).
2. Components can also have a configuration window
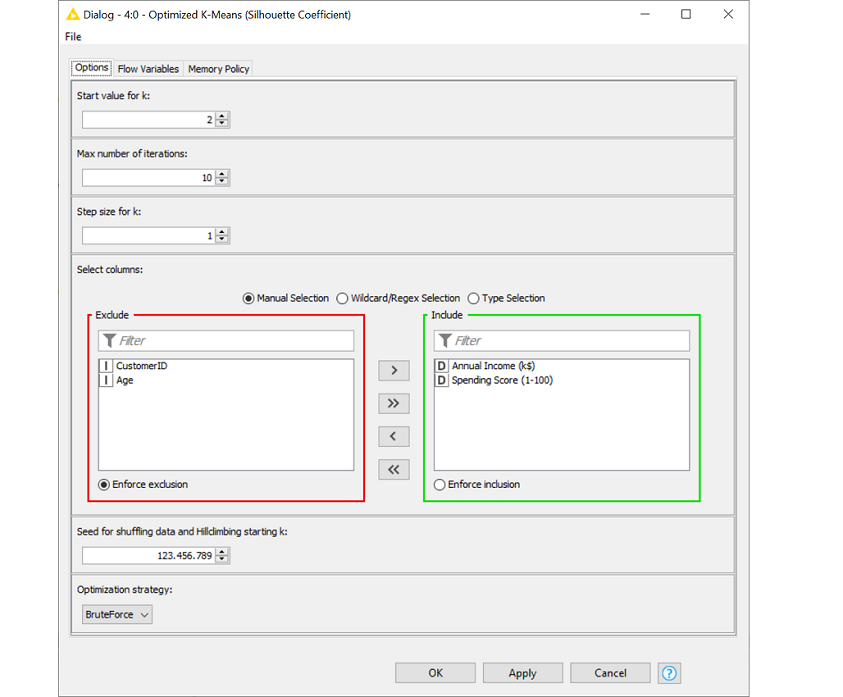
Usually, nodes in KNIME Analytics Platform need to be configured (or at least there is the option to configure the node). Components can also have a Configuration Window. It’s not necessarily required but you have the option to create a configuration window for your component. You can place configuration nodes inside your component, which enable a configuration window for the component. This means you can change the parameters of the component without changing the setting of the nodes inside the component. Fig. 3 shows the configuration dialog of the Optimized k‑Means (Silhouette Coefficient) component, which I already introduced in the previous article and can be accessed via the KNIME Hub. It’s comparable with the configuration window of a KNIME node. Metanodes can’t be configured.
3. Components can enclose flow variables
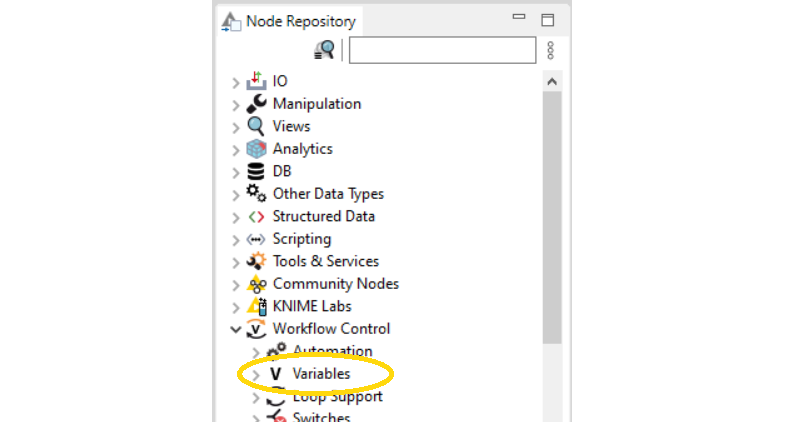
You may ask yourself: What are flow variables? Flow variables are parameters that can be of any data type (e.g., string, integer, etc.). They are used to automatically update specific settings of a node. For example, if you need to always filter a dataset on the current date, use a flow variable. A flow variable of data type Date&Time updated at every workflow execution with the current date can be used to overwrite the setting of the filter node. You find all sorts of flow variable nodes in the Node Repository under the Workflow Control category (see Fig. 4).
