One of the most common question, which gets asked at various data science forums is:
What is the difference between Machine Learning and Statistical modeling?
I have been doing research for the past 2 years. Generally, it takes me not more than a day to get clear answer to the topic I am researching for. However, this was definitely one of the harder nuts to crack. When I came across this question at first, I found almost no clear answer which can layout how machine learning is different from statistical modeling. Given the similarity in terms of the objective both try to solve for, the only difference lies in the volume of data involved and human involvement for building a model. Here is an interesting Venn diagram on the coverage of machine learning and statistical modeling in the universe of data science (Reference: SAS institute)
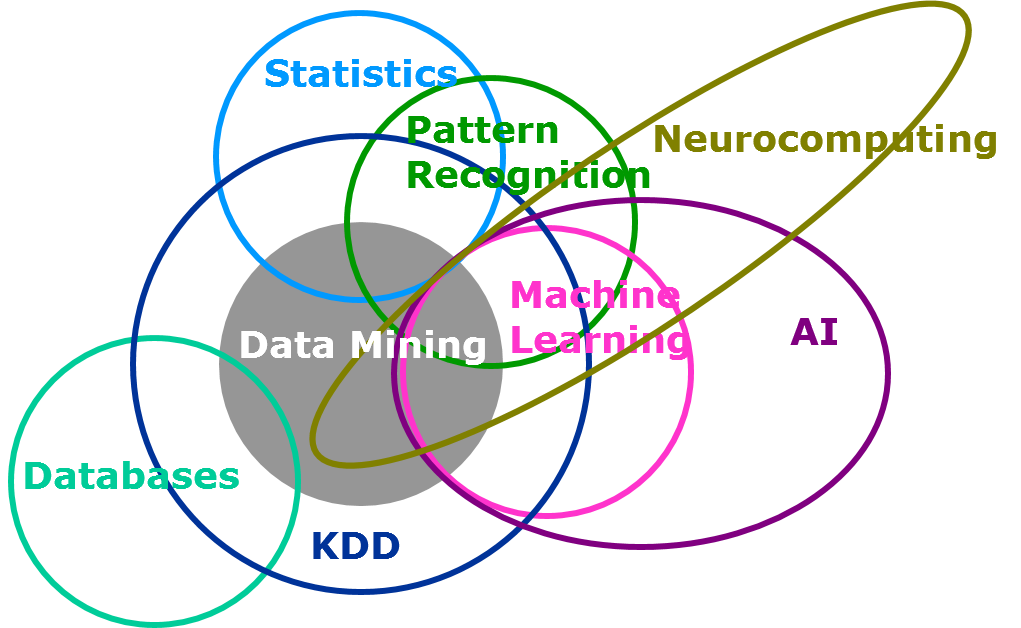
In this article, I will try to bring out the difference between the two to the best of my understanding. I encourage more seasoned folks of this industry to add on to this article, to bring out the difference.
Before we start, let’s understand the objective behind what we are trying to solve for using either of these tools. The common objective behind using either of the tools is Learning from Data. Both these approaches aim to learn about the underlying phenomena by using data generated in the process.
Now that it is clear that the objective behind either of the approaches is same, let us go through their definition and differences.
Before you proceed: Machine learning basics for a newbie
Definition:
Let’s start with a simple definitions :
Machine Learning is …
an algorithm that can learn from data without relying on rules-based programming.
Statistical Modelling is …
formalization of relationships between variables in the form of mathematical equations.
For people like me, who enjoy understanding concepts from practical applications, these definitions don’t help much. So, let’s look at a business case here.
A Business Case
Let us now see an interesting example published by McKinsey differentiating the two algorithms :
Case : Understand the risk level of customers churn over a period of time for a Telecom company
Data Available : Two Drivers – A & B
What McKinsey shows next is an absolute delight! Just stare at the below graph to understand the difference between a statistical model and a Machine Learning algorithm.
