Introduction
In real-time object detection, the prevailing paradigm has traditionally embraced multi-step methodologies, encompassing the proposal of bounding boxes, pixel or feature resampling, and high-quality classifier applications. While this approach has achieved high accuracy, its computational demands have often hindered its suitability for real-time applications. However, the Single Shot MultiBox Detector (SSD) represents a groundbreaking leap in deep learning-based object detection. SSD maintains exceptional accuracy while substantially improving detection speed by eliminating the need for pixel or feature resampling in the bounding box proposal stage. Instead, SSD directly predicts object categories and bounding box offsets using small convolutional filters on feature maps.
Researchers have tried to make faster detectors by optimizing different stages of this process, but it usually results in decreased accuracy. However, this paper introduces a groundbreaking deep learning-based object detector called SSD (Single Shot MultiBox Detector) that maintains accuracy while significantly improving speed. SSD achieves this by eliminating the need for resampling pixels or features for bounding box proposals. Instead, it directly predicts object categories and bounding box offsets using small convolutional filters applied to feature maps.
Learning Objectives
- Understand the principles and architecture of SSD for object detection in images and videos.
- Explore the advantages of SSD over traditional object detection models in terms of speed and accuracy.
- Grasp the concept of default bounding boxes and their role in multi-scale object detection with SSD.
- Gain insights into the diverse applications and industries benefiting from SSD’s efficient object detection capabilities.
This article was published as a part of the Data Science Blogathon.
Table of contents
- What is a Single Shot Detector (SSD)?
- Key Features of SSD
- What are the Key Concepts of SSD?
- Architecture of SSD
- How does SSD Work?
- Training of SSD Method
- Detector Outputs
- Comparisons with Other Object Detection Models
- Applications of SSDs
- Challenges and Limitations of SSDs
- Project on SSD
- Real-world Case Studies
- Frequently Asked Questions
What is a Single Shot Detector (SSD)?
A Single Shot Detector (SSD) is an innovative object detection algorithm in computer vision. It stands out for its ability to swiftly and accurately detect and locate objects within images or video frames. What sets SSD apart is its capacity to accomplish this in a single pass of a deep neural network, making it exceptionally efficient and ideal for real-time applications.

SSD achieves this by employing anchor boxes of various aspect ratios at multiple locations in feature maps. These anchor boxes enable it to handle objects of different sizes and shapes effectively. Moreover, SSD uses multi-scale feature maps to detect objects at various scales, ensuring that both small and large objects in the image are accurately identified. With its proficiency in detecting multiple object classes simultaneously, SSD is a valuable tool for tasks that involve numerous object categories in a single image. Its balance between speed and accuracy has made it a popular choice in applications such as pedestrian and vehicle detection, as well as broader object detection in fields like autonomous driving, surveillance, and robotics.
SSD is known for its ability to perform object detection in real-time and has been widely adopted in various applications, including autonomous driving, surveillance, and augmented reality.
Key Features of SSD
- Single Shot: Unlike some traditional object detection models that use a two-stage approach (first proposing regions of interest and then classifying those regions), SSD performs object detection in a single pass through the network. It directly predicts the presence of objects and their bounding box coordinates in a single shot, making it faster and more efficient.
- MultiBox: SSD uses a set of default bounding boxes (anchor boxes) of different scales and aspect ratios at multiple locations in the input image. These default boxes serve as prior knowledge about where objects are likely to appear. SSD predicts adjustments to these default boxes to locate objects accurately.
- Multi-Scale Detection: SSD operates on multiple feature maps with different resolutions, allowing it to detect objects of various sizes. Predictions are made at different scales to capture objects at varying levels of granularity.
- Class Scores: SSD not only predicts the bounding box coordinates but also assigns class scores to each default box, indicating the likelihood of an object belonging to a specific category (e.g., car, pedestrian, bicycle).
- Hard Negative Mining: During training, SSD employs harmful mining to focus on challenging examples, improving the model’s accuracy.
What are the Key Concepts of SSD?
The Single Shot MultiBox Detector (SSD) is a complex object detection model with several key concepts that enable its efficient and accurate performance. Here are the key concepts in SSD:
- Default Bounding Boxes (Anchor Boxes): SSD uses a predefined set of default bounding boxes, also known as anchor boxes. These boxes come in various scales and aspect ratios, providing prior knowledge about where objects are likely to be located in the image. SSD predicts adjustments to these default boxes to localize objects accurately.
