This article was published as a part of the Data Science Blogathon.
Introduction
The concept of cleaning and cleansing spiritually, and hygienically are all very valuable in any healthy living lifestyle.
Datasets are somewhat the same. Without cleaning and cleansing in the data science lifecycle or as a routine activity, the code for any purpose would simply not work.
In data analytics, there are many lifecycles that are chosen. Here, the CRISP-DM framework was chosen and focused on step 3 – Data Preparation.
Benefits and Learning Outcomes:
- Reference guide for educational purposes
- Resolve one of several issues in a code
- Data types and data structures
- Become familiar with DataBricks, RStudio, and Python Programming Shell
- Become comfortable with switching between Python and R Programming in various environments
- Familiarizing with a few steps in the CRISP-DM framework
Requirements may include:
- Basic knowledge of data types
- A slight attention to detail
- Basic knowledge of statistics and math
- Comfortable with switching between programming and coding languages on different platforms
- General knowledge of CRISP-DM
- Basic knowledge of “Big Data” software such as Apache Spark for Python Programming and its associated libraries
The article includes Python Programming and R-Programming in a combination of Python Shell, DataBricks, and RStudio.
Note: This assumes that the libraries and codes are all compatible and familiarized with reasonable access to the mentioned platforms.
Order Sequence
- CRISP-DM: Data Preparation
- CRISP-DM: Data modelling
Examples
Linear Regression using numerical Multiclassification
Clustering with K-means
Decision Tree with ROC/AUC scores
First, CRISP-DM: Data Preparation:
No matter which packages and modules in the code, data types will determine if your dataset can be fed into the algorithm using code.
The following Python Programming data types could include but not limited to:
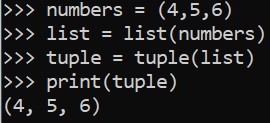
Tuple
numbers = (4,5,6) list = list(numbers) tuple = tuple(list) print(tuple) (4,5,6)
Vector transformation
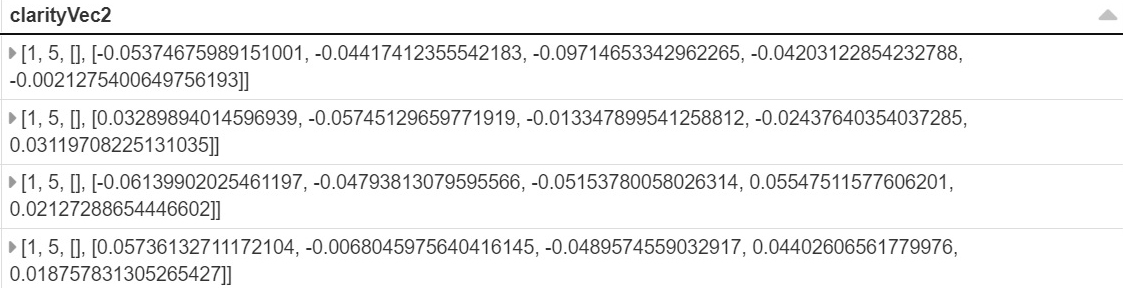
String or String Array to a Vector data type in DataBricks
DataBricks is an online platform similar to a cloud to allow coding for educational purposes.
DataBricks consists of its own structures and directories or paths. Starting a “Kernel” is always a must in order to use any programming language.
The platform almost resembles a coding notebook and visualizing data is user-friendly.
import Word2Vec word2Vecclarity = Word2Vec(vectorSize=5, seed-42, inputCol="clarityVec", outputCol="clarityVec2") model=word2vecclarity.fit(diamonds) diamonds = model.transformation(diamonds) display(diamondsa)
Matrix
The number of arrays (more than one) dimensions determines whether that array is a matrix.
