Recommendation systems are the invisible engines that can personalize our social media, OTTs and e-commerce. Whether you are scrolling through Netflix for a new show or browsing Amazon for a gadget, these algorithms are working behind the scenes to predict something for you. One of the most effective ways to do this is by looking at how other people with similar tastes have behaved. This is the core of modern personalization. In this article, we will explore how to build one of these systems using collaborative filtering and make it smarter using OpenAI. Without any further ado, let’s dive in.
Table of contents
What is Collaborative Filtering?
Collaborative filtering is a technique to make recommendations from a collection of different users. The intuition here is that if User 1 and User 2 both liked the same movies, they probably have similar tastes. If User 1 then watches a new movie and likes it, the system will recommend that movie to User 2. It does not need to know anything else like the genre or actors, it only needs to know who liked it.
The user-item matrix is used to perform collaborative filtering. This is generally created by using an item column like movies to create a pivot table with each value as a column in the resultant table.
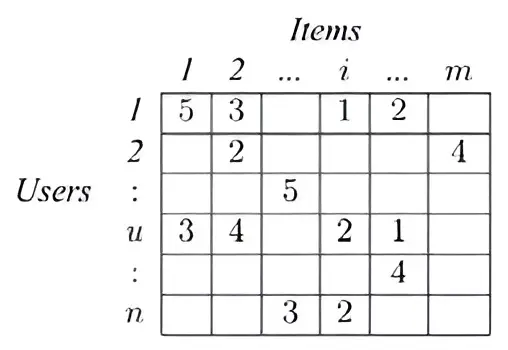
Read more: Guide to Collaborative Filtering
Downsides of a few Collaborative Filtering techniques
There are two common ways to perform collaborative filtering, but both have downsides:
- User-User Filtering: This finds users who are similar to you. The problem is that the number of users in a system can grow to millions, making it computationally very slow to compare everyone. Also, people’s tastes change over time, which can confuse the system or require very frequent retrainings for the system.
- Item-Item Filtering: This finds movies based on the item to item similarity. While this is more stable than user-user filtering, it still struggles with sparsity. This happens because most users only rate a fraction of the thousands of movies available.
Singular Value Decomposition (SVD)
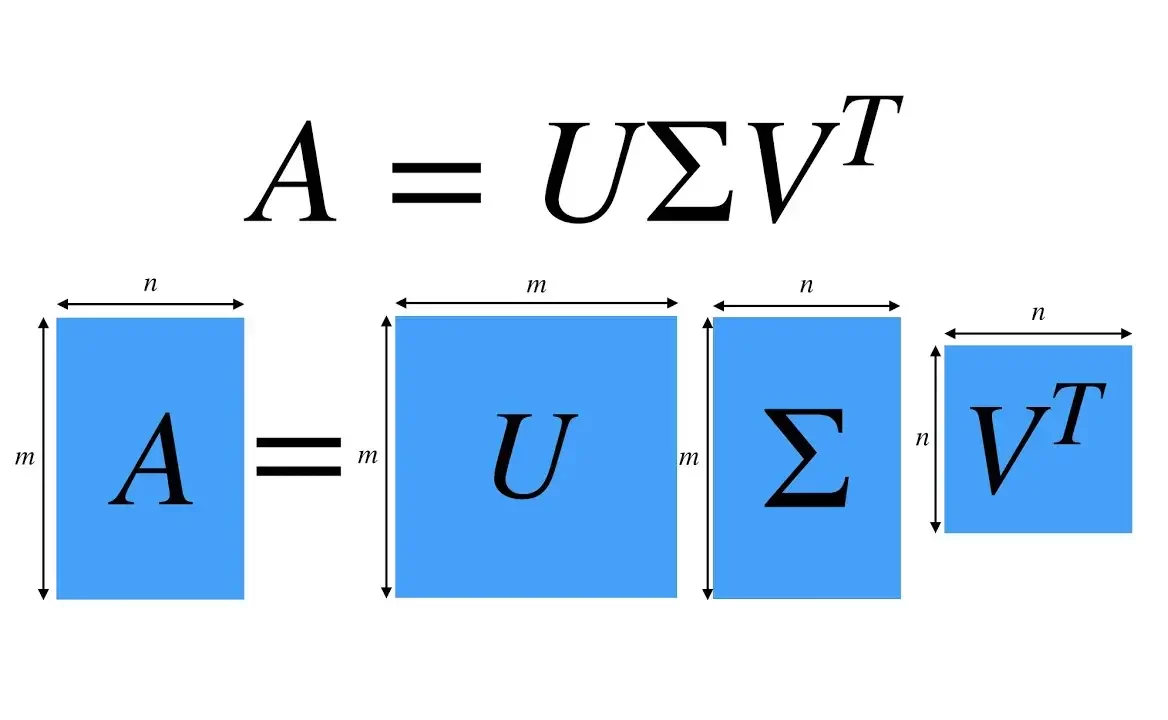
The intuition here is to use matrix factorization using Singular Value Decomposition (SVD) to decompose a sparse matrix into lower dimension later factor matrices. This is a user-item collaborative filtering technique and this is the collaborative filtering technique we’ll pick for our recommendation system.
