This article was published as a part of the Data Science Blogathon
Okay! I know that stealing is a crime and we should never get involved into it.
But as an AI/ML & Data Science enthusiast, you must have come across numerous research papers and studies (mostly published in journals) where the research has been excellent and you have been wanting to know how it was performed.
If you are a beginner or an intermediate in this field, you might have mostly done ML projects and courses conventionally. That’s VERY MUCH fine.
But, once you get going in the field of AI/ML, you must keep a glance over research papers and publications to elevate your standards and broaden your opportunities.
The various sections of a research paper quite vividly describe the work done by the computer-scientists, researchers, and engineers from various academic institutions and research groups across the world. A lot of work that we see in practice today originated as findings and methods published in such papers.
BUT WHAT ABOUT THE ACTUAL CODE?
Though the work is often described lucidly in research publications, a big limitation is that the original code is not made publicly accessible. And this comes due to many reasons. The research groups feel that it is only the results that are the most important for their publication. They just give an overview of how the work was carried out in the ‘methodology’ section and lines of code are kept hidden.
But the good news is that there are plenty of ways to access the codes and make the best use of research publications. We list out and describe some of the platforms and techniques to make this possible.
1. Paper with codes – A Gold Mine!
There are academicians and research groups who do publish their codes and files along with their research papers and publications. To find out such, you must visit paperswithcode.com, a platform that gathers Machine Learning papers and codes from journals and publishers across the world. The best part is that everything is free and openly licensed under CC-BY-SA. Even the public can contribute with an edit button.
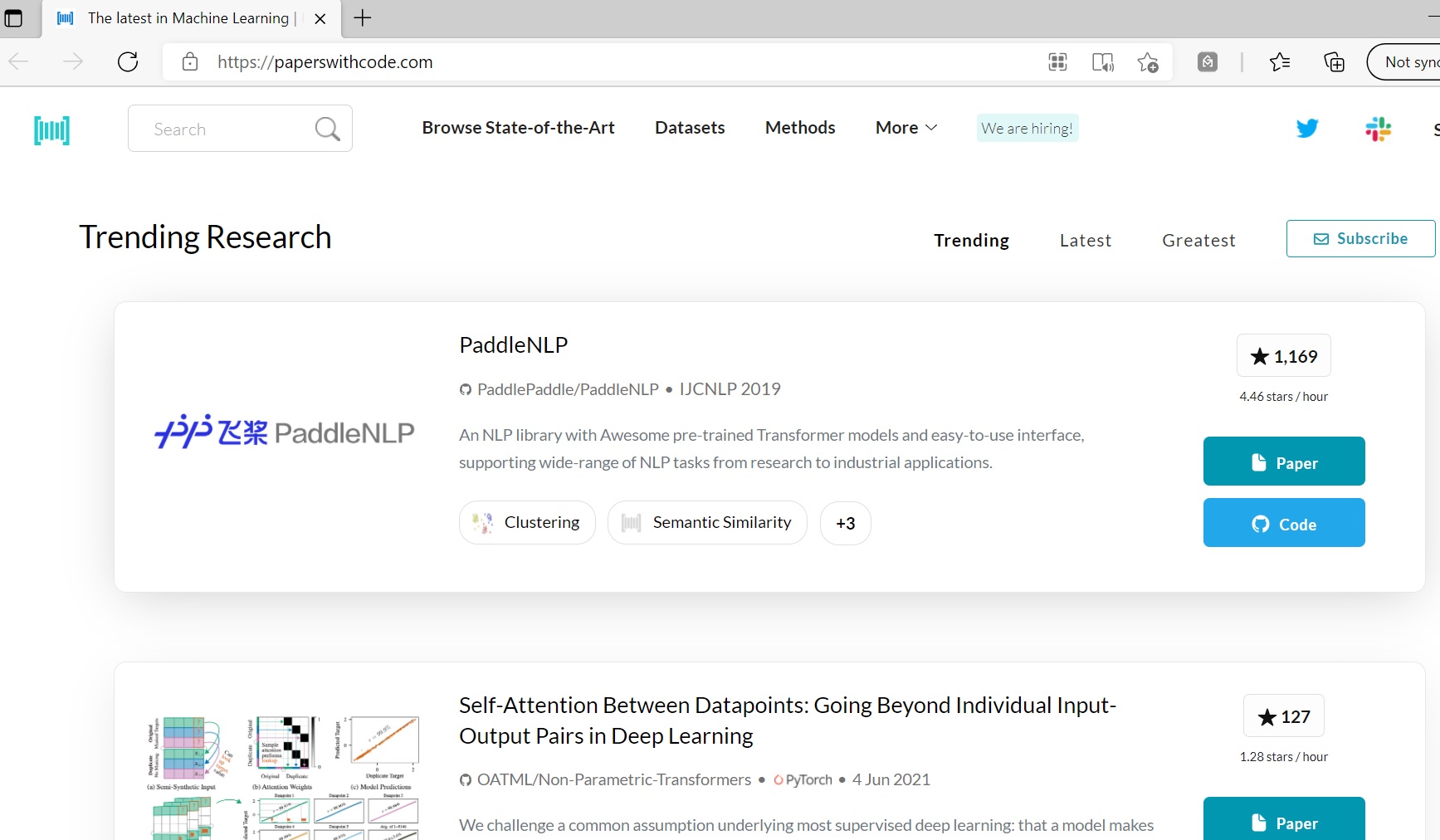
There are so many things you can take away from here –
A state-of-the-art collection: A specially curated section of tasks (under topics like CV, NLP, Medical, Time Series, etc) which contain a collection of ML codes, papers, and models. These are compared & the best one under a given dataset is benchmarked. You get to know a great deal about what research is published in various journals.