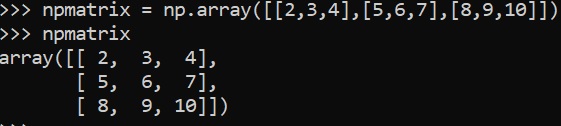
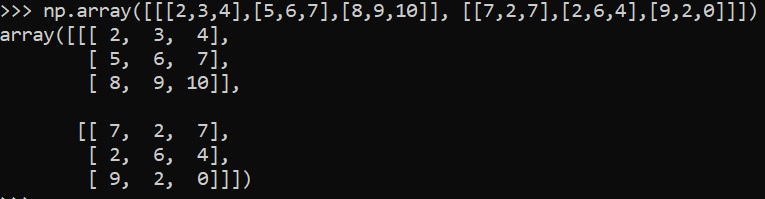
np.array([[2,3,4],[5,6,7],[8,9,10]])
np.array([[[2,3,4],[5,6,7],[8,9,10]], [[7,2,7],[2,6,4],[9,2,0]]])
Array
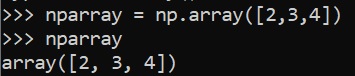
np.array([2,3,4])
List

ingredients = 'apple', 'orange', 'strawberry' list = list(ingredients) print(list) ['apple','orange','strawberry']
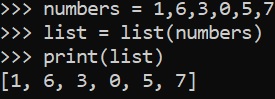
numbers = 1, 6, 3, 0, 5, 7 list = list(numbers) print(list) [1, 6, 3, 0, 5, 7]
String

str('I have quotation marks')
Integer
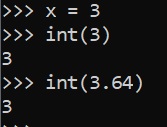
x = 3
int(x)
int(3.64)
3
Float
Integers will have the tenth decimal place added to its value.
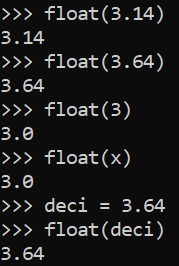
Negative Float
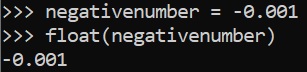
Data types are important when transforming datasets into visuals, storing data, and/or using datasets for machine learning predictions.
Second, CRISP-DM: Data Modelling
Once successfully cleaned, data modelling can be done.
Here are some models and a brief synopsis of each:
| Model | Key Differences |
| Linear Regression |
|
| Logistic Regression |
|
| Cluster |
|
| Decision Tree |
|
| Random Forest |
|
| Neural Network |
|
| Classification |
|
Although these are the usual definitions, models can be combined into one code and could be used for different purposes.
Knowledge of some statistical probability distributions would be helpful to measure performance and accuracy scores. Another purpose for a probability distribution is Hypothesis Testing.
Some probability distributions include:
- Uniform
- Normal Distribution or Bell Curve
- Gaussian
- Poisson
- Exponential
- Geometric
- Binomial
- Bernoulli
Some measurement scoring metrics include:
- Correlation: R and R2
- RMSE
- Measures of central tendency
- Ordinary Least Squares regression information chart
- ROC (receiver operating characteristic curve) and AUC scores
Example 1: Linear Regression using numerical Multi classification
This data set was about jewelry prices.
The example used for vectors in python displayed in a Databricks platform can help explain how any machine learning code or algorithm would need specific data structures and data types. From text to numeric, changing data types for selected columns can produce a valid data set to be fed into a machine learning algorithm.
Since the price was involved in this example, different variations of numbers known as continuous numbers were included. This is an indication to use a numerical Multi classification method to measure.
The image below is a data type scheme of the data set:

After feeding the cleaned data set into any machine learning algorithm of your choosing (this example used Python Spark), visualizations can be made.
The pictures below are visualizations of the data set in DataBricks.
Interpretation: Predictions were closely related to prices with some noise from the code. This was a successful machine learning code and visualization. If DataBricks is not available, then graph according to the library (Matplotlib, Seaborn) that you prefer and overlap price and prediction together with graph labels and color of plots of choice.
