For ML practitioners, the natural expectation is that a new ML model that shows promising results offline will also succeed in production. But often, that’s not the case. ML models that outperform on test data can underperform for real production users. This discrepancy between offline and online metrics is often a big challenge in applied machine learning.
In this article, we will explore what both online and offline metrics really measure, why they differ, and how ML teams can build models that can perform well both online and offline.
Table of contents
The Comfort of Offline Metrics
Offline Model evaluation is the first checkpoint for any model in deployment. Training data is usually split into train sets and validation/test sets, and evaluation results are calculated on the latter. The metrics used for evaluation may vary based on model type: A classification model usually uses precision, recall, AUC, etc, A recommender system uses NDCG, MAP, while a forecasting model uses RMSE, MAE, MAPE, etc.
Offline evaluation makes rapid iteration possible as you can run multiple model evaluations per day, compare their results, and get quick feedback. But they have limits. Evaluation results heavily depend on the dataset you choose. If the dataset does not represent production traffic, you can get a false sense of confidence. Offline evaluation also ignores online factors like latency, backend limitations, and dynamic user behavior.
The Reality Check of Online Metrics
Online metrics, by contrast, are measured in a live production setting via A/B testing or live monitoring. These metrics are the ones that matter to the business. For recommender systems, it can be funnel rates like Click-through rate (CTR) and Conversion Rate (CVR), or retention. For a forecasting model, it can bring cost savings, a reduction in out-of-stock events, etc.
The obvious challenge with online experiments is that they are expensive. Each A/B test consumes experiment traffic that could have gone to another experiment. Results take days, sometimes even weeks, to stabilize. On top of that, online signals can sometimes be noisy, i.e., impacted by seasonality, holidays, which can mean more data science bandwidth to isolate the model’s true effect.
| Metric Type | Pros & Cons |
| Offline Metrics, eg: AUC, Accuracy, RMSE, MAPE |
Pros: Fast, Repeatable, and cheap Cons: Does not reflect the real world |
| Online Metrics, eg: CTR, Retention, Revenue |
Pros: True Business impact reflecting the real world Cons: Expensive, slow, and noisy (impacted by external factors) |
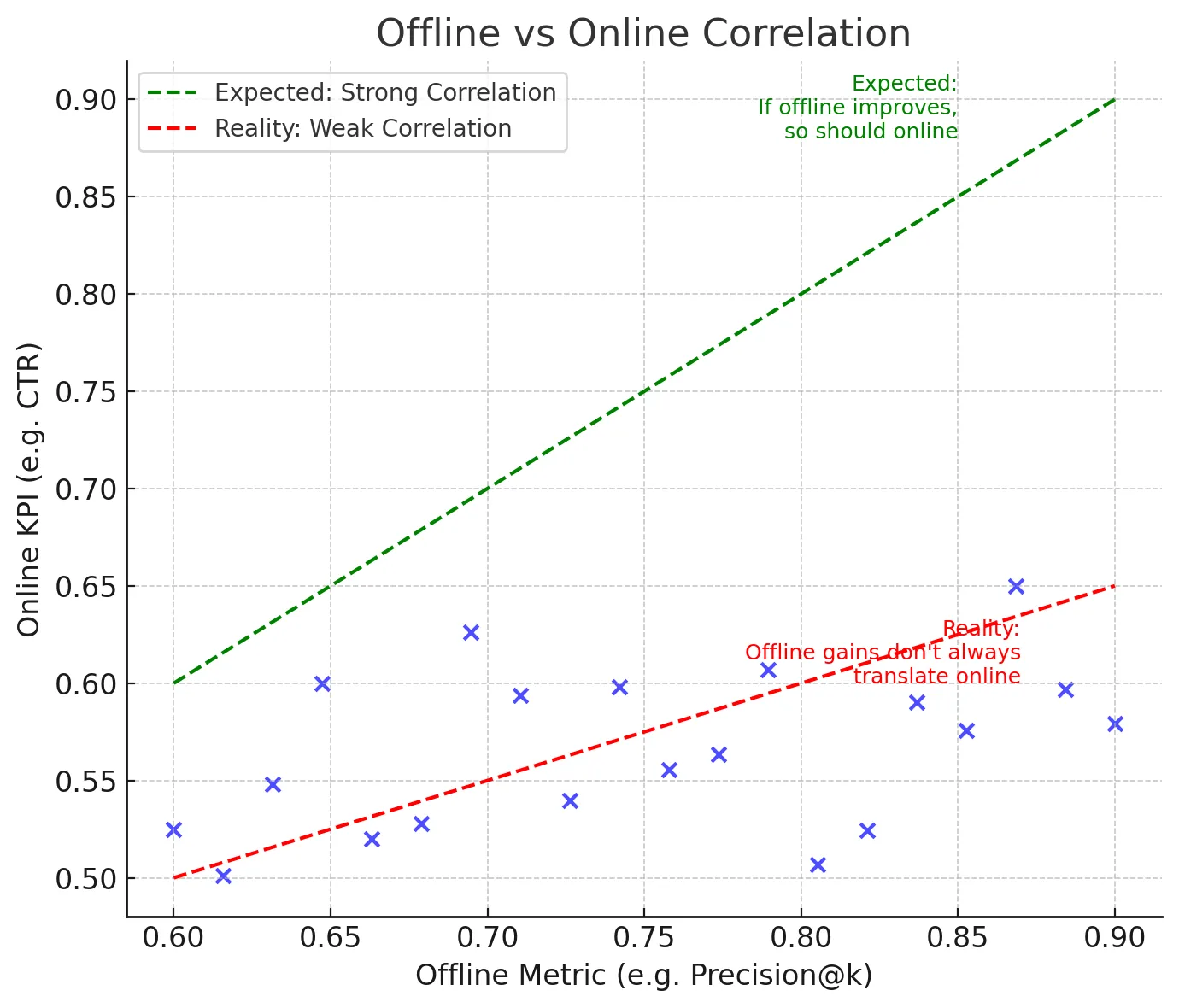
The Online-Offline Disconnect
