In deep learning, the activation functions are one of the essential parameters in training and building a deep learning model that makes accurate predictions. Choosing the best appropriate activation function can help one get better results with even reduced data quality; hence, activation functions should be decided according to their characteristics and behavior on the fed data. The sigmoid function derivative, for instance, is a popular choice for activation in certain layers of neural networks due to its ability to squash the output between 0 and 1, which is useful for binary classification tasks.
This article will discuss one of the most famous and used accusation functions, the sigmoid. We will calculate its derivative to understand the core intuition and working mechanism behind it, and we will also discuss the applications and advantages of the activation function.
This article was published as a part of the Data Science Blogathon
Table of contents
Sigmoid Function
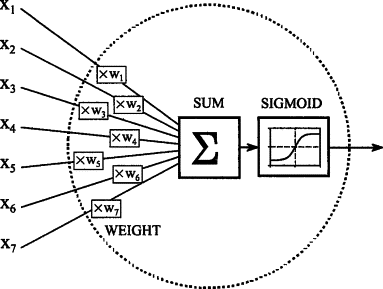
The sigmoid function is one of the most used activation functions in machine learning and deep learning. It can be used in the hidden layers, which take the previous layer’s output and bring the input values between 0 and 1. Now while working with neural networks, it is necessary to calculate the derivate of the activation function.
The formula of the sigmoid activation function is:
F(x) = σ(x) = 1 ⁄ (1 + e-x)
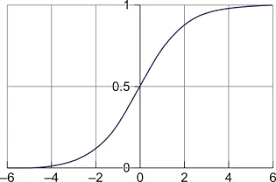
The graph of the sigmoid function looks like an S curve, where the part of the function is continuous and differential at any point in its area.
The sigmoid function, also known as the squashing function, takes the input from the previously hidden layer and squeezes it between 0 and 1. So a value fed to the function will always return a value between 0 and 1, no matter how big or small the deal is provided.
Graphically, the sigmoid function looks like this,
Also Read: How to Understand Sigmoid Function in Artificial Neural Networks?
Derivative of the Sigmoid Function
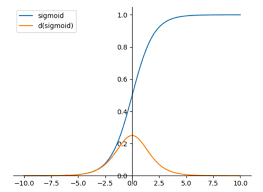
In neural networks, the weights and biases are assigned randomly in the initial stages, and the weights and biases get updated during the backpropagation in the network. During backpropagation, the algorithm calculates the derivatives, including the derivative of the activation function. The sigmoid function is the only activation function which haves its own function in its derivative.
Let’s try to derive the same.
The formula of the Sigmoid Function:
σ(x) = 1/1 + e-xStep 1: Derivation Concerning x on Both Sides.
σ(x)' = d/dx {1/(1 + e-x)}Step 2: Applying the Reciprocating Rule.
σ(x)' = d/dx ( (1/1 + e-x)-1)
σ(x)' = - 1/ (1 + e-x)2 d/dx (1+e-x)
σ(x)' = - 1/ (1 + e-x)2 d/dx (e-x)
σ(x)' = - e-x / ( 1+ e-x)2 d/dx (-x)
σ(x)' = e-x / ( 1 + e-x )The above equation is known as the derivative of the sigmoid function.
Modifying the Equation for a More Generalized Form
σ(x)' = e-x / ( 1 + e-x) ( 1+ e-x)
σ(x)' = 1/ 1 + e-x × e-x/1+e-x
σ(x)' = σ(x) × e-x/1+e-x
σ(x)' = σ(x) × ( 1 - 1/1+e-x)
σ(x)' = σ(x) ( 1- σ(x) )The above equation is known as the generalized form of the sigmoid function.
Code to Implement Sigmoid Function
One must write the following code to implement the sigmoid function in Python. The below required the value of x to be pre-defined to get the sigmoid deal out of it.
Python Code:
# Analytics Vidhya
import math
def sigmoid(x):
SigmoidFun = 1 / (1 + math.exp(-x))
return SigmoidFun
output = sigmoid(x=1)
print(output)Suppose we feed the input weights to the layers and pass the consequences and biases into the next layer. If the final output layer has a sigmoid function, we will apply it to the output, and the final result will display.