Movie Recommendation System
Let’s understand the data and build our recommendation system with the earlier discussed SVD Collaborative Filtering technique.
Note: Due to the size of the code only the important parts of the code have been explained, you can refer to the complete notebook here: (https://www.kaggle.com/code/mounishv/movie-recommender)
Understanding the Dataset
For this project, we are using The Movies Dataset (https://www.kaggle.com/datasets/rounakbanik/the-movies-dataset), which is a collection of metadata for over 45,000 films. While the full dataset is massive, we specifically use the ratings_small.csv file. This smaller version contains about 100,000 ratings from 700 users on 9,000 movies. We use the small version because it allows us to train models quickly.
Pre-requisites
We will use:
- Surprise Library: A specialized toolkit for building recommendation models.
- OpenAI API: Used to make our recommender system smart. (https://platform.openai.com/settings/organization/api-keys)
The Surprise Library for Data Splitting & SVD
The Surprise library is specifically built for recommendations. It simplifies the process of loading data and testing different algorithms. Before training, we split our data into a training set and a test set using surprise and also use the inbuilt implementation for SVD.
Python Code
The provided code follows a professional workflow for building and refining a model.
Requirements
!pip install "numpy<2"
!pip install -q openaiNote: Restart your Colab session before you proceed
1. Data Preparation
The code first merges movie IDs from different files to ensure the ratings and movie titles match up correctly.
import pandas as pd
from surprise import Dataset, Reader, SVD
from surprise.model_selection import GridSearchCV, train_test_split
from surprise import accuracy
# Kaggle path for The Movies Dataset
path = '/kaggle/input/the-movies-dataset/'
# Loading relevant files
ratings = pd.read_csv(path + 'ratings_small.csv')
metadata = pd.read_csv(path + 'movies_metadata.csv', low_memory=False)
links = pd.read_csv(path + 'links_small.csv')
ratings['movieId'] = pd.to_numeric(ratings['movieId'], errors='coerce').astype('Int32')
ratings = ratings.merge(links[['movieId', 'tmdbId']], on='movieId', how='left')2. Splitting the data and Finding the Best Model
# Initialize the Reader for Surprise (ratings are 1-5)
reader = Reader(rating_scale=(0.5, 5.0))
# Load the dataframe into Surprise format
data = Dataset.load_from_df(
ratings[['userId', 'movieId', 'rating']],
reader
)
# Split into 75% training and 25% testing
trainset, testset = train_test_split(data, test_size=0.25, random_state=42)Instead of guessing the best settings, the code uses GridSearchCV. This automatically tests different versions of the SVD to find the one with the lowest RMSE.
