Introduction
A Deep Belief Network (DBN) is a sophisticated generative model that employs a deep architecture. In this article, we are going to learn all about it. After reading this article, you will have a better understanding of what a Deep Belief Network is, how it works, where to use it, and how to code biases your own Deep Belief Network.
This article was published as a part of the Data Science Blogathon.
Table of contents
- Introduction
- What is a Deep Belief Network?
- How did Deep Belief Neural Networks Evolve?
- The Architecture of DBN
- How does DBN work?
- Creating a Deep Belief Network
- Learning a Deep Belief Network
- Applications
- Basic Python Implementation
- How do you train a Deep Belief Network effectively?
- Conclusion
- Frequently Asked Questions
What is a Deep Belief Network?
We create Deep Belief Networks (DBNs) to address issues with classic neural networks in deep layered networks. For example – slow learning, becoming stuck in local minima owing to poor parameter selection, and requiring a large number of training datasets of these given input layer.
- Several layers of stochastic latent variables make a DBN. Binary latent variables that are often known as feature detectors or hidden units are binary variables.
- DBN is a hybrid generative graphical model. The top two layers have no direction. The layers above have directed links to lower layers.
- DBN is an algorithm for unsupervised probabilistic deep learning.

Deep Belief Networks are machine learning algorithm that resembles the deep neural network but are not the same. These are feedforward neural networks with a deep architecture, i.e., having many hidden layers. Simple, unsupervised networks like restricted Boltzmann machines- RBMs or autoencoders make DBNs, with the hidden layer of each sub-network serving as the visible layer for the next layer.
How did Deep Belief Neural Networks Evolve?
We employ Perceptrons in the First Generation of neural networks to identify a certain object or anything else by considering the weight. However, Perceptrons may be beneficial for basic technology only, but not for sophisticated technology. To address these problems, the Second Generation of Neural Networks introduced the notion of Backpropagation, which compares the received output to the desired output and reduces the error value to zero. Then came directed acyclic graphs known as belief networks, which aided in the solution of inference and learning problems. Then, we’ll use Deep Belief Networks to help construct unbiased values that we can store in leaf nodes.
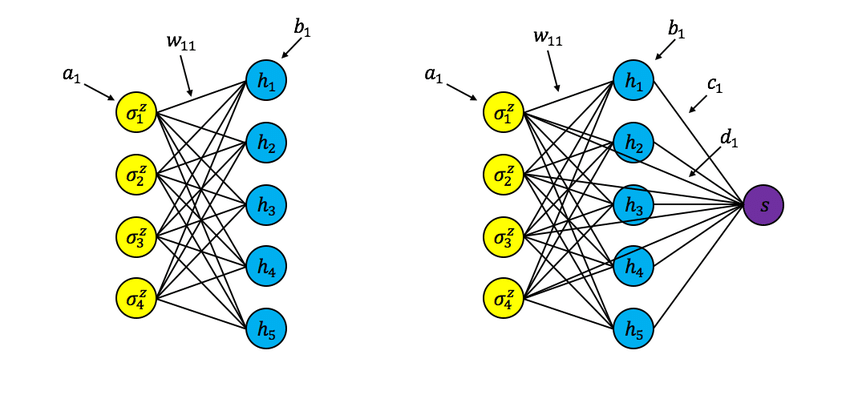
Restricted Boltzmann Machines
A Restricted Boltzmann Machine (RBM) is a type of generative stochastic artificial neural network that can learn a probability distribution from its inputs. Deep learning networks can also use RBM. Deep belief networks, in particular, can be created by “stacking” RBMs and fine-tuning the resulting deep network via gradient descent and backpropagation.
The Architecture of DBN
A series of constrained Boltzmann machines connected in a specific order make a Deep Belief Network. We supplement the result of the “output” layer of the Boltzmann machine as input to the next Boltzmann machine consecutively. Then we’ll train it until its convergence and apply the same until the completion of the whole network.