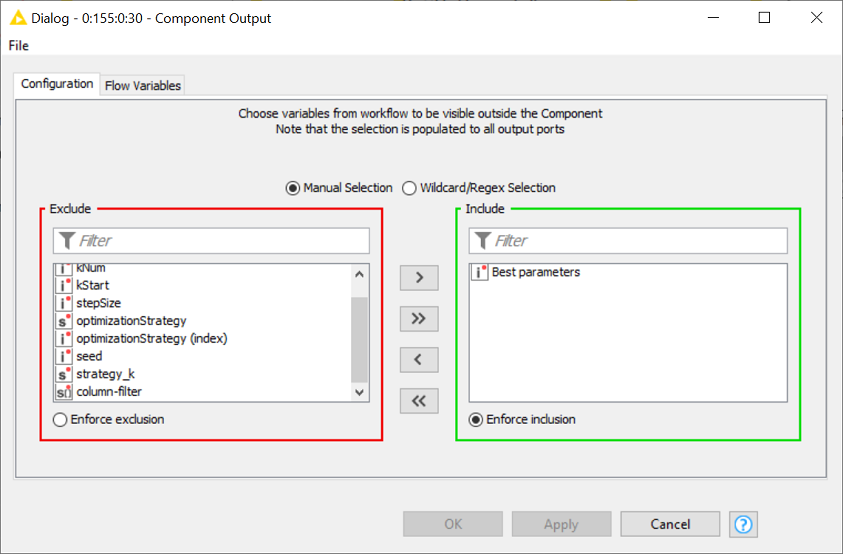
In general, flow variables are automatically transmitted to the downstream nodes. This is also applicable when collapsing some nodes into a metanode. For components, however, it is different. Flow variables created inside a component stay inside the component – unless you specifically want them to be accessed from the outside. In this case, double-click the Component Output and move the respective variable(s) to the Include panel (Fig. 5). You have to do the same in the Component Input node to allow external flow variables to enter the component.
To learn more about flow variables and workflow control in general, have a look at the KNIME Documentation.
4. Components can be shared
One last thing to say – components can be reused and shared with others. The component template can be stored somewhere and a linked instance created by drag&drop of the component template into the workflow editor. The component can then be used like any other KNIME node. Whenever the workflow is opened, a check is carried out to see if any updates have been made in the component template.
To store the component template, you need to right-click the component and select Component >> Share…, then a window pops up asking for the destination for the component template. There are three possible destinations:
1. Local Workspace
This option allows you to save the component template to your local workspace, which makes it accessible to you only for the further usage. This is better than simply copy-pasting the component because component updates are automatically transmitted to all the linked instances.
2. KNIME Hub
You can either save the component template to your private space or to your public space on the KNIME Hub. By uploading it to your public space, other KNIME users can create a linked instance to your component. Either way, you can control the component template, by logging in to your KNIME Hub account. This makes it independent from your local installation.
3. KNIME Server
A third option is to share the component via a KNIME Server. In this case you will be able to access it from any connected KNIME Server client.
The Example: Encapsulating Functionalities of a Workflow in KNIME
Now that you’ve learned about components and their functionalities, it’s time to show you how to build one. To make things easy, let’s recall the example workflow I showed in the last article (you can download the workflow from the KNIME Hub). Here, I showed you how to cluster customer data according to the two attributes Annual Income (k$) and Spending Score (1‑100), using k-Means clustering.
Let’s now build a component, which bundles together some functionalities of that workflow, and share it to become able to reuse it in other workflows.
1. Creating the Component
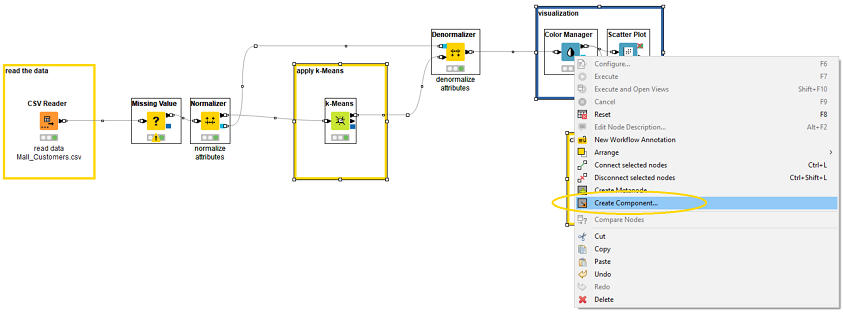
Select all the nodes you want to have inside the component. Then right-click and select Create Component… (Fig. 6). In the next step you’re asked to give the component a meaningful name.