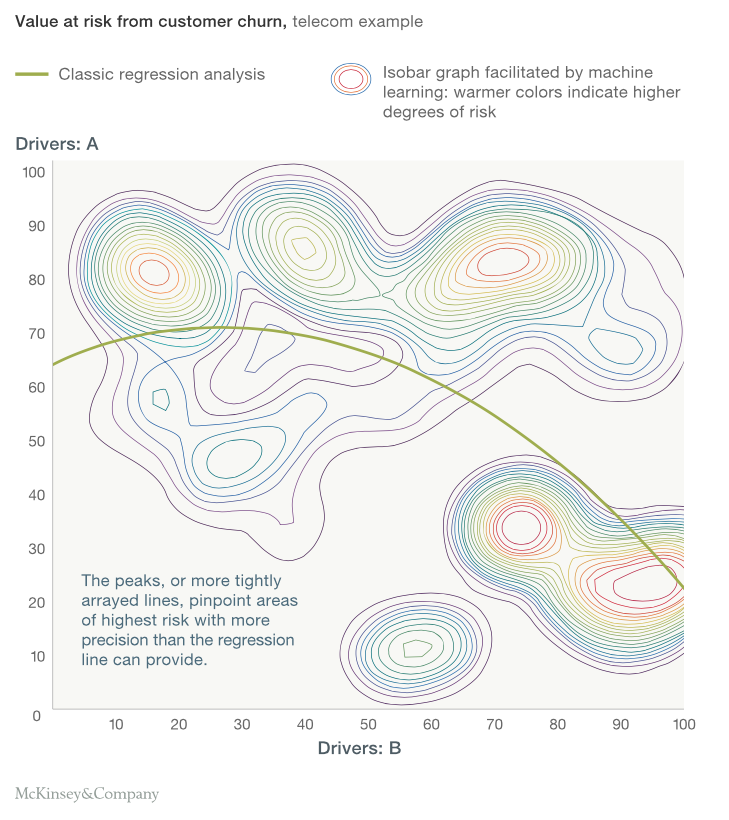
What did you observe from the above graph? Statistical model is all about getting a simple formulation of a frontier in a classification model problem. Here we see a non linear boundary which to some extent separates risky people from non-risky people. But when we see the contours generated by Machine Learning algorithm, we witness that statistical modeling is no way comparable for the problem in hand to the Machine Learning algorithm. The contours of machine learning seems to capture all patterns beyond any boundaries of linearity or even continuity of the boundaries. This is what Machine Learning can do for you.
If this is not an inspiration enough, machine learning algorithm is used in recommendation engines of YouTube / Google etc. which can churn trillions of observations in a second to come up with almost a perfect recommendation. Even with a laptop of 16 GB RAM I daily work on datasets of millions of rows with thousands of parameter and build an entire model in not more than 30 minutes. A statistical model on another hand needs a supercomputer to run a million observation with thousand parameters.

Differences between Machine Learning and Statistical Modeling:
Given the flavor of difference in output of these two approaches, let us understand the difference in the two paradigms, even though both do almost similar job :
- Schools they come from
- When did they come into existence?
- Assumptions they work on
- Type of data they deal with
- Nomenclatures of operations and objects
- Techniques used
- Predictive power and human efforts involved to implement
All the differences mentioned above do separate the two to some extent, but there is no hard boundary between Machine Learning and statistical modeling.
They belong to different schools
Machine Learning is …
a subfield of computer science and artificial intelligence which deals with building systems that can learn from data, instead of explicitly programmed instructions.
Statistical Modelling is …
a subfield of mathematics which deals with finding relationship between variables to predict an outcome
They came up in different eras
Statistical modeling has been there for centuries now. However, Machine learning is a very recent development. It came into existence in the 1990s as steady advances in digitization and cheap computing power enabled data scientists to stop building finished models and instead train computers to do so. The unmanageable volume and complexity of the big data that the world is now swimming in have increased the potential of machine learning—and the need for it.
Extent of assumptions involved
Statistical modeling work on a number of assumption. For instance a linear regression assumes :
- Linear relation between independent and dependent variable
- Homoscedasticity
- Mean of error at zero for every dependent value
- Independence of observations
- Error should be normally distributed for each value of dependent variable
Similarly Logistic regressions comes with its own set of assumptions. Even a non linear model has to comply to a continuous segregation boundary. Machine Learning algorithms do assume a few of these things but in general are spared from most of these assumptions. The biggest advantage of using a Machine Learning algorithm is that there might not be any continuity of boundary as shown in the case study above. Also, we need not specify the distribution of dependent or independent variable in a machine learning algorithm.
