AI systems feel smarter than ever. They answer quickly, confidently, and with polish. But beneath that surface, something subtle is going wrong. Outputs are getting safer. Ideas are getting narrower. Surprise is disappearing – less aweful.
This matters because AI is increasingly involved in how we search, decide, create, and evaluate. When these systems lose range, they don’t just get worse at edge cases. They stop seeing people who live at the edges. This phenomenon is called model collapse.
This article goes over what Model collapse is, what causes it and how it can be prevented.
Table of contents
Want an quick overview of this article? You can go through the following short on the same:
What Is Model Collapse?
Based on the Nature research paper: Model collapse is a phenomenon where machine learning models gradually degrade due to errors coming from uncurated training on the outputs of another model, such as prior versions of itself.

Similar to Subliminal learning where the bias of the models gets passed on if the same family models are used to train the later models, in model collapse, the knowledge of the model gets narrowed and limited due to restrictions from synthetic training data.
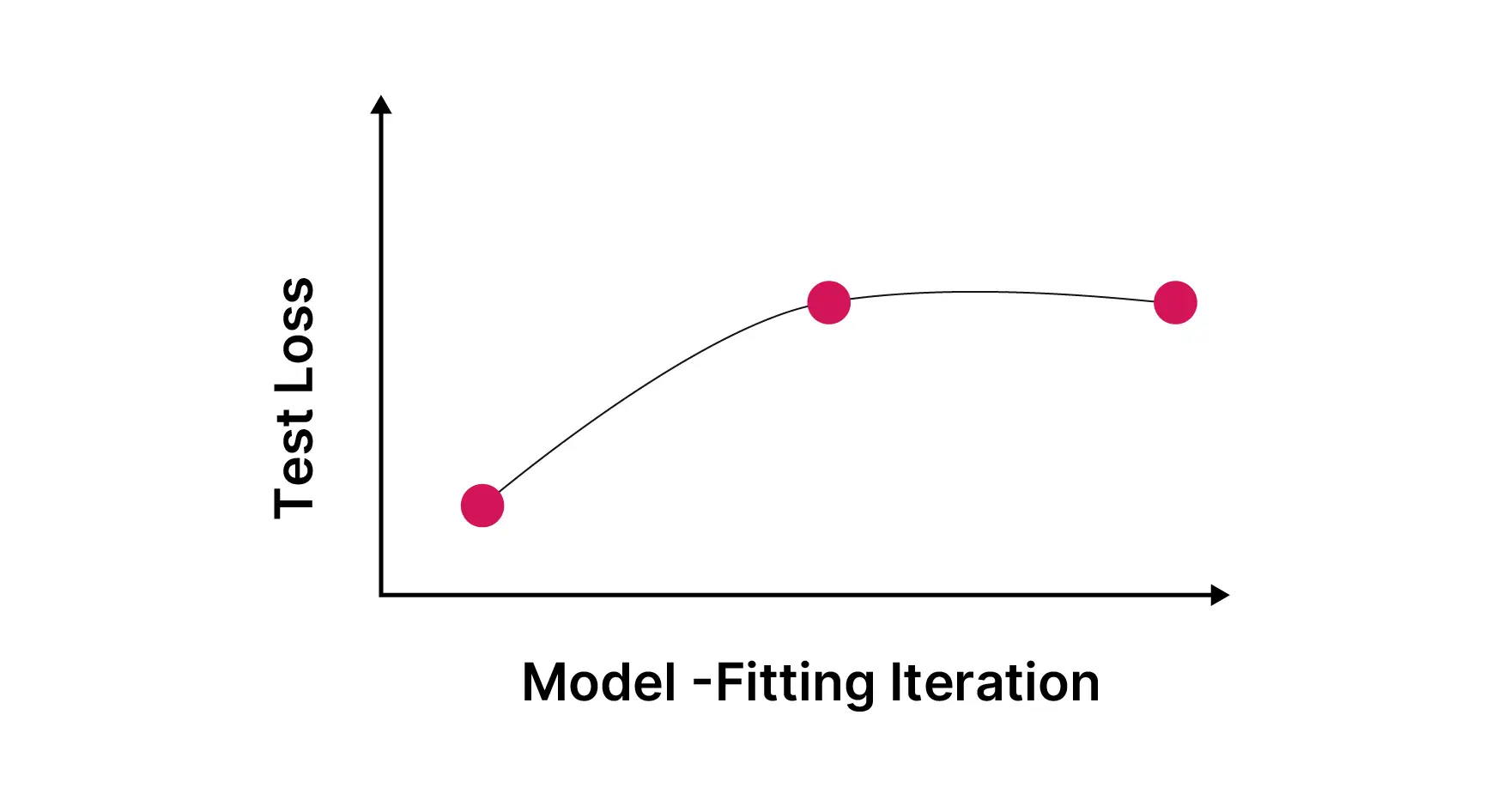
Nothing crashes. Benchmarks still look fine. Average performance stays strong. But the model slowly loses range. Rare cases fade out and uncommon perspectives disappear. Outputs converge toward what is most typical, frequent, and statistically safe.