So why do models that shine offline stumble online? Firstly, user behavior is very dynamic, and models trained in the past may not be able to keep up with the current user demands. A simple example for this is a recommender system trained in Winter may not be able to provide the right recommendations come summer since user preferences have changed. Secondly, feedback loops play a pivotal part in the online-offline discrepancy. Experimenting with a model in production changes what users see, which in turn changes their behavior, which impacts the data that you collect. This recursive loop does not exist in offline testing.
Offline metrics are considered proxies for online metrics. But often they don’t line up with real-world goals. For Example, Root Mean Squared Error ( RMSE ) minimises overall error but can still fail to capture extreme peaks and troughs that matter a lot in supply chain planning. Secondly, app latency and other factors can also impact user experience, which in turn would affect business metrics.
Bridging the Gap
The good news is that there are ways to reduce the online-offline discrepancy problem.
- Choose better proxies: Choose multiple proxy metrics that can approximate business outcomes instead of overindexing on one metric. For example, a recommender system might combine precision@k with other factors like diversity. A forecasting model might evaluate stockout reduction and other business metrics on top of RMSE.
- Study correlations: Using past experiments, we can analyze which offline metrics correlated with online successful results. Some offline metrics will be consistently better than others in predicting online success. Documenting these findings and using those metrics will help the whole team know which offline metrics they can rely on.
- Simulate interactions: There are some methods in recommendation systems, like bandit simulators, that replay user historical logs and estimate what would have happened if a different ranking had been shown. Counterfactual evaluation can also help approximate online behavior using offline data. Methods like these can help narrow the online-offline gap.
- Monitor after deployment: Despite successful A/B tests, models drift as user behavior evolves ( like the winter and summer example above ). So it is always preferred to monitor both input data and output KPIs to ensure that the discrepancy doesn’t silently reopen.
Practical Example
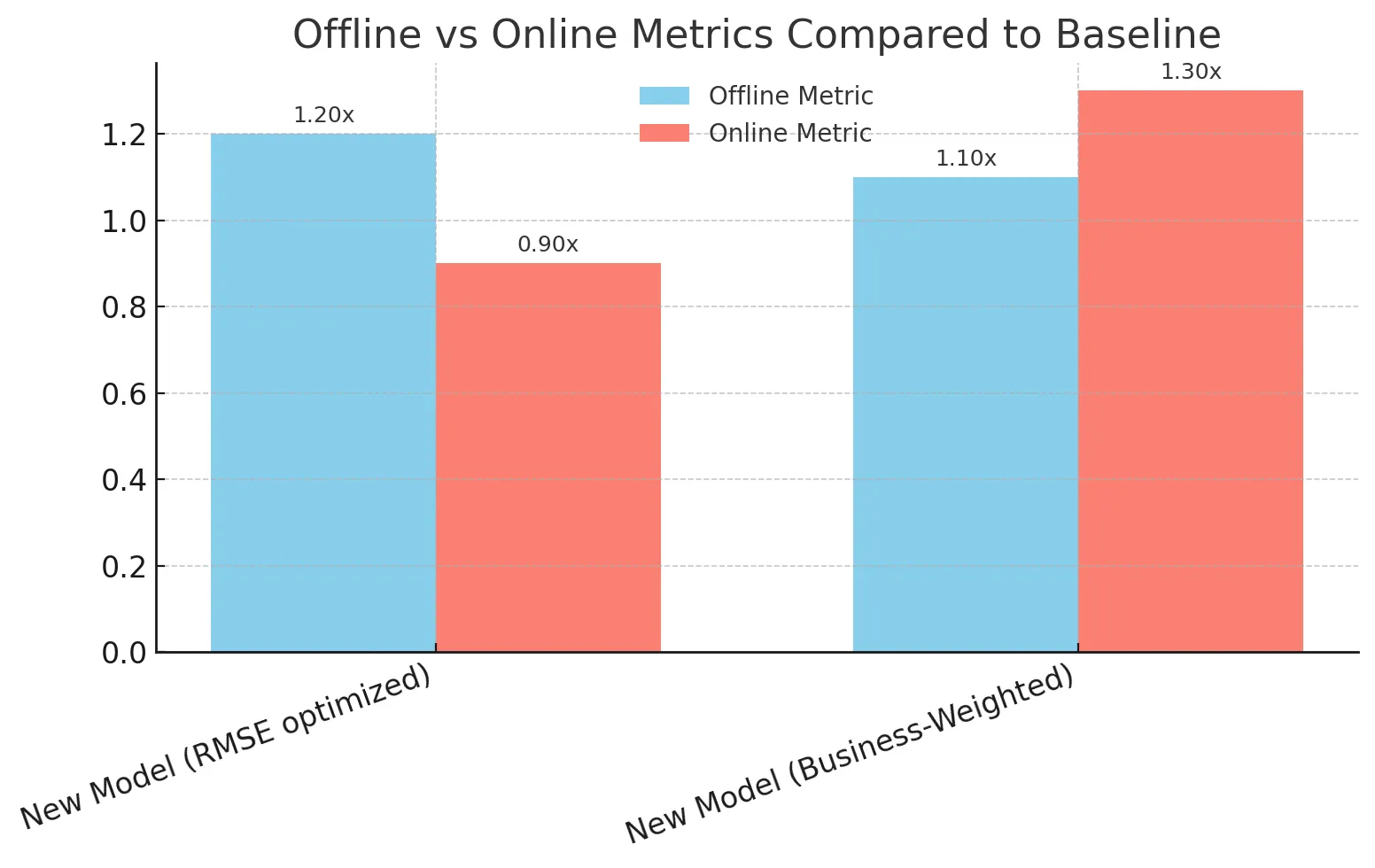
Consider a retailer deploying a new demand forecasting model. The model showed great promising results offline (in RMSE and MAPE), which made the team very excited. But when tested online, the business saw minimal improvements and in some metrics, things even looked worse than baseline.