# Define the parameter grid
param_grid = {
'n_factors': [10, 20, 50],
'n_epochs': [10, 20],
'lr_all': [0.005, 0.01], # learning rate
'reg_all': [0.02, 0.1] # regularization
}
# Run Grid Search with 3-fold cross-validation
gs = GridSearchCV(SVD, param_grid, measures=['rmse'], cv=3, n_jobs=-1)
gs.fit(data)
# Best RMSE score
print(f"Best RMSE score found: {gs.best_score['rmse']}")
# Combination of parameters that gave the best RMSE score
print(f"Best parameters: {gs.best_params['rmse']}")Best RMSE score found: 0.8902760026938319
Best parameters: {'n_factors': 50, 'n_epochs': 20, 'lr_all': 0.01, 'reg_all': 0.1}
3. The Smart Twist
The most unique part of this code is how it uses an LLM to help the user. Once the SVD model predicts the top 5 movies for a user, an LLM (GPT-4.1 mini) asks a question to help the user pick just one.
import numpy as np
from openai import OpenAI
from collections import defaultdict
from sklearn.metrics.pairwise import cosine_similarity
client = OpenAI(api_key=OPENAI_API_KEY)We’ll define two functions to implement our idea. One function get_top_5_for_user will retrieve 5 recommendations for the user and the other smart_recommendation will perform the following tasks:
- Uses metadata to get more context on the 5 movies
- Passes them to an LLM to phrase a question to the user
- The answer from the user will be used to give his final recommendation using cosine similarity.
Question-Creation logic
movie_list_str = "\n".join([f"- {m['title']}: {m['desc']}" for m in movie_info])
prompt = f"I have selected these 5 movies for a user based on their history:\n{movie_list_str}\n\n" \
"Frame one short, engaging question to help the user choose between these specific options."
question = client.chat.completions.create(
model="gpt-4.1-mini",
messages=[{"role": "user", "content": prompt}]
).choices[0].message.contentSemantic matching logic (using cosine similarity)
resp_vec = client.embeddings.create(
input=[user_response],
model="text-embedding-3-small"
).data[0].embedding
movie_texts = [f"{m['title']} {m['desc']}" for m in movie_info]
movie_vecs = [e.embedding for e in client.embeddings.create(
input=movie_texts,
model="text-embedding-3-small"
).data]
scores = cosine_similarity([resp_vec], movie_vecs)[0]
winner_idx = np.argmax(scores)4. Running the system
Predicting User Rating:
# Pick a random user and movie from the test set
uid = testset[0][0]
iid = testset[0][1]
true_r = testset[0][2]
pred = final_model.predict(uid, iid)
print(f"\nUser: {uid}")
print(f"Movie: {iid}")
print(f"Actual Rating: {true_r}")
print(f"Predicted Rating: {pred.est:.2f}")User: 30
Movie: 2856
Actual Rating: 4.0
Predicted Rating: 3.72
Smart Recommender
top_5 = get_top_5_for_user(predictions, target_uid=testset[0][0])
final_movie, score = llm_recommendation(top_5, metadata, links)
print(f"\nFinal Recommendation: {final_movie['title']} (Match Score: {score:.2f})")Agent: Are you in the mood for a gripping drama, a thrilling action-packed story, a classic comedy adventure, or an enchanting animated fantasy?
Your answer: animated movie
Final Recommendation: How to Train Your Dragon (Match Score: 0.32)
As you can see, when I said animated movie, the system recommended “How To Train Your Dragon” based on my current mood. Making use of the cosine similarity between my answer and the movie descriptions to pick the final recommendation.
Conclusion
We have successfully built our smart recommendation system. By using SVD using the Surprise library we have mitigated the issues with other collaborative filtering techniques. Adding an LLM to the mix makes the system better and also mood-based rather than having a static system, although the level of personalization could be even higher by including the user data as well in the question. Also it’s important to note that we have to frequently retrain a collaborative filtering model on the latest data to keep the recommendations relevant.
Frequently Asked Questions
Q1. What is the similarity used in User-User Collaborative Filtering?
A. It is Pearson correlation, it measures similarity between two users by comparing their rating patterns and checking how strongly their preferences move together.
Q2. What is cosine similarity?
A. Cosine similarity measures how similar two vectors are by calculating the angle between them, commonly used for text and embeddings.
Q3. What is association rule mining?
A. Association rule mining finds relationships between items in datasets, like products frequently bought together, using support, confidence, and lift metrics.
Passionate about technology and innovation, a graduate of Vellore Institute of Technology. Currently working as a Data Science Trainee, focusing on Data Science. Deeply interested in Deep Learning and Generative AI, eager to explore cutting-edge techniques to solve complex problems and create impactful solutions.