Over time, the model doesn’t fail. It narrows. It’s still operating but “Average” becomes the only thing it understands. Edge cases or outliers that would’ve been easily responded to previously, are out of bounds now.
What Causes Model Collapse?
The mechanism is simple, which is why it’s dangerous. It’s easy to overlook this problem, if one can’t discern where the data originated from.
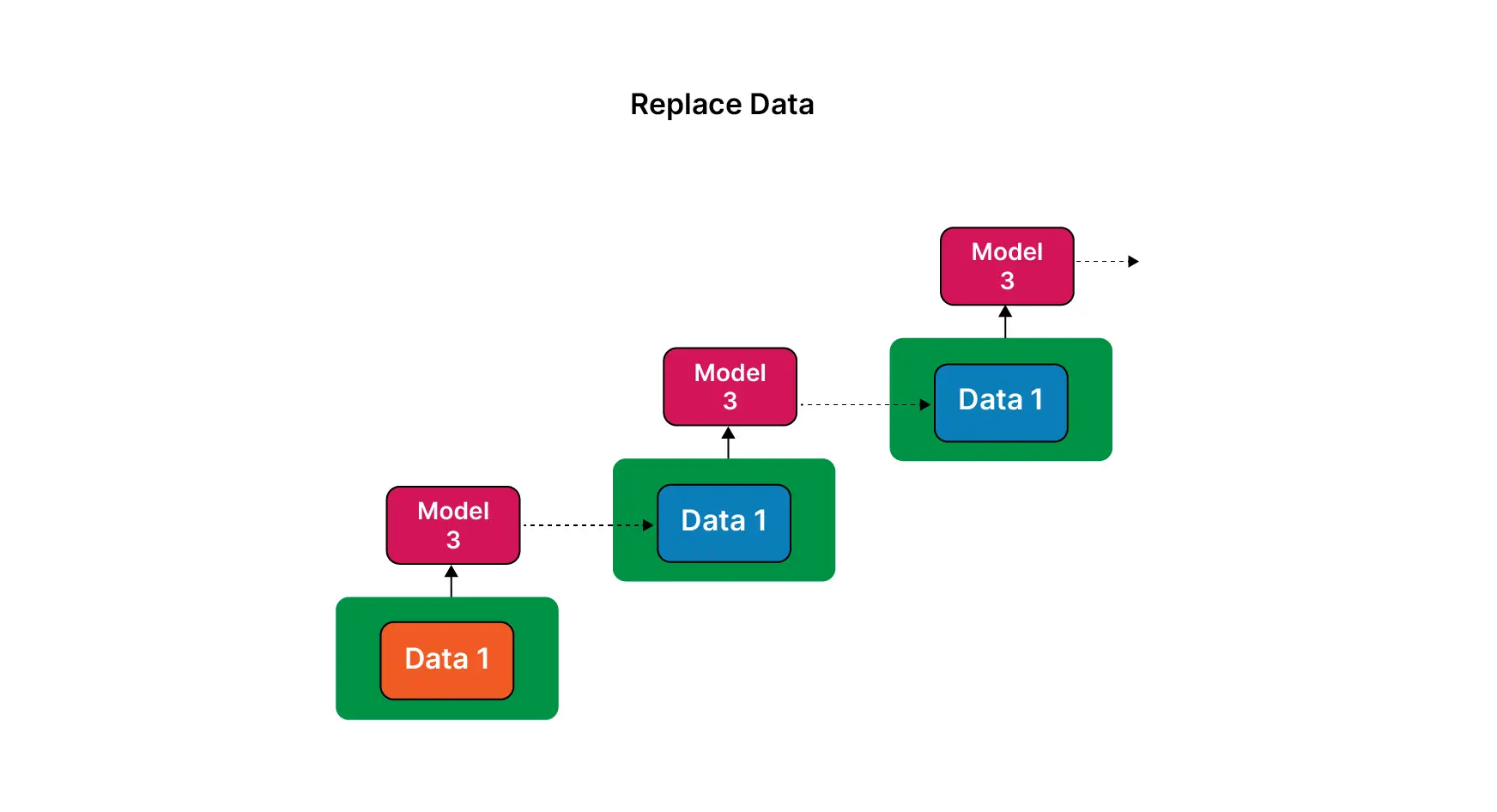
Early models learnt mostly from human-created data. But as AI-generated content spreads across the web, datasets, and internal pipelines, newer models increasingly train on synthetic outputs. Each generation inherits the blind spots of the last and amplifies them.