As you can see, creating a component is not complicated at all. The important part though is setting up the component appropriately.
2. Setting up the Component
1. Component Output
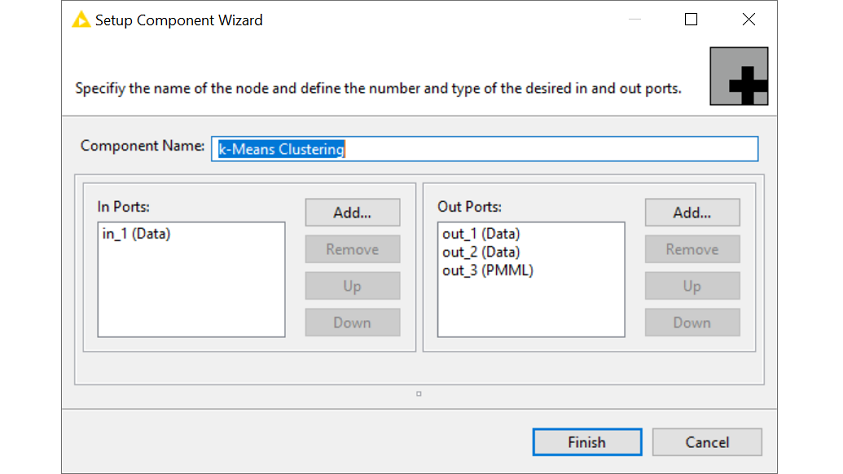
You can access the Setup Component Wizard (Fig. 7) by right-clicking the component and then selecting Component >> Setup… . Here, you can rename the component, add or remove input and output ports, and change the order of the input and output ports. Let’s add two data out ports and one PMML out port for the Cluster Model.
2. Component Description
You can access the Description panel (Fig. 8) from inside the component. Ctrl-double-click to open the component. Then the description panel is located on the right-hand side of the KNIME Workbench and is activated by default. In case you can’t see the Description panel, activate it by clicking View >> Description in the top menu. Here you can add a description, an icon and a description of the input and output ports of the component.
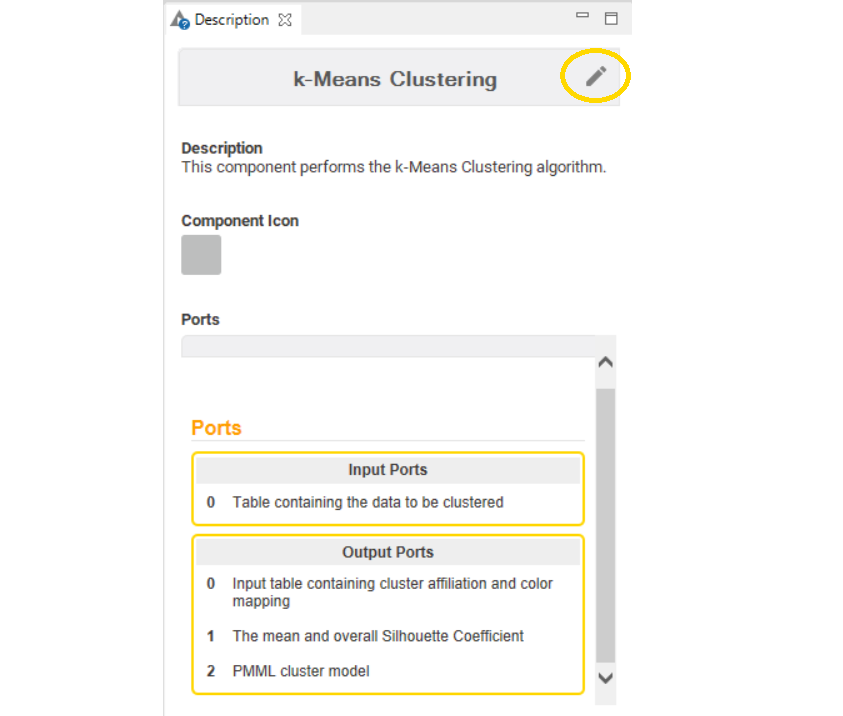
Fig. 8. The Description panel of the component. Edit by clicking the pencil in the top right corner.
