Overview
- Hadoop is among the most popular tools in the data engineering and Big Data space
- Here’s an introduction to everything you need to know about the Hadoop ecosystem
Introduction
We have over 4 billion users on the Internet today. In pure data terms, here’s how the picture looks:
That’s the amount of data we are dealing with right now – incredible! It is estimated that by the end of 2020 we will have produced 44 zettabytes of data. That’s 44*10^21!
This massive amount of data generated at a ferocious pace and in all kinds of formats is what we call today as Big data. But it is not feasible storing this data on the traditional systems that we have been using for over 40 years. To handle this massive data we need a much more complex framework consisting of not just one, but multiple components handling different operations.

We refer to this framework as Hadoop and together with all its components, we call it the Hadoop Ecosystem. But because there are so many components within this Hadoop ecosystem, it can become really challenging at times to really understand and remember what each component does and where does it fit in in this big world.
So, in this article, we will try to understand this ecosystem and break down its components.
Table of contents
Problem with Traditional Systems
By traditional systems, I mean systems like Relational Databases and Data Warehouses. Organizations have been using them for the last 40 years to store and analyze their data. But the data being generated today can’t be handled by these databases for the following reasons:
- Most of the data generated today are semi-structured or unstructured. But traditional systems have been designed to handle only structured data that has well-designed rows and columns
- Relations Databases are vertically scalable which means you need to add more processing, memory, storage to the same system. This can turn out to be very expensive
- Data stored today are in different silos. Bringing them together and analyzing them for patterns can be a very difficult task.
So, how do we handle Big Data? This is where Hadoop comes in!
What is Hadoop?
People at Google also faced the above-mentioned challenges when they wanted to rank pages on the Internet. They found the Relational Databases to be very expensive and inflexible. So, they came up with their own novel solution. They created the Google File System (GFS).
GFS is a distributed file system that overcomes the drawbacks of the traditional systems. It runs on inexpensive hardware and provides parallelization, scalability, and reliability. This laid the stepping stone for the evolution of Apache Hadoop.
Apache Hadoop is an open-source framework based on Google’s file system that can deal with big data in a distributed environment. This distributed environment is built up of a cluster of machines that work closely together to give an impression of a single working machine.
Here are some of the important properties of Hadoop you should know:
- Hadoop is highly scalable because it handles data in a distributed manner
- Compared to vertical scaling in RDBMS, Hadoop offers horizontal scaling
- It creates and saves replicas of data making it fault-tolerant
- It is economical as all the nodes in the cluster are commodity hardware which is nothing but inexpensive machines
- Hadoop utilizes the data locality concept to process the data on the nodes on which they are stored rather than moving the data over the network thereby reducing traffic
- It can handle any type of data: structured, semi-structured, and unstructured. This is extremely important in today’s time because most of our data (emails, Instagram, Twitter, IoT devices, etc.) has no defined format
Now, let’s look at the components of the Hadoop ecosystem.
Components of the Hadoop Ecosystem

In this section, we’ll discuss the different components of the Hadoop ecosystem.
HDFS (Hadoop Distributed File System)

It is the storage component of Hadoop that stores data in the form of files.
Each file is divided into blocks of 128MB (configurable) and stores them on different machines in the cluster.
It has a master-slave architecture with two main components: Name Node and Data Node.
- Name node is the master node and there is only one per cluster. Its task is to know where each block belonging to a file is lying in the cluster
- Data node is the slave node that stores the blocks of data and there are more than one per cluster. Its task is to retrieve the data as and when required. It keeps in constant touch with the Name node through heartbeats
MapReduce

To handle Big Data, Hadoop relies on the MapReduce algorithm introduced by Google and makes it easy to distribute a job and run it in parallel in a cluster. It essentially divides a single task into multiple tasks and processes them on different machines.
In layman terms, it works in a divide-and-conquer manner and runs the processes on the machines to reduce traffic on the network.
It has two important phases: Map and Reduce.
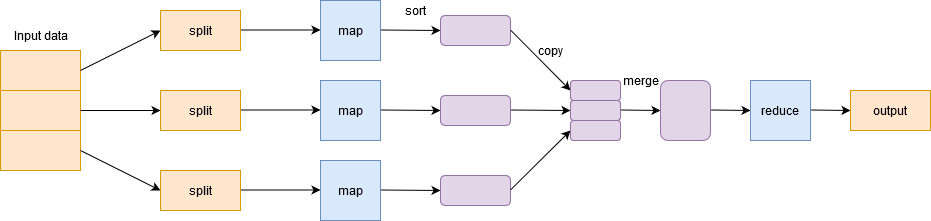
Map phase filters, groups, and sorts the data. Input data is divided into multiple splits. Each map task works on a split of data in parallel on different machines and outputs a key-value pair. The output of this phase is acted upon by the reduce task and is known as the Reduce phase. It aggregates the data, summarises the result, and stores it on HDFS.
YARN