This problem is accentuated when the data is used indiscriminately for training regardless of its source. This relays the patterns from one model on to the next. Therefore, the model instead of getting a wider perspective, gets closely fitted to the previous model’s behavior.
Due to this, rare data is the first to go. The model doesn’t notice or takes it into consideration while it’s training. Confidence remains high. This isn’t a bug or a one-time mistake. It’s cumulative and generational. Once information falls out of the training loop, it’s often gone for good. The likelihood of grasping foreign relations further decreases as this cycle continues.
Model Collapse Affecting Different Models Types
Here are some of the ways through which model collapse influences AI models of different modalities:
- Text models start sounding fluent but hollow. Answers are coherent yet repetitive. New ideas get replaced by recycled phrasing and consensus-safe takes. Ex. em-dash usage exploding in AI model responses.
- Recommendation systems stop surprising you. Feeds feel narrower, not because you changed, but because the system optimized curiosity away. Ex. people who had outgrown their previous interests in media, are continually offered recommendations that are akin to what they previously were into.
- Image and video models converge on familiar styles and compositions. Variation exists, but within a shrinking aesthetic box. Ex. Different AI models creating human images with 6 fingers, instead of 5.
These systems aren’t malfunctioning. They’re optimizing themselves into sameness.
How Can Model Collapse Be Prevented?
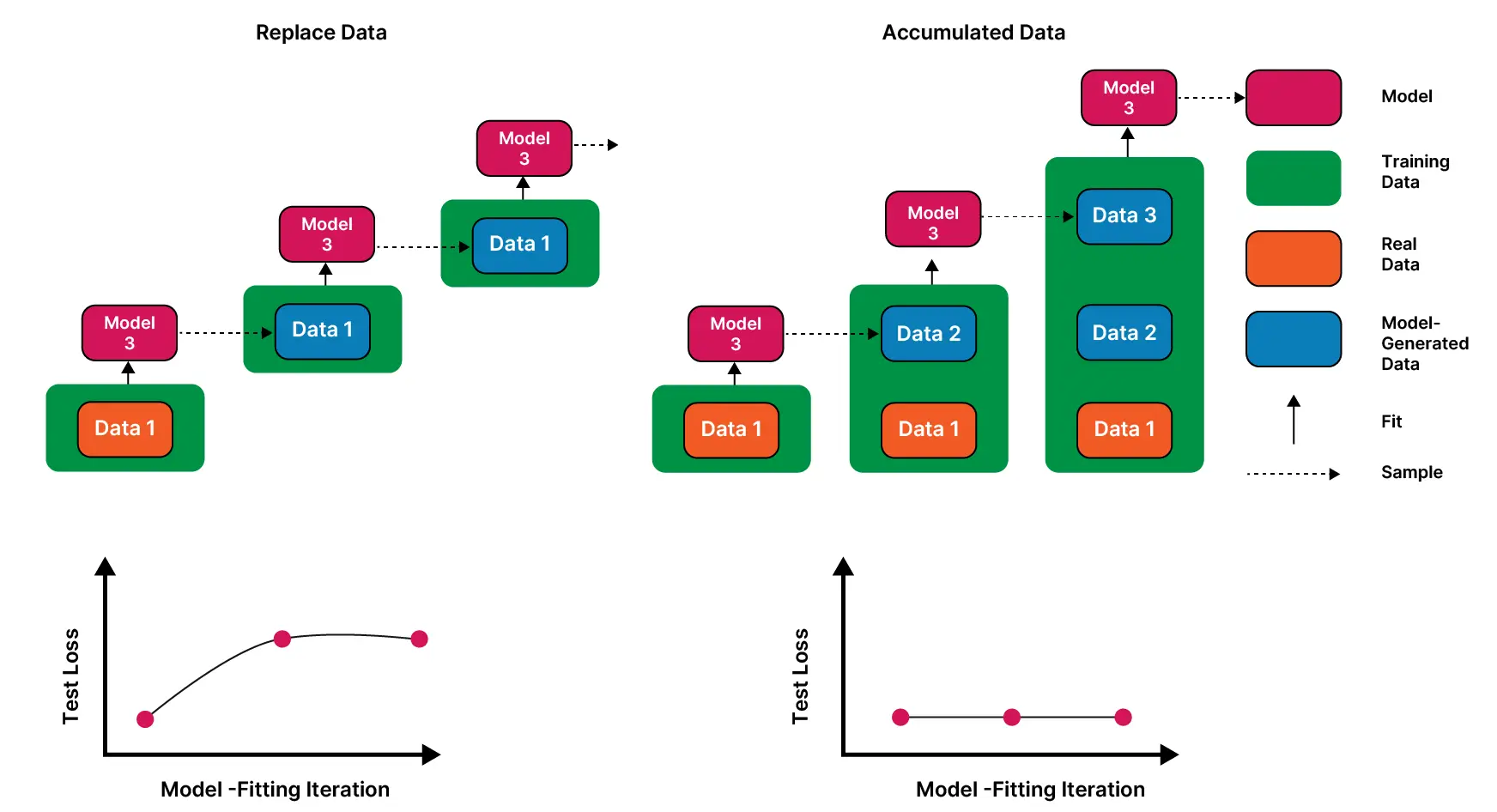
There’s no clever trick or architectural breakthrough that fixes this. Provenance is the key! It isn’t about what is rejected, but rather when is allowed to go in.
- Preserve and prioritize human-generated data: Create splits with clear classification between AI-generated and human-generated data.
- Origin: Track the origin of training data instead of treating it as interchangeable.