You can additionally check for sota-benchmarking of ML models here.
Portals for various disciplines: Apart from just dealing with AI, there are special portals of Machine Learning, Computer Science, Statistics, etc. The opportunities just get endless from here.
Datasets from research: Around 4000+ standardized Machine Learning datasets are gathered and made publicly available. These can be filtered under various modalities, tasks, and languages. The most interesting is to see a listing of published papers under each dataset. Each of these paper highlights some research carried out using the dataset. So, this platform makes it easy for you to compare your own work on the given dataset with the results published earlier.
Methods for you to implement: Have you heard of things like GoogLeNet under Convolutional Neural Network and Transformer-XL under Natural Language Processing? If not DO NOT worry at all. These are some of the things the world has been working on and maybe become the thing of summer AI projects in few years. By discovering and knowing such concepts beforehand, you certainly broaden your scope and outlook. The methods section of this platform has a list of topics under every discipline like CV and NLP. Every method has many numbers of published papers under it for you to see and learn.
The platform also has a section for libraries and trends. Most importantly it advocates the openness and reproducibility of research papers and the codes used in them. This comes at a stage when the world is rapidly advancing with the use of ML/AI and thus publicization of new findings and resources (by keeping transparency) can have an encouraging impact. There’s an ML reproducibility challenge here that you must have a look on.
Paper with code is based on Facebook AI Research and even the primary data sources of the portal and free and open to download. Get all their information here.
2. Researchcode.com
Welcome to a search engine of research papers and publications with codes. This is an awesome tool to search ML/AI papers from various disciplines and it comes with a Google Chrome extension and an option to add new papers along with code. The search results can be sorted as per year, popularity, and relevance. Using the Chrome extension (download here), you get suggestion while browsing.
Upon making a log-in, you can add a paper to the site. For this, you need to provide all details and like name, link, and abstract. You must necessarily add the link to the code and its details.
3. CatalyzeX – A browser extension and portal
To catalyze your ML research, here’s another browser extension. Download this (from here) to get suggestions while browsing on Scholar, arXiv, Twitter, etc.
Additionally, you can browse through a curated list of papers with model/code under topics like Cancer Detection, Music Generation, Chatbots, etc
4. TheJournal.Club
Here’s an awesome collection of papers on various topics of Machine Learning and AI. But the most interesting part of this platform is – the clubs. These are a kind of user groups (like Facebook groups) where people discuss, share their opinions about various research publications, and hold webinars/meetings.