3. Component Configuration Dialog
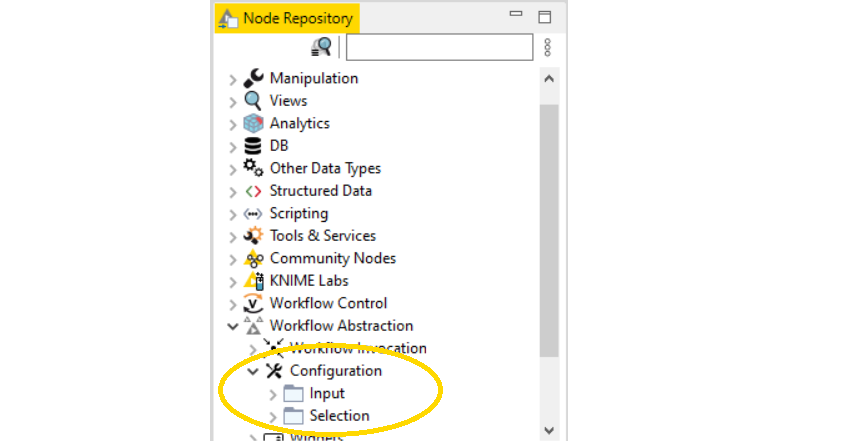
As already mentioned above, components can be configured via a configuration window. To create such a configuration window the Configuration Nodes are used which are located under the Workflow Abstraction category in the Node Repository (Fig. 9).
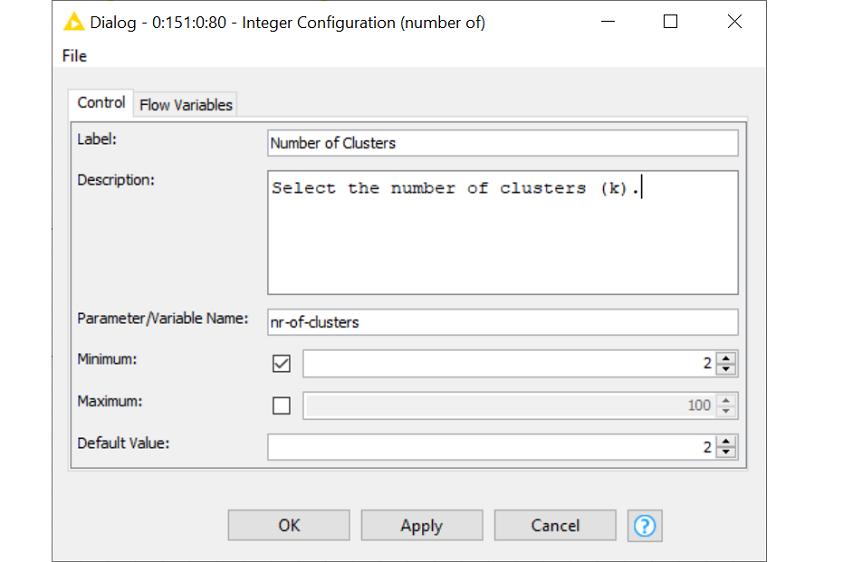
Let’s demonstrate how this works on an example. One very important parameter of the k-Means Clustering algorithm is k – the number of clusters. It makes sense to have the option to adjust k from the component configuration window, without changing the settings of the k-Means node inside the component. We do this with the Integer Configuration node. In the configuration window of the node (Fig. 10), you can label and describe the option, give the variable a name and you can define a minimum and a maximum value as well as a default value.