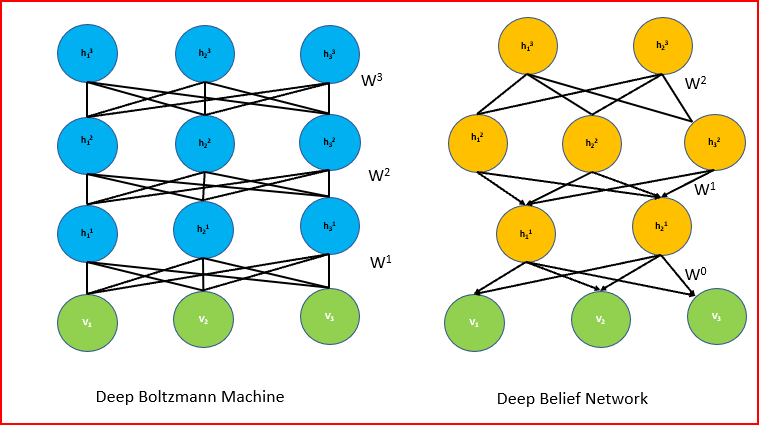
The undirected and symmetric connections between the top two levels of DBN form associative memory. The arrows pointing towards the layer closest to the data point to the relationships between all lower layers. Directed acyclic connections in the lower layers translate associative memory to observable variables. The lowest layer of visible units receives the input data. We can use Binary or actual data as input. Like Restricted Boltzmann Machine (RBM), there are no intralayer connections. The hidden units represent features that encapsulate the data’s correlations. A matrix of symmetrical weights W connects two layers. We’ll link every unit in each layer to every other unit in the layer above it.
How does DBN work?
The first stage is to train a property layer that can directly gain input signals from pixels. In an alternate labeled data retired subcaste, learn the features of the preliminarily attained features by treating the values of this subcaste as pixels. The lower bound on the log-liability of the training data set improves every time a fresh subcaste of parcels or features that we add to the network.
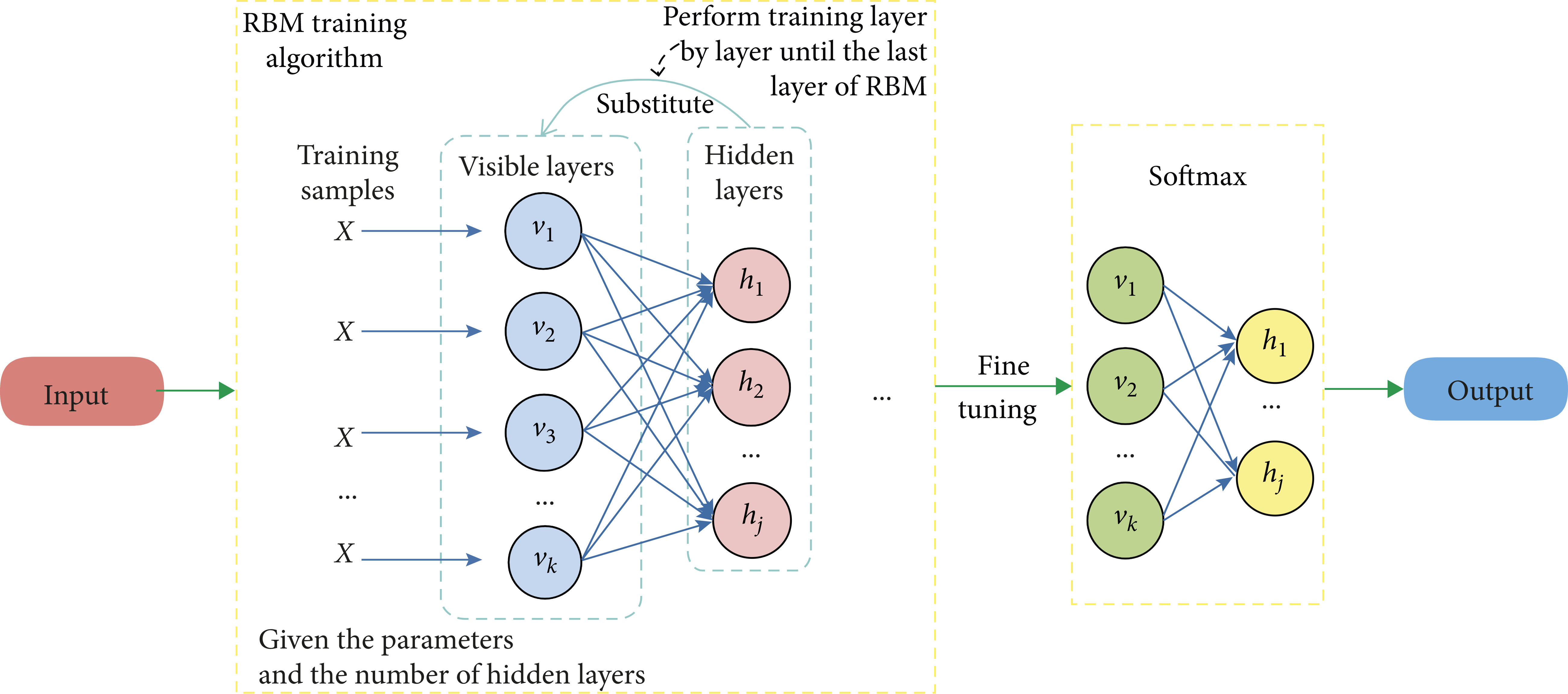
Deep Belief Network’s operational pipeline is as follows:
- We’ll use the Greedy learning algorithm to pre-train DBN. For learning the top-down generative weights-the greedy learning method that employs a layer-by-layer approach. These generative weights determine the relationship between variables in one layer and variables in the layer above.