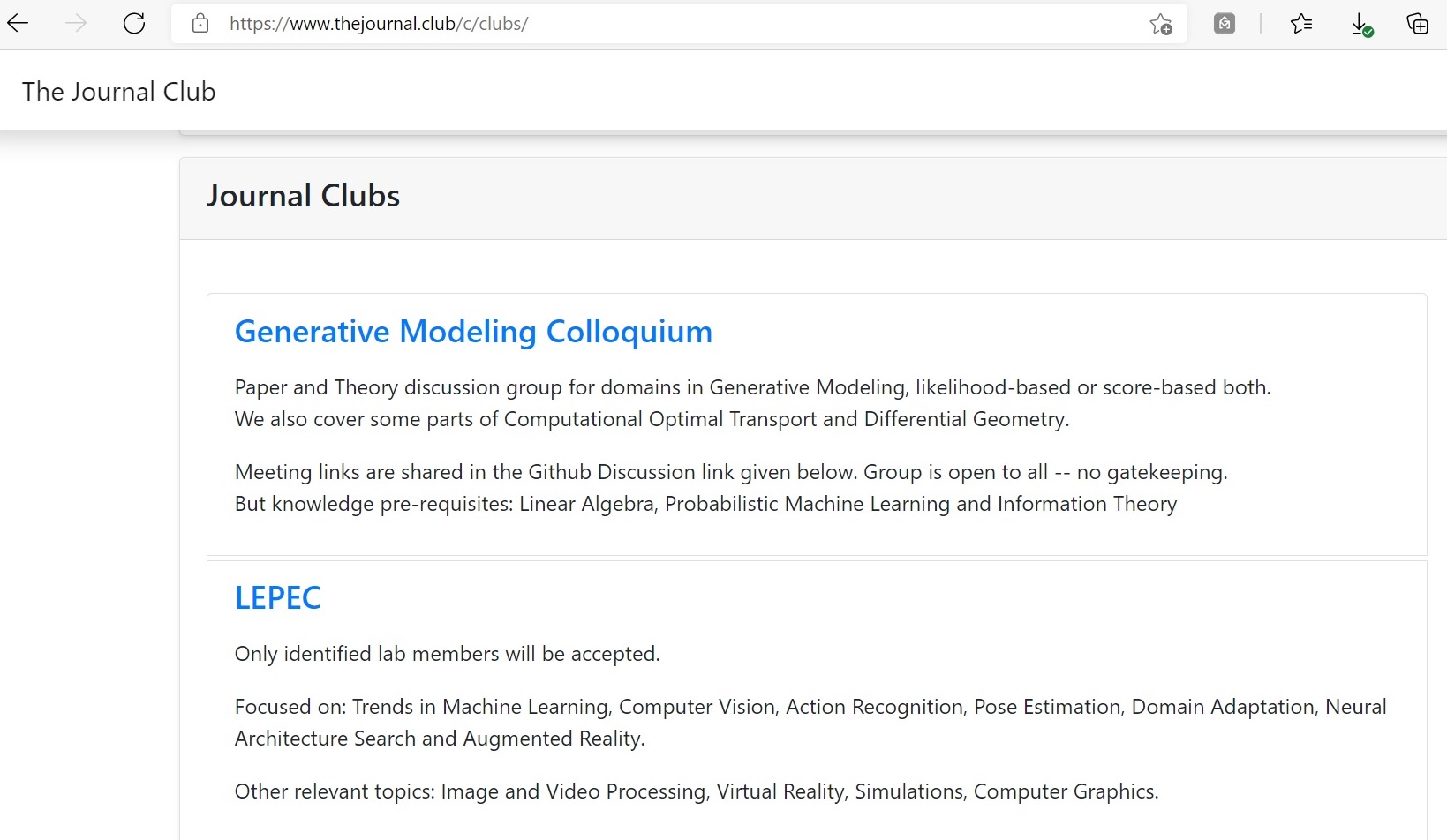
You also get an additional list of authors, datasets and codes on this platform. The ‘codes’ tab lists various ML/AI topics under the sun and the papers that implement these topics are highlighted.
5. Papers + Code – MIT-IBM Watson AI Lab
This is another list of peer-reviewed papers that come along with code, released by a joint collaboration between MIT and IBM Watson. They believe in producing reproducible and innovative results.
6. Automatic paper-to-code – an insightful approach
Imagine if we could automatically convert the deep learning research papers to executable code. Sounds like an interesting NLP project, right?
Say hi to the IBM Deep Learning IDE, proudly developed at IBM Research India. This seemingly untrue technology ingests deep learning algorithms in published research papers and recreates them in source code for inclusion in libraries for multiple deep learning frameworks (Tensorflow, Keras, Caffe). It uses the flowcharts and tables in a research paper to do the same.
The motivation came from the fact that it happens to be very difficult for even experienced engineers to reproduce the code in a given Deep Learning or AI/ML paper. In majority of publications, the code was not made available by the authors.
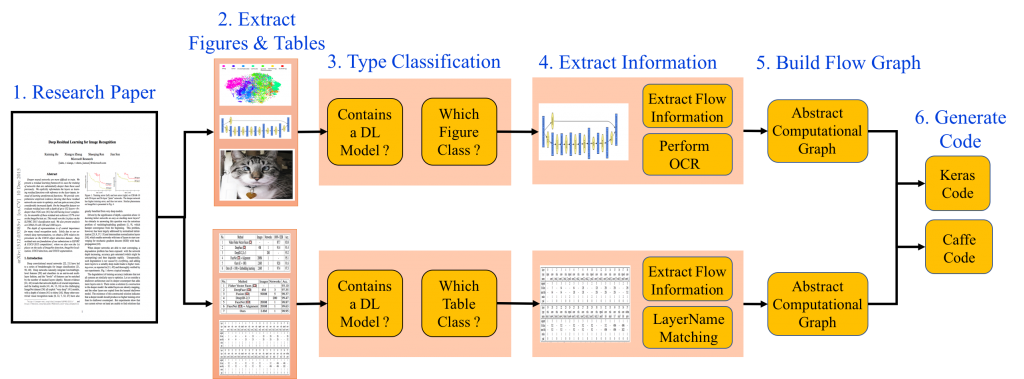
The IDE also has an interesting drag-and-drop UI editor, which can be used to manually edit and perfect the extracted design, and generate the source code in real-time. Currently, we are in the process of building a model zoo consisting of design and source code for models from 5,000 core deep learning research papers from arXiv. We are hoping to share this dataset soon with the larger research community to use and improve.