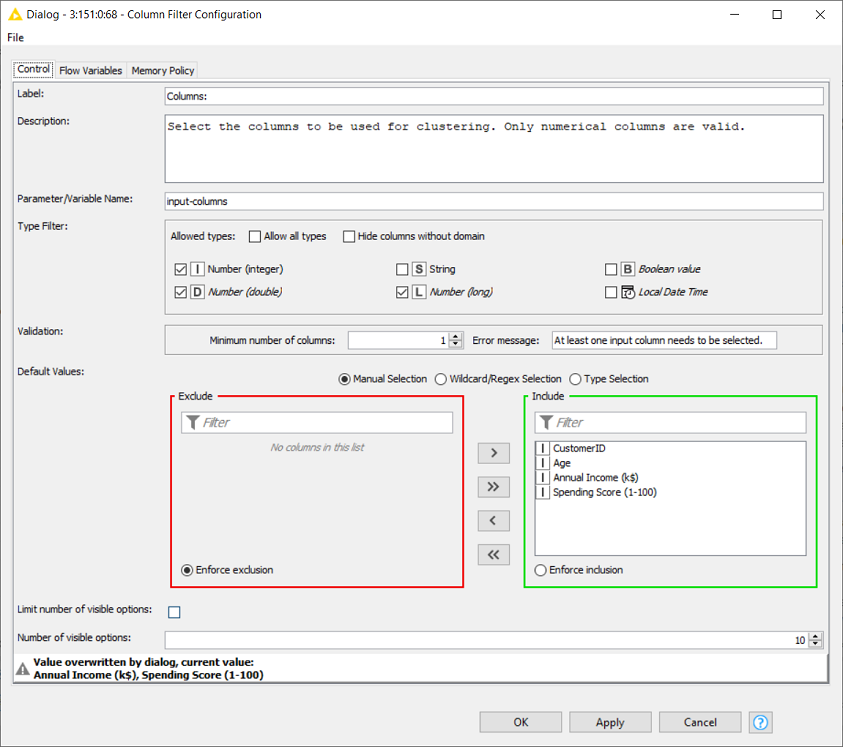
Additionally, we want our component to be generalizable to different input data. Depending on the data, it’s not always feasible to include all attributes for clustering because some attributes won’t affect the clustering (e.g., a column assigning an ID to each customer) and the k-Means Clustering algorithm generally can’t handle non-numerical data. Thus, an Include-Exclude panel in the Configuration Dialog of the component will be helpful. Using the Column Filter Configuration node (Fig. 11) enables specification of what types of inputs are allowed, or what the minimum number of required columns is.
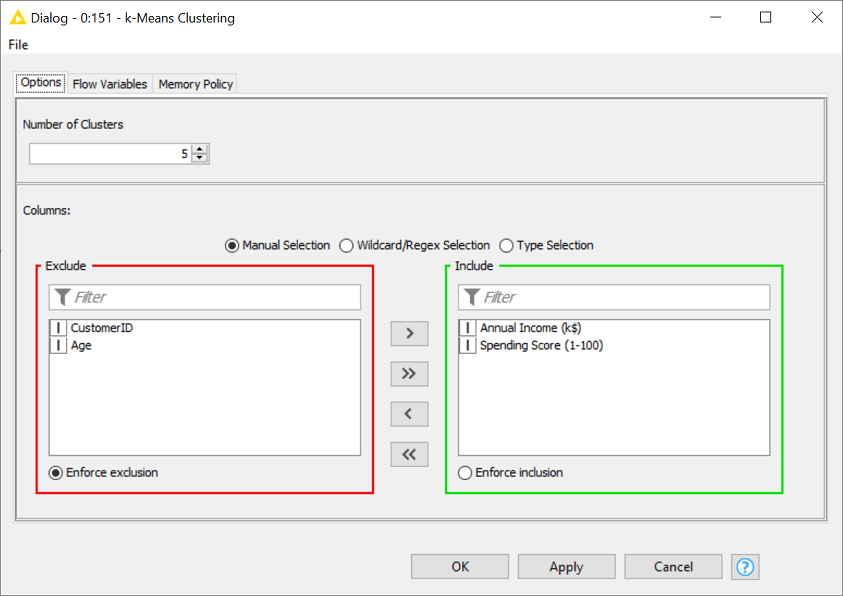
Adding these two configuration nodes leads us to the following configuration window of the component.
4. Component Composite View
The Composite View of a component contains all the Interactive Views that are part of the component. Besides placing a node with an Interactive View inside the component, nothing else needs to be done. In this example, the Scatter Plot node is placed inside the component and its view can be seen in the component composite view, upon successful execution. Go on – try it out!
Note: The layout of the Composite View can be customized, which for example becomes important when you want to create an Interactive Dashboard. But this is a topic for another time… let’s first complete this article on components before tackling new topics.
Summary of our KNIME Article
Components are a powerful feature of KNIME Analytics Platform. Indeed, if a node you need is missing, you could build it yourself. If you cannot code, you can create your new node via a component. A component is the natural evolution of a metanode.
All the more it is important to understand how component differentiates from metanodes and how to take advantage of all the functionalities a component can have.
With this article, I tried to give you a brief insight into the topic of components within KNIME Analytics Platform. The example showed in this article containing the component can be downloaded from the KNIME Hub.
If you wish to learn more about components and KNIME Analytics Platform, check out the KNIME Documentation or the learning materials on our KNIME site.