- On the top two hidden layers, we run numerous steps of Gibbs sampling in DBN. The top two hidden layers define the RBM thus, this stage is effectively extracting a sample from it.
- Then generate a sample from the visible units using a single pass of ancestral sampling through the rest of the model.
- We’ll use a single bottom-up pass to infer the values of the latent variables in each layer. In the bottom layer, greedy pretraining begins with an observed data vector. It then oppositely fine-tunes the generative weights.
.png)
It’s necessary to remember that constructing a Deep Belief Network necessitates training each RBM layer. Initially, we’ll initiate the units and parameters for this purpose. In the Contrastive Divergence algorithm, there are two phases: positive and negative. We’ll calculate the binary states of the hidden layers in the positive phase by computing the probabilities of weights and visible units. It is known as the positive phase since it enhances the likelihood of the training data set. The negative phase reduces the likelihood of the model producing samples. To train a complete Deep Belief Network, we’ll employ the greedy learning technique. The greedy learning algorithm trains one RBM at a time until all of the RBMs are trained.
Creating a Deep Belief Network
Several RBMs together make a Deep Belief Networks, which reflects in their Clojure record structure. We use a fully unsupervised form of DBN to initialize a Deep Neural Network, whereas we use a classification DBN (CDBN) as a classification model on its own.
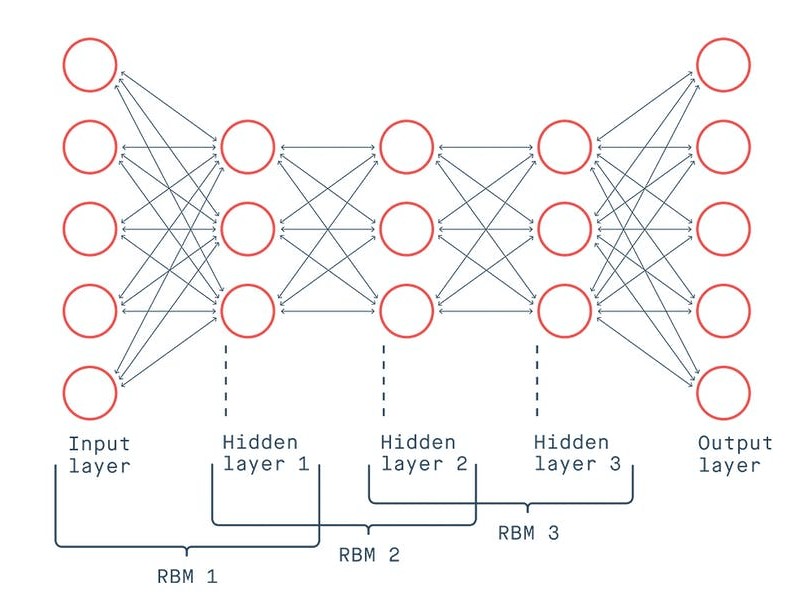
Each record type includes the RBMs that make up the network’s layers, as well as a vector- indicating the layer size and, in the case of the classification DBN- the number of classes in the representative dataset. The DBN record represents a model made up entirely of stacked RBMs, but the CDBN record contains the top-level associative memory, which is a CRBM record. This enables the top layer to be trained to create class labels for input data vectors and to classify unknown data vectors.
Learning a Deep Belief Network
Factually, we learned that RBMs are the ones that make DBN unsupervised making it much easier to train. The RBM training duration is longer than the whole DBN training period, but the code is simpler. Because CDBNs require the observation labels to be available during top-layer training, a training session entails first training the bottom layer, then propagating the dataset via the learned RBM and using the newly altered dataset as the training data for the next RBM. We’ll repeat this process until the passage of the dataset through the penultimate trained RBM, and then all the labels are concatenated with the altered dataset and used to train the top-layer associative memory. The DBN has hyperparameters to set, similar to the RBM model, and offers sensible default values.
Applications
We employ deep belief networks in place of deep feedforward networks or even convolutional neural networks in more sophisticated setups. They have the benefit of being less computationally costly. computational complexity grows linearly with the number of layers, rather than exponentially as with feedforward neural networks) and is less susceptible to the vanishing gradients problem.
Applications of DBN are as follows:
- Recognition of images.
- Sequences of video.
- Data on mocap.
- Speech recognition.