Additionally, check out another source code retrieval study here.
THE CONVENTIONAL APPROACHES YOU MUST KNOW
Above given are some platforms and methods for obtaining the source code. But the story doesn’t end here as you can also extract the code yourself. Here are some of the must-know approaches –
1. CHECK THE PAPER THOROUGHLY –
This may sound obvious but with the amount of text being huge in a research paper, the link to the code is often left hidden. If not a direct link, many papers describe where the source code may be extracted from or at least give a hint in their methodology section.
In case you don’t get anything, you will surely get the idea of how you can reproduce the study yourself. By doing so, you actually get better with your skills and know-how.
2. CODE (AND DATA) AVAILABILITY STATEMENT | SUPPLEMENTARY INFORMATION –
The source code (or even the dataset) is often not regarded as the main part of a paper.
So information relating to it is provided under code availability statement or supplementary information portion.
Where to get them? The availability statement is mentioned towards the very end of the research paper and/or at the publisher’s page (that you reach after clicking the DOI link of the paper)
Same is for supplementary information. This is often a separate part of the paper which is the not included in the main paper (like Appendix). You may get this at the very end of the combined document file or as a separate document found at the publisher’s page.
(Beware! You are most likely to overlook the above things…)
3. SEACH ON GITHUB (+ CHECK FOR REPOSITORIES) –
This is one of the things you do probably, isn’t it? When it comes to sharing code, it is mostly that GitHub is used to share the files. You may search on GitHub by using the DOI link, the paper’s name, the author’s name, or even the journal’s name. You can also search using the topic or sub-topic name. You will most likely get a repository having source code for carrying your research.
4. REACH OUT TO THE AUTHORS –
Probably you didn’t find luck in any other option. Don’t worry! Every paper has a corresponding author whose role is to receive correspondence and queries like this. Find out the details of that author and write to him/her on email.
NOTE THAT it’s up to the author to make the things available to you. If you are able to convince the author(s) of your intentions, they will most likely trust you and this has happened many times. That is how research used to work till now. Here are some possible scenarios in which they do so –
-> You find out some errors or lapses in their work and you want to verify/prove it or help them convincingly.
-> You suggest some additions which are of their interest. Then you may collaborate with them to improve their work (and maybe publish as another paper)
-> You can reproduce the code in a better/efficient way, in another programming language, or through another approach, etc.
-> For educational purposes, for giving your opinion, for sharing it, etc.
REPRODUCIBILITY & OPENNESS – THE NEW NORMAL?
Before we wrap, let’s have a word about the main issue – lack of transparency and openness. But this is obvious!
If you or me are working on something interesting for months together (probably a year) and we publish our study and findings as a paper, why should I make my code public? Some college guy may just grab and make better use of it with minimal efforts.
The only way to deal with this is by shifting to a new normal where sharing is caring, literally. This will start with you, me, and everyone around. Be it the research paper itself (that you have to access with a high-price subscription), the data used or the code utilized, things should be given and received openly.
There are huge benefits to this. The research gets fast-tracked, beginners get learning and motivation. Also, reproducibility is ensured.
What if I publish something that is really good, but it just worked for me and only for once? What if I made a mistake and it gets hidden unknowingly?
If others are also able to recreate those results (ie reproduce it), we ensure that research is full-proof and of high class. Scientists are left with no chance to make any mistakes as they must verify everything before publication. People who reproduce it also get a lot of things to learn.
Check out the ML reproducibility challenge here where you can participate to recreate the results found in various papers. Read another blog on this. Learn about executable research articles here.
About Author
Hello, this is Jyotisman Rath from Bhubaneswar, and it’s the toughest challenges that always excite me. Alongside pursuing I-MTech in Chemical Engineering, I owe a great interest in the field of AI/ML and Data Science. I look to integrate these with my research interests and real-world scenarios and I believe technology is much more than just coding.
Would love to see you on LinkedIn and Instagram. Mail me here for any queries.
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.







Hey thanx for sharing this blog over here. It seems useful to start career in clinical research. We will look foreward for more updates.
Excellent article, thanks a lot for sharing sir.
really an interesting blog, keep on posting your blogs and posts bro