- Confidence over Convenience: Avoid replacing real-world complexity with synthetic convenience. It might be expedient to use AI-generated data over humane one, as it can be easily curated. But the downside is center-biased behavior.
- Range: Actively value variance. This assures that even though most the inputs might be in the same bucket, there is room open for others as well. Even though it reduces efficiency or short-term performance, it’s a viable strategy for preventing preventing overfitting.
- Inclusiveness: Treat rare cases as assets, not noise. Those outliers are a gateway to out-of-the-box thinking, and should be treated similarly.
This isn’t about smarter models. It’s about better judgment in how they’re trained and refreshed.
Conclusion
If there is one thing that can be said for sure, it is that self-consumption of AI data for models can be disastrous. Model collapse is another proposition in the ever increasing thesis of Not using AI data for training AI – Recursivly. If models are trained continually on AI data, they tend to degrade. Model and mode collapse, both hint in the same direction. This should be used as a precautionary warning for those who tend to be indifferent towards the source of their training data.
Frequently Asked Questions
Q1. What is model collapse?
A. It’s the gradual narrowing of an AI model’s capabilities when trained on uncurated AI-generated data, causing rare cases and diversity to disappear. pasted
Q2. Why is model collapse dangerous?
A. Models stay confident and performant on averages while silently failing edge cases, leading to biased, repetitive, and less inclusive outcomes. pasted
Q3. Can model collapse be prevented?
A. Yes. By prioritizing human data, tracking data origin, and treating rare cases as assets rather than noise. pasted
I specialize in reviewing and refining AI-driven research, technical documentation, and content related to emerging AI technologies. My experience spans AI model training, data analysis, and information retrieval, allowing me to craft content that is both technically accurate and accessible.