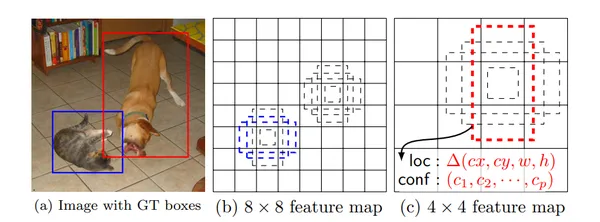
- Multi-Scale Feature Maps: SSD operates on multiple feature maps at different resolutions. Obtain these feature maps by applying convolutional layers to the input image at various stages. Using feature maps at numerous scales allows SSD to detect objects of different sizes.
- Multi-Scale Predictions: For each default bounding box, SSD makes predictions at multiple feature map layers with different resolutions. This enables the model to capture objects at various scales. These predictions include class scores for different object categories and offsets for adjusting the default boxes to match the objects’ positions.
- Aspect Ratio Handling: SSD uses separate predictors (convolutional filters) for different aspect ratios of bounding boxes. This allows it to adapt to objects with varying shapes and aspect ratios.
Architecture of SSD
The architecture of the Single Shot MultiBox Detector is a deep convolutional neural network (CNN) for real-time object detection. It combines various layers to perform localization (bounding box prediction) and classification (object category prediction) in a single forward pass.
The Single Shot MultiBox Detector (SSD) is a robust object detection framework based on a feed-forward convolutional neural network (CNN). Design SSD’s architecture to generate a fixed set of bounding boxes and associated scores, indicating the presence of object class instances in those boxes.
Critical Components and Features
Here’s an explanation of the critical components and features of the SSD approach:
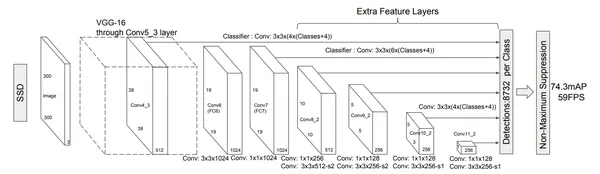
Base Network (Truncated for Classification): SSD begins with a standard CNN architecture, which is typically used for high-quality image classification tasks. However, in SSD, this base network is truncated before any classification layers. The base network is responsible for extracting essential features from the input image.
- Multi-Scale Feature Maps: Additional convolutional layers are added to the truncated base network. These layers progressively reduce the spatial dimensions while increasing the number of channels (feature channels). This design allows SSD to produce feature maps at multiple scales. Each scale’s feature map is suitable for detecting objects of different sizes.
- Default Bounding Boxes (Anchor Boxes): SSD associates a predefined set of default bounding boxes (anchor boxes) with each feature map cell. These default boxes have various scales and aspect ratios. The placement of default boxes relative to their corresponding cell is fixed and follows a convolutional grid pattern. For each feature map cell, SSD predicts the offsets necessary to adjust these default boxes to fit objects and the class scores indicating the presence of specific object categories.
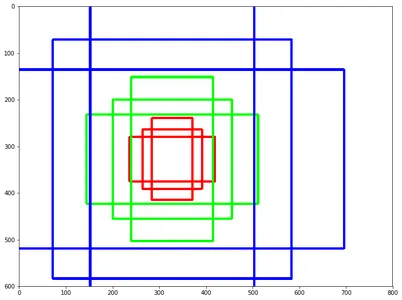
- Aspect Ratios and Multiple Feature Maps: SSD employs default boxes with different aspect ratios and uses them across multiple feature maps at various resolutions. This approach efficiently captures a range of possible object shapes and sizes. Unlike other models, SSD doesn’t rely on an intermediate fully connected layer for predictions but uses convolutional filters directly.

How does SSD Work?
- Open the Notebook: Go to Google Colab (colab.research.google.com) and open the notebook.
- Go to Runtime Menu: Click on the “Runtime” option in the menu at the top.
- Select Change runtime type: Click “Change runtime type” from the dropdown menu.
- Choose Hardware Accelerator: A window will pop up. In this window, select “GPU” from the “Hardware accelerator” dropdown menu.
- Save Changes: Click “SAVE” to apply the changes.