The problem was proxy misalignment. In supply chain planning, underpredicting demand for a trending product causes lost sales, while overpredicting demand for a slow-moving product leads to wasted inventory. The offline metric RMSE treated both as equals, but real-world costs were far from being symmetric.
The team made a decision to redefine their evaluation framework. Instead of only relying on RMSE, they defined a custom business-weighted metric that penalized underprediction more heavily for trending products and explicitly tracked stockouts. With this change, the next model iteration provided both strong offline results and online revenue gains.
Closing thoughts
Offline metrics are like the rehearsals to a dance practice: You can learn quickly, test ideas, and fail in a small, controlled environment. Online metrics are like thes actual dance performance: They measure actual audience reactions and whether your changes deliver true business value. Neither alone is enough.
The real challenge lies in finding the best offline evaluation frameworks and metrics that can predict online success. When done well, teams can experiment and innovate faster, minimize wasted A/B tests, and build better ML systems that perform well both offline and online.
Frequently Asked Questions
Q1. Why do models that perform well offline fail online?
A. Because offline metrics don’t capture dynamic user behavior, feedback loops, latency, and real-world costs that online metrics measure.
Q2. What’s the main advantage of offline metrics?
A. They’re fast, cheap, and repeatable, making quick iteration possible during development.
Q3. Why are online metrics considered more reliable?
A. They reflect true business impact like CTR, retention, or revenue in live settings.
Q4. How can teams bridge the offline-online gap?
A. By choosing better proxy metrics, studying correlations, simulating interactions, and monitoring models after deployment.
Q5. Can offline metrics be customized for business needs?
A. Yes, teams can design business-weighted metrics that penalize errors differently to reflect real-world costs.
Madhura Raut is a Principal Data Scientist at Workday, where she leads the design of large-scale machine learning systems for labor demand forecasting. She is the lead inventor on two U.S. patents related to advanced time series techniques, and her ML product has been recognized as a Top HR Product of the Year by Human Resource Executive. Madhura has been keynote speaker at many prestigious data science conferences including KDD 2025 and has served as judge and mentor to multiple codecrunch hackathons.