For example,
Let’s suppose the output from the hidden layer is 1; then, the value of x would be 1.
Final Output:
= 1 / 1 + e-x
= 1 / 1 + e-1
= 1/ 1 + 0.367
= 1 / 1.367
= 0.7315As we can see here, the output from the previously hidden layer was 1, and the function made it 0.7315, where it is visible that the Sigmoid Function is a Squeezing Function.
Applications of Sigmoid Function
1. Binary Classification Problems:
We can use the sigmoid function in binary classification problems as it returns the output between 0 and 1.
2. Probabilistic Models:
We can use the sigmoid function when we are required to work on a probabilistic model as it can be used to calculate the probability of a given class between 0 and 1.
3. Image Datasets and Neural Networks:
The sigmoid function can be used for neural networks on image datasets for performing tasks like image segmentations, classifications, etc.
Limitations of Sigmoid Function

1. Vanishing Gradient Problem:
One of the significant issues with the sigmoid is the lack of weight updating. Therefore, the function sometimes returns small values as outputs, making no changes in the weights and biases that cause the vanishing gradient problem.
2. Exploding Gradient Problem:
It also sometimes happens that the sigmoid returns very large values as output, resulting in an exploding gradient problem.
3. A Squeezing Function:
Some note that the sigmoid function, as a squeezing function, limits output results between 0 and 1, which hides the essence of higher and lower numbers and reduces model accuracy.
Linear vs. non-Linearly Separable Problems
- A single straight line or hyperplane can separate linear problems. These problems are relatively straightforward and linear models like logistic regression or linear SVMs can solve them.
- Non-linearly separable problems have data points from different classes intricately intertwined, requiring more complex decision boundaries.
- Neural networks excel at non-linearly separable problems due to their ability to learn complex non-linear functions through:
- Choice of activation function is crucial:
- Sigmoid function is good for binary classification but suffers from vanishing/exploding gradient problems
- Advanced activations like ReLU mitigate vanishing gradients for better training
- Limitations of sigmoid activation:
- Vanishing gradient problem
- Exploding gradient problem
- Restricted 0-1 output range limits capturing patterns in extreme values
- Neural network architectures and components like activation functions, regularization enable modeling of complex non-linear patterns across domains like:
- Image recognition
- Natural language processing
- Speech recognition
- Reinforcement learning
Conclusion
In this article, we discussed the sigmoid function and its derivative, its working mechanism, and the core intuition behind the same with its applications associated with advantages and disadvantages. Knowing these key concepts will help one better understand the mathematics behind the function and will help one answer any related interview questions efficiently.
Key Takeaway
- Sigmoid function is a squeezing function that results from the output between 0 and 1.
- The Sigmoid can be used efficiently for binary classification problems, as it returns the output between 0 and 1.
- The function sometimes returns much larger or smaller values, resulting in vanishing or exploding gradient problems.
Frequently Asked Questions
1. Why is backpropagation accessible to the sigmoid function?
Since it is the only activation function that appears in its own derivative, it helps neural networks perform the backpropagation algorithm better, as gradient descent updates the model’s weights and biases.
2. Why Sigmoid Activation function is squeezing function?
As the activation function squeezes the input values fed to the hidden layers, the function returns the output between 0 and 1. So no matter how positive or negative numbers are provided to the layer, this function squeezes it between 0 and 1.
3. What is the main issue with the sigmoid function during backpropagation?
The main issue related to the activation function is when the gradient descent algorithm calculates the new weights and biases; if these values are minimal, then the updates of the consequences and preferences will also be meager and hence, which results in a vanishing gradient problem, where the model will not lean anything.
4. What is the range of the sigmoid derivative?
The range of the sigmoid derivative is between 0 and 0, inclusive, for all real values of x.
The author uses the media shown in this article at their discretion, and Analytics Vidhya does not own it.