%%bash
pip install numpy scipy scikit-image matplotlibOutput:
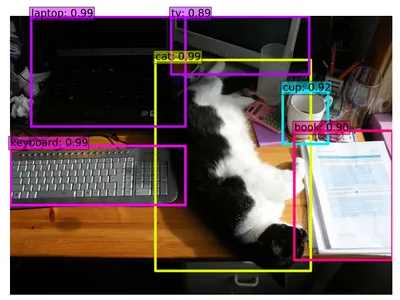
Pretrain Model: loading an SSD (Single Shot Multibox Detector) model pre-trained on the COCO dataset using a deep learning framework such as TensorFlow, or PyTorch requires specific code implementation and access to the respective libraries and model repositories.
import torch
ssd_model = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_ssd')
utils = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_ssd_processing_utils')Output:
ssd_model.to('cuda')
ssd_model.eval()Image Load: To prepare input images for object detection, you’ll need to load them, convert them into a format compatible with the chosen object detection model, and then perform inference on those images.
urls =["https://farm5.staticflickr.com/4080/4951482119_0ecd88aa33_z.jpg"]
inputs = [utils.prepare_input(uri) for uri in urls]
tensor = utils.prepare_tensor(inputs)Run the model: Run the SSD network to perform object detection.
with torch.no_grad():
detections_batch = ssd_model(tensor)
results_per_input = utils.decode_results(detections_batch)
best_results_per_input = [utils.pick_best(results, 0.40) for results in results_per_input]Train on image: To access the COCO dataset annotations and map class IDs to object names, you can use the COCO API. The COCO API allows you to retrieve information about the COCO dataset, including object categories and their corresponding labels.
classes_to_labels = utils.get_coco_object_dictionary()Show the Predication: To visualize the detections on the image using the COCO dataset’s category labels
from matplotlib import pyplot as plt
import matplotlib.patches as patches
for image_idx in range(len(best_results_per_input)):
fig, ax = plt.subplots(1)
# Show original, denormalized image...
image = inputs[image_idx] / 2 + 0.5
ax.imshow(image)
# ...with detections
bboxes, classes, confidences = best_results_per_input[image_idx]
for idx in range(len(bboxes)):
left, bot, right, top = bboxes[idx]
x, y, w, h = [val * 300 for val in [left, bot, right - left, top - bot]]
rect = patches.Rectangle((x, y), w, h, linewidth=1, edgecolor='r',\
facecolor='none')
ax.add_patch(rect)
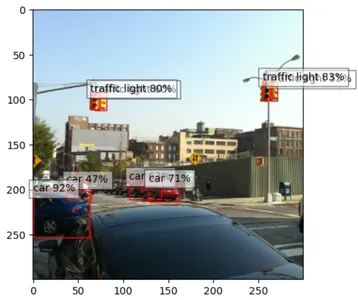
ax.text(x, y, "{} {:.0f}%".format(classes_to_labels[classes[idx] - 1],\
confidences[idx]*100), bbox=dict(facecolor='white', alpha=0.5))
plt.show()Output:
Training of SSD Method
- Assignment of Ground Truth Information: In SSD, we assign ground truth information, i.e., actual object locations and categories, to specific outputs within the fixed set of detector outputs. This process is crucial for training the model to recognize objects correctly.
- Matching Strategy: During training, SSD matches each ground truth box to the default boxes based on the best Jaccard overlap. Jaccard overlap measures how much the predicted box overlaps with the ground truth box. Any default box with a Jaccard overlap higher than a threshold (typically 0.5) with a ground truth box is considered a match. Unlike other methods, such as MultiBox, SSD allows multiple default boxes to be matched with a single ground truth box if their Jaccard overlap exceeds the threshold. This simplifies the learning problem, as the model can predict high scores for multiple overlapping default boxes instead of being forced to select only one.
- Training Objective: The training objective for SSD is derived from the MultiBox objective but is extended to handle multiple object categories. It includes both a localization loss (loc) and a confidence loss (conf):
Detector Outputs
In SSD, ground truth information (i.e., the actual object locations and categories) must be assigned to specific outputs in the fixed set of detector outputs.
- Localization Loss (Lloc): This loss measures the difference between the predicted box parameters (e.g., box coordinates) and the ground truth box parameters. It uses a Smooth L1 loss function.
- Confidence Loss (Lconf): Calculate the confidence loss for using a softmax loss over multiple classes. It measures the difference between predicted class scores and the actual class labels. The overall loss function is a weighted sum of the localization and confidence losses.