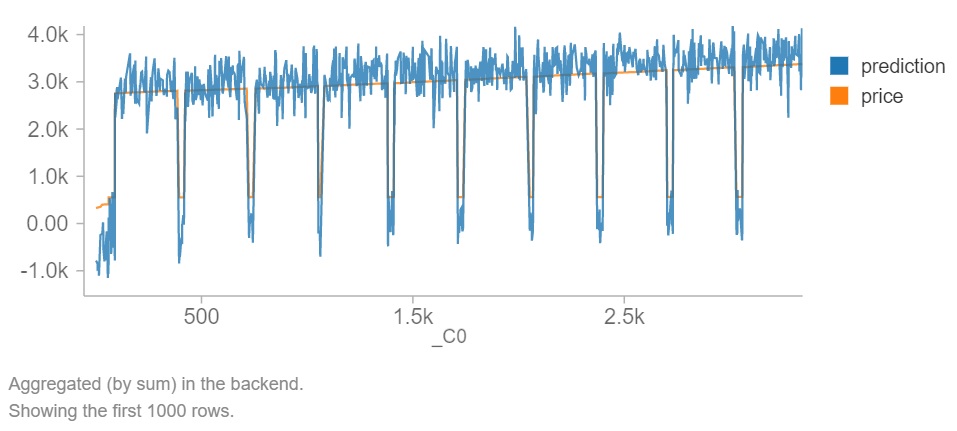
Interpretation: The differences between prediction and price data points. _C0 is an ID number and did not have much value in correlation or statistical results. However, it did seem to show patterns of fluctuations with both peaks and valleys. This is a close examination of noise.
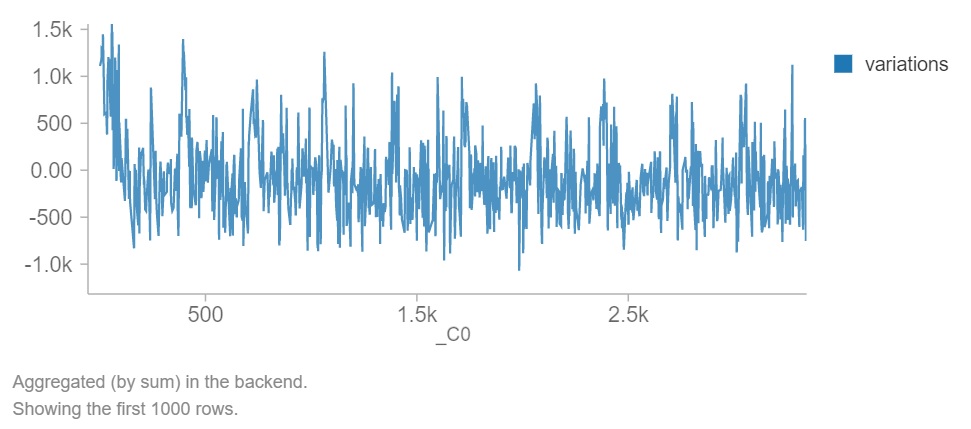
Another benefit after cleaning is the opportunity to measure the results with metrics.
Here is a good list of decent results.
The results show that the code can predict the price of the piece of jewelry.
While explained variance, root mean squared error, mean absolute error, and mean squared error are listed, there are specific ranges that referred to before judging the results. Judgments are based on prior research results and determining how credible and reliable those results were compared to the past. These numbers would ultimately be placed on a ranging scale. If these numbers are between the minimum and maximum ranges, it would be acceptable. if not, unacceptable. In short, it is based on context.
R-squared values and r values are always known to be a number between 0 and 1. Referring to correlation strength. 0 meaning weak and 1 meaning strong.
After importing sqrt from math, the following metrics can be made.
print(metrics.explainedvariance) print(metrics.rootMeanSquaredError) print(metrics.meanAbsoluteError) print(metrics.meanSquaredError) print(metrics.r2) print(sqrt(metrics.r2)) explained variance: 16578542.773449434 root mean squared error: 432.08042460826283 mean absolute error: 338.73641536904915 mean squared error: 186693.4933296567 r-squared value: 0.9881558295874991 r-value: 0.9940602746249843
Example 2: Clustering with K-means
Binary or limited to two categories
This data set was about financial credit data. The goal was to detect financial fraud before proceeding to serve the individual’s account.
The options are limitless, Here are a few examples in RStudio using Python Programming language.