YARN or Yet Another Resource Negotiator manages resources in the cluster and manages the applications over Hadoop. It allows data stored in HDFS to be processed and run by various data processing engines such as batch processing, stream processing, interactive processing, graph processing, and many more. This increases efficiency with the use of YARN.
HBase

HBase is a Column-based NoSQL database. It runs on top of HDFS and can handle any type of data. It allows for real-time processing and random read/write operations to be performed in the data.
Pig

Pig was developed for analyzing large datasets and overcomes the difficulty to write map and reduce functions. It consists of two components: Pig Latin and Pig Engine.
Pig Latin is the Scripting Language that is similar to SQL. Pig Engine is the execution engine on which Pig Latin runs. Internally, the code written in Pig is converted to MapReduce functions and makes it very easy for programmers who aren’t proficient in Java.
Hive

Hive is a distributed data warehouse system developed by Facebook. It allows for easy reading, writing, and managing files on HDFS. It has its own querying language for the purpose known as Hive Querying Language (HQL) which is very similar to SQL. This makes it very easy for programmers to write MapReduce functions using simple HQL queries.
Sqoop

A lot of applications still store data in relational databases, thus making them a very important source of data. Therefore, Sqoop plays an important part in bringing data from Relational Databases into HDFS.
The commands written in Sqoop internally converts into MapReduce tasks that are executed over HDFS. It works with almost all relational databases like MySQL, Postgres, SQLite, etc. It can also be used to export data from HDFS to RDBMS.
Flume

Flume is an open-source, reliable, and available service used to efficiently collect, aggregate, and move large amounts of data from multiple data sources into HDFS. It can collect data in real-time as well as in batch mode. It has a flexible architecture and is fault-tolerant with multiple recovery mechanisms.
Kafka

There are a lot of applications generating data and a commensurate number of applications consuming that data. But connecting them individually is a tough task. That’s where Kafka comes in. It sits between the applications generating data (Producers) and the applications consuming data (Consumers).
Kafka is distributed and has in-built partitioning, replication, and fault-tolerance. It can handle streaming data and also allows businesses to analyze data in real-time.
Oozie

Oozie is a workflow scheduler system that allows users to link jobs written on various platforms like MapReduce, Hive, Pig, etc. Using Oozie you can schedule a job in advance and can create a pipeline of individual jobs to be executed sequentially or in parallel to achieve a bigger task. For example, you can use Oozie to perform ETL operations on data and then save the output in HDFS.
Zookeeper

In a Hadoop cluster, coordinating and synchronizing nodes can be a challenging task. Therefore, Zookeeper is the perfect tool for the problem.
It is an open-source, distributed, and centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services across the cluster.
Spark

Spark is an alternative framework to Hadoop built on Scala but supports varied applications written in Java, Python, etc. Compared to MapReduce it provides in-memory processing which accounts for faster processing. In addition to batch processing offered by Hadoop, it can also handle real-time processing.
Further, Spark has its own ecosystem:

- Spark Core is the main execution engine for Spark and other APIs built on top of it
- Spark SQL API allows for querying structured data stored in DataFrames or Hive tables
- Streaming API enables Spark to handle real-time data. It can easily integrate with a variety of data sources like Flume, Kafka, and Twitter
- MLlib is a scalable machine learning library that will enable you to perform data science tasks while leveraging the properties of Spark at the same time
- GraphX is a graph computation engine that enables users to interactively build, transform, and reason about graph-structured data at scale and comes with a library of common algorithms
Stages of Big Data Processing
With so many components within the Hadoop ecosystem, it can become pretty intimidating and difficult to understand what each component is doing. Therefore, it is easier to group some of the components together based on where they lie in the stage of Big Data processing.

- Flume, Kafka, and Sqoop are used to ingest data from external sources into HDFS
- HDFS is the storage unit of Hadoop. Even data imported from Hbase is stored over HDFS
- MapReduce and Spark are used to process the data on HDFS and perform various tasks
- Pig, Hive, and Spark are used to analyze the data
- Oozie helps to schedule tasks. Since it works with various platforms, it is used throughout the stages
- Zookeeper synchronizes the cluster nodes and is used throughout the stages as well
End Notes
I hope this article was useful in understanding Big Data, why traditional systems can’t handle it, and what are the important components of the Hadoop Ecosystem.
I encourage you to check out some more articles on Big Data which you might find useful:
I am on a journey to becoming a data scientist. I love to unravel trends in data, visualize it and predict the future with ML algorithms! But the most satisfying part of this journey is sharing my learnings, from the challenges that I face, with the community to make the world a better place!







Thanx Aniruddha for a thoughtful comprehensive summary of Big data Hadoop systems.
Hello Sir)Mam, I hope you are well. I am Vishnu kant shukla 3rd year student from computer science department in maharana pratap engineering college kanpur. I am interested in internship opportunity, If you would give me this opportunity, my teachers and my academics taught me of identifying the purpose of the task collection of data and tools that use preparing of method and implementing it and then finally applying it. This what i know apart from that i have done few projects in my college and i am interested in this area. Thank you so much, Vishnu kant shukla
This is awesome! Detailed analysis with enough background.