Types of data they deal with
Machine Learning algorithms are wide range tools. Online Learning tools predict data on the fly. These tools are capable of learning from trillions of observations one by one. They make prediction and learn simultaneously. Other algorithms like Random Forest and Gradient Boosting are also exceptionally fast with big data. Machine learning does really well with wide (high number of attributes) and deep (high number of observations). However statistical modeling are generally applied for smaller data with less attributes or they end up over fitting.
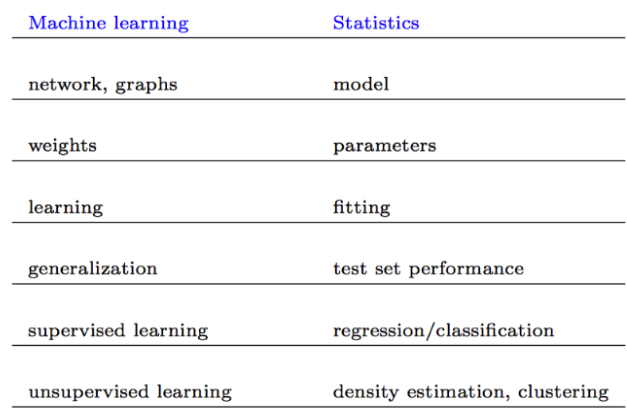
Naming Convention
Here are a names which refer to almost the same things :
Formulation
Even when the end goal for both machine learning and statistical modeling is same, the formulation of two are significantly different.
In a statistical model, we basically try to estimate the function f in
Dependent Variable ( Y ) = f(Independent Variable) + error function
Machine Learning takes away the deterministic function “f” out of the equation. It simply becomes
Output(Y) ----- > Input (X)
It will try to find pockets of X in n dimensions (where n is the number of attributes), where occurrence of Y is significantly different.
Predictive Power and Human Effort
Nature does not assume anything before forcing an event to occur.
So the lesser assumptions in a predictive model, higher will be the predictive power. Machine Learning as the name suggest needs minimal human effort. Machine learning works on iterations where computer tries to find out patterns hidden in data. Because machine does this work on comprehensive data and is independent of all the assumption, predictive power is generally very strong for these models. Statistical model are mathematics intensive and based on coefficient estimation. It requires the modeler to understand the relation between variable before putting it in.
End Notes
However, it may seem that machine learning and statistical modeling are two different branches of predictive modeling, they are almost the same. The difference between these two have gone down significantly over past decade. Both the branches have learned from each other a lot and will further come closer in future. I hope we motivated you enough to acquire skills in each of these two domains and then compare how do they compliment each other.
If you are interested in picking up machine learning algorithms, we have just the right thing coming up for you. We are in process of building a learning path for machine learning which will be published soon.
Let us know what you think is the difference between machine learning and statistical modeling? Do you have any case study to point out the differences between the two?
If you like what you just read & want to continue your analytics learning, subscribe to our emails, follow us on twitter or like our facebook page.
Tavish Srivastava, co-founder and Chief Strategy Officer of Analytics Vidhya, is an IIT Madras graduate and a passionate data-science professional with 8+ years of diverse experience in markets including the US, India and Singapore, domains including Digital Acquisitions, Customer Servicing and Customer Management, and industry including Retail Banking, Credit Cards and Insurance. He is fascinated by the idea of artificial intelligence inspired by human intelligence and enjoys every discussion, theory or even movie related to this idea.






Brilliant article Tavish and beautifully explained. This fact has bothered me far too long and I have formed my own raw interpretations. Statistics and models derived from statistics primarily were concerned with numbers and numerical outputs. This probably was one more reason for machine learning to step in and supply the algorithms to run decision trees, support vector machines etc which work well on categorical data. Also historically the biggest application of statistics has been in hypothesis testing - to prove or disprove something based on numbers. Prediction was never really the most important goal of statisticians, which is where again machine learning comes in.
Thanks Tavish for the excellent post with examples.
statistics require assumption on the distribution of data, Machine Learning may or may not. Machine learning can be employed in other areas, e.g. can learn sequence of actions or tasks (play games, drive car,etc).