The code below shows: package installation, Kernel, and Spark Context settings
library(reticulate) repl_python()
from pyspark.sql.session import SparkSession
from pyspark import *
from pyspark import SparkContext
from pyspark import SparkConf
from pyspark.sql.functions import col
from pyspark.sql import SQLContext
import ctypes
import pandas as pd
import numpy as np
# Change "kernel" settings
kernel32 = ctypes.WinDLL('kernel32', use_last_error=True) # should equal to 1
# This line of code should output 1
kernel32.SetStdHandle(-11, None) # should equal to 1
# This line of code should also be an output of 1
kernel32.SetStdHandle(-12, None)
conf = SparkContext(conf=SparkConf().setMaster("local").setAppName("PySparkR").set('spark.executor.memory', '4G'))
sqlContext = SQLContext(conf)
K-means clustering was the statistical model used to structure the predictions in this example for binary or categorizing data set predictions into two areas. The results helped differentiate data points to accurately predict future values.
Here, “Predictionst” – the number of clusters chosen are counted within a Python Spark data frame.
| Predictionst | count |
| 0 | 827 |
| 1 | 173 |

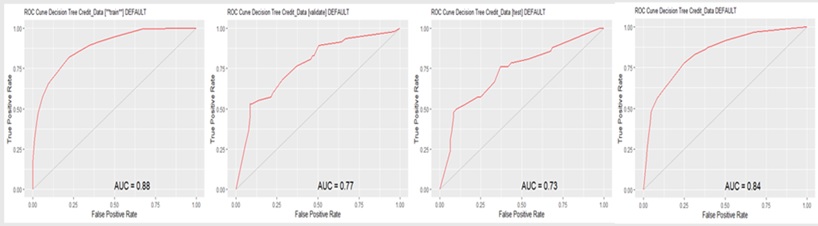
Example 3: Decision Tree with ROC/AUC scores
This data set was about the same financial credit data set mentioned previously.
Here are some metric scores of the data set.
ROC (receiver operating characteristic curve) scores in RStudio using Rattle.
From the RStudio datasets typed in Python programming language, it is possible to transition the variable holding the data set into R and Rattle.
A different model was used, but the same data set was used. A ROC/AUC scores were acknowledged as decent scores.
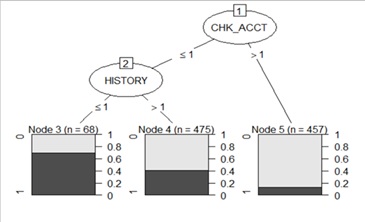
Partial Decision Tree Outputs:
Interpretation: This image is a section of the decision tree. The picture shows the strengths and weaknesses of each variable within the data set.
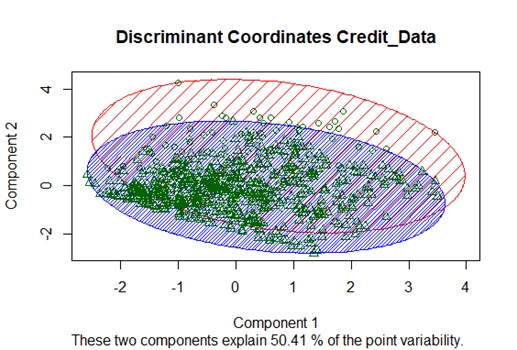
Interpretation: The picture below used Rattle in R-Programming to show a visualization of discriminant coordinates between data points. Because K-means with 2 clusters set, two clusters were shown and data points were represented as triangles for one extreme and circles for another extreme.
Recap and Conclusion
- Data modelling and evaluations can be processed successfully after data preparation.
- Data preparation is one step in the CRISP-DM framework.
- Without data preparation or cleaning the data set, codes will bring errors.
- Although not the only issue in coding, it is certainly one of several reasons.
- Beneficial to learn more than one programming language to accomplish a common goal.
- Data models and probability distribution can be combined.
- Visuals could be easily accessible with another programming language.
- It is possible to use one common platform to write in several languages.
—
—
References
[1] W3schools, (2020). Python Change Tuple Values. Python Tuple Data Types on W3schools.
[2] W3schools, (2020). Python – Matrix. Python Matrix on W3schools.
[3] Scikit-Learn, (2020). Choosing the right estimator. Estimators on Scikit-Learn.
Short Author Bio:
My name is Priya Kalyanakrishnan, and I have one Master of Science graduate degree in Data Analytics and one undergraduate 4-year bachelor’s degree in Business. Discovering practical solutions for educational purposes or everyday use are a few of my motivators to learn more alongside technological advancements.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.