Basic Python Implementation
We’ll begin by importing Python libraries. For learning purposes, there are countless datasets available. We’re going to use https://www.kaggle.com/c/digit-recognizer for this article.
from sklearn.model_selection import train_test_split
from dbn.tensorflow import SupervisedDBNClassification
import numpy as np
import pandas as pd
from sklearn.metrics.classification import accuracy_scoreThen we’ll upload the CSV file and use the sklearn package to create a DBN model. Also, divide the test set and training set into 25% and 75%, respectively. The output was then forecast and saved in y pred. Finally, we calculated the Accuracy score and displayed it on the screen.
digits = pd.read_csv("train.csv")
from sklearn.preprocessing import standardscaler
X = np.array(digits.drop(["label"], axis=1))
Y = np.array(digits["label"])
ss=standardscaler()
X = ss.fit_transform(X)
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.25)
clasifier = SupervisedDBNClassification(hidden_layers_structure =[256, 256], learning_rate_rbm=0.05, learning_rate=0.1, n_epochs_rbm=10, n_iter_backprop=100, batch_size=32, activation_function='relu', dropout_p=0.2)
clasifier.fit(x_train, y_train)
y_pred = classifier.predict(x_test)
print('nAccuracy of Prediction: %f' % accuracy_score(x_test, y_pred))
Output
Accuracy of Prediction: 93.3%How do you train a Deep Belief Network effectively?
Training a Deep Belief Network (DBN) involves a two-stage process: pre-training and fine-tuning. Here’s a breakdown of effective techniques for each stage:
- Greedy Layer-wise Training:
- DBNs (Deep Belief Networks) are constructed from stacked Restricted Boltzmann Machines (RBMs).
- Each RBM is trained one at a time in a greedy fashion. This approach uses the output from the previously trained RBM as the input for the next one, enhancing the learning models incrementally.
- Contrastive Divergence:
- A common algorithm used to train RBMs.
- It involves a positive phase where data probabilities are computed and a negative phase that reconstructs the data. This helps the RBM learn good representations of the input data through a discriminative process.
- Choice of Learning Rate:
- The learning rate determines how much the weights of the network are adjusted during training.
- Experimenting with different rates is essential to find the optimal rate that maximizes learning for your specific dataset.
Fine-tuning (Supervised):
- Supervised Learning Algorithm:
- Once the RBMs are pre-trained, stack them together to form a DBN.
- Use a supervised learning algorithm like backpropagation to fine-tune the entire network for your specific task, whether it be classification, regression, etc. This step transitions from unsupervised to supervised learning.
- Regularization Techniques:
- Regularization helps prevent overfitting by penalizing the complexity of the model.
- Techniques like dropout and weight decay can be employed during fine-tuning to ensure that the model generalizes well to new data.
Conclusion
- A DBN is sometimes narrated as a stack of Restricted Boltzmann machines (RBMs) placed on top of one another.
- We create Deep Belief Networks (DBNs) to address issues with classic neural networks in deep layered networks.
- A number of smaller unsupervised neural networks makes up a Deep belief networks. We can calculate the binary states of the hidden layers in the positive phase by computing the probabilities of weights and visible units.
- Although the layers are connected the network does not have connections between units inside a single layer, which is a common feature of deep belief networks.
- It’s necessary to remember that constructing a Deep Belief Network necessitates training each RBM layer. The greedy learning algorithm trains one RBM at a time until all of the RBMs are trained.
- There is a multilayer for these algorithms in neural computation.
Frequently Asked Questions
Q1. What is DBN used for?
A. A Deep Belief Network (DBN) is a type of artificial neural network used for unsupervised learning tasks such as feature learning, dimensionality reduction, and generative modeling. It consists of multiple layers of hidden units that learn to represent data in a hierarchical manner. DBNs have applications in various fields, including image recognition, natural language processing, and collaborative filtering.
Q2. What is DBN in artificial intelligence?
A. DBN stands for Deep Belief Network, a type of artificial neural network in AI. It comprises multiple layers of hidden units that learn to represent data hierarchically. DBNs are used for unsupervised learning tasks, like feature learning, dimensionality reduction, and generative modeling, finding applications in image recognition, natural language processing, and collaborative filtering.
Please feel free to leave a remark below if you have any queries or concerns about the blog. Head on to our blog for the latest articles.
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion
A graduate in Computer Science and Engineering from Tezpur Central University. Currently, I am pursuing my M.Tech in Computer Science and Engineering in the Department of CSE at NIT Durgapur. I expect to Postgraduate in the spring, 2022. A Grounded and Solution-oriented Computer Engineer with a wide variety of experiences. Adept at motivating self and others. Passionate about programming and educating the next generation of technology users and innovators.






You should probably give credit to the person who wrote that code. It seems to be a direct use of albertup's Github example of DBNs...The dbn.tensorflow module does not exist, it was created by albertup. As is, the code doesn't run and is missing most of the code needed to train a DBN
how to install module dbn