- Hard Negative Mining: To address the imbalance between positive (matched) and negative (unmatched) examples during training, SSD uses hard harmful mining. It selects a subset of negative examples based on the highest confidence loss for each default box. The goal is to maintain a reasonable ratio between negatives and positives (typically around 3:1) for more efficient and stable training.
- Data Augmentation: Apply Data augmentation to make the model robust to various input object sizes and shapes. During training, each input image can be subject to multiple transformations, including cropping, resizing, and horizontal flipping. These augmentations help the model generalize better to real-world scenarios.
Overall, SSD’s training process involves the assignment of ground truth information to default boxes, the definition of a training objective that includes both localization and confidence losses, careful selection of default box scales and aspect ratios, handling of imbalanced positive and negative examples, and data augmentation to enhance the model’s robustness.
Comparisons with Other Object Detection Models
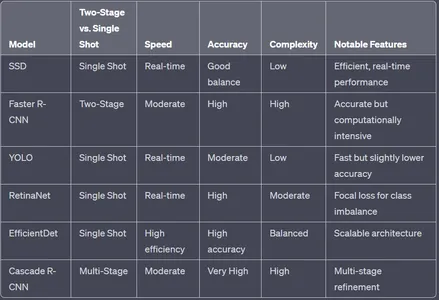
SSD stands out for its real-time performance, simplicity, and a good balance between accuracy and speed. It’s well-suited for many applications, especially those requiring efficient object detection in real-time or near-real-time scenarios. However, for tasks demanding the highest levels of accuracy, models like Faster R-CNN, RetinaNet, or Cascade R-CNN may be more suitable despite their increased computational requirements. The choice of model depends on the specific requirements and constraints of the application.
Applications of SSDs
- Autonomous Vehicles: Use it for real-time object detection in self-driving cars to identify pedestrians, vehicles, and obstacles on the road.
- Surveillance Systems: Employ security and surveillance systems to detect and track intruders or suspicious activities within a monitored area.
- Retail Analytics: Retailers use SSD to monitor store shelves for inventory management, identify customer behavior, and analyze shopping patterns.
- Industrial Automation: In manufacturing settings, SSD assists in quality control by identifying product defects on the production line.
- Drone Applications: Drones equipped with SSD can perform tasks like search and rescue operations, agricultural monitoring, and infrastructure inspection by detecting objects or anomalies from the air.
Challenges and Limitations of SSDs
SSD’s primary limitation is its difficulty in accurately detecting tiny objects, heavily occluded objects, or objects with extreme aspect ratios, which can impact its performance in certain scenarios.
- Small Object Detection: One of the primary limitations of SSD is its effectiveness in detecting tiny objects. Small objects may pose accuracy challenges in detection due to anchor boxes not effectively representing their size and shape within feature pyramids.
- Complex Backgrounds: Objects placed against complex or cluttered backgrounds can pose challenges for SSDs. The model might produce false positives or misclassify objects due to confusing visual information in the surroundings.
- A trade-off between Speed and Accuracy: While SSD excels in speed, achieving top-tier accuracy may require trade-offs. In precision-critical applications, sacrificing speed may lead to a preference for alternative, more accurate object detection methods. If we want a fast prediction, SSD is used, but it has less accuracy.
- Customization Overhead: Fine-tuning SSDs for specific applications can be labor-intensive and resource-consuming. Customization and optimization to suit particular use cases may require expertise in deep learning.
Project on SSD
Shredder-Machine-Hand-Protection: The use of SSD (Single Shot MultiBox Detector) in the project is significant, as it forms the basis of the object detection model used to identify and track hands near shredder machines. Here’s how SSD is utilized in the project:
To get the project source code, clone the repository :
git clone https://github.com/NeHa77A/Shredder-Machine-Hand-Protection.git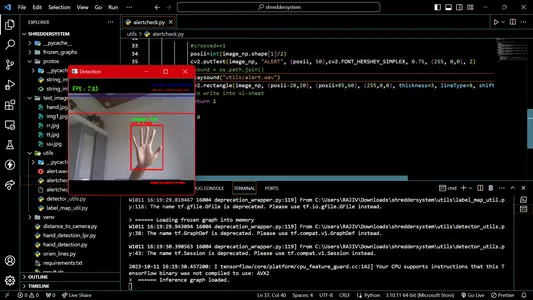

- Object Detection: SSD is employed as the object detection framework to identify and locate hands in real-time video data. It’s particularly well-suited for this task as it offers high accuracy and efficient inference, crucial for promptly detecting hands near the shredder.
- Real-Time Processing: Ensures that the system can react promptly to potential safety risks. It allows for quick and accurate identification of hands, enabling the system to issue warnings and initiate shutdowns in milliseconds.
- Customization: SSDs can be fine-tuned and customized to the specific requirements of the project. By training the SSD model on annotated data from workers operating shredder machines, it can adapt to diverse working conditions and machine designs.
- Accuracy and Precision: SSD excels in providing accurate and precise object detection. This is crucial when distinguishing hands from other objects or background elements in the video feed, ensuring that safety measures are triggered only when necessary.
- Efficiency: The efficiency of SSD is essential for maintaining system performance. It’s optimized to run on various hardware platforms, making it an ideal choice for deployment in an industrial setting.
In summary, SSD is integral to the project as it is the foundation for the object detection model. Its real-time processing, accuracy, and customization capabilities enable the safety system to effectively detect and respond to potential hand injuries near shredder machines.
Real-world Case Studies
- Autonomous Driving: Tesla’s self-driving cars employ SSD and other computer vision techniques to detect and classify objects on the road, such as pedestrians, vehicles, and road signs. This technology is crucial in achieving advanced driver assistance and full self-driving capabilities.
- Airport Security: Airports use SSD-based surveillance systems to monitor passengers and luggage. SSD helps identify suspicious objects, unattended baggage, and unusual activities, enhancing security measures.
- Retail Inventory Management: Retailers employ SSD for inventory management, enabling the quick and accurate counting of products on store shelves. It assists in tracking stock levels and preventing inventory discrepancies.
- Industrial Automation: Quality Control in Manufacturing: Manufacturing industries utilize SSD to ensure product quality. It’s applied in inspecting products for defects, verifying label placement, and checking for contamination in the production line.
- Robotic Assembly Lines: In robotics, Employ SSD to identify and locate objects in dynamic environments. This is particularly useful in pick-and-place operations and other robotic tasks.
These real-world examples demonstrate the versatility and significance of SSDs in various industries.
Conclusion
In conclusion, the SSD is a groundbreaking object detection model that combines speed and accuracy. SSD’s innovative use of multi-scale convolutional bounding box predictions allows it to capture objects of varying shapes and sizes efficiently. Introducing a more significant number of carefully chosen default bounding boxes enhances its adaptability and performance.
SSD is a versatile standalone object detection solution and a foundation for larger systems. It balances speed and precision, making it valuable for real-time object detection, tracking, and recognition. Overall, SSD represents a significant advancement in computer vision, addressing the challenges of modern applications efficiently.
Key Takeaways
- Empirical results demonstrate that SSD often outperforms traditional object detection models in terms of both accuracy and speed.
- SSD employs a multi-scale approach, allowing it to detect objects of various sizes within the same image efficiently.
- SSD is a versatile tool for various computer vision applications.
- SSD is renowned for its real-time or near-real-time object detection capability.
- Using a more significant number of default boxes allows SSD to better adapt to complex scenes and challenging object variations.
Frequently Asked Questions
Q1. What are default bounding boxes in SSD?
A. Default bounding boxes are predefined bounding boxes of various sizes and aspect ratios that SSD uses as priors for object detection. These default boxes help the model predict the locations and shapes of objects within an image.
Q2. Can SSD be used for detecting multiple object categories simultaneously?
A. Yes, SSD is capable of detecting multiple object categories simultaneously. It can identify and classify objects across various categories within the same image.
Q3. How does SSD compare to other object detection models like Faster R-CNN and YOLO?
A. SSD often outperforms models like Faster R-CNN and YOLO regarding speed and accuracy. It achieves competitive accuracy while maintaining real-time or near-real-time performance.
Q4. In which industries and applications can SSD be used?
A. SSD finds applications in various industries, including autonomous vehicles, surveillance, retail, medical imaging, agriculture, industrial automation, and more, where efficient and accurate object detection is crucial.
Q5. Can SSDs be integrated into larger computer vision systems?
A. SSD can be a foundational component in larger computer vision systems. It can be integrated into systems that require object detection, tracking, and recognition, making it a versatile building block.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I'm Neha Vishwakarma, a data science enthusiast with a background in information technology, dedicated to using data to inform decisions and tackle complex challenges. My passion lies in uncovering hidden insights through numbers.



