Machine learning is behind many of the technologies that influence our lives today, ranging from recommendation systems to fraud detection. However, the capability to construct models that actually address our problems involves more than programming skills. Therefore, a successful machine learning development hinges on bridging technical work with practical need and ensuring that solutions generate measurable value. In this article, we will discuss principles for building ML models that create real-world impact. This includes setting clear objectives, having high-quality data, planning for deployment, and maintaining models for sustained impact.
Table of contents
Core Principles for Building Real-World ML Models
Now, from this section onwards, we’ll lay out the fundamental principles that determine whether or not ML models perform well in real-world scenarios. All major topics, including focus on data quality, selecting the perfect algorithm, deployment, post-deployment monitoring, fairness of the working model, collaboration, and continuous improvement, will be discussed here. By adhering to these principles, one can arrive at useful, trustworthy, and maintainable solutions.
Good Data Beats Fancy Algorithms
Even highly sophisticated algorithms require high-quality data. The saying goes: “garbage in, garbage out.” If you feed the model messy or biased data, you’ll receive messy or biased results. As the experts say, “good data will always outperform cool algorithms.” ML successes start with a strong data strategy, because “a machine learning model is only as good as the data it’s trained on.” Simply put, a clean and well-labeled dataset will more often outperform a sophisticated model built on flawed data.
In practice, this means cleaning and validating data before modeling. For example, the California housing dataset (via sklearn.datasets.fetch_california_housing) contains 20,640 samples and 8 features (median income, house age, etc.). We load it into a DataFrame and add the price target:
from sklearn.datasets import fetch_california_housing
import pandas as pd
import seaborn as sns
california = fetch_california_housing()
dataset = pd.DataFrame(california.data, columns=california.feature_names)
dataset['price'] = california.target
print(dataset.head())
sns.pairplot(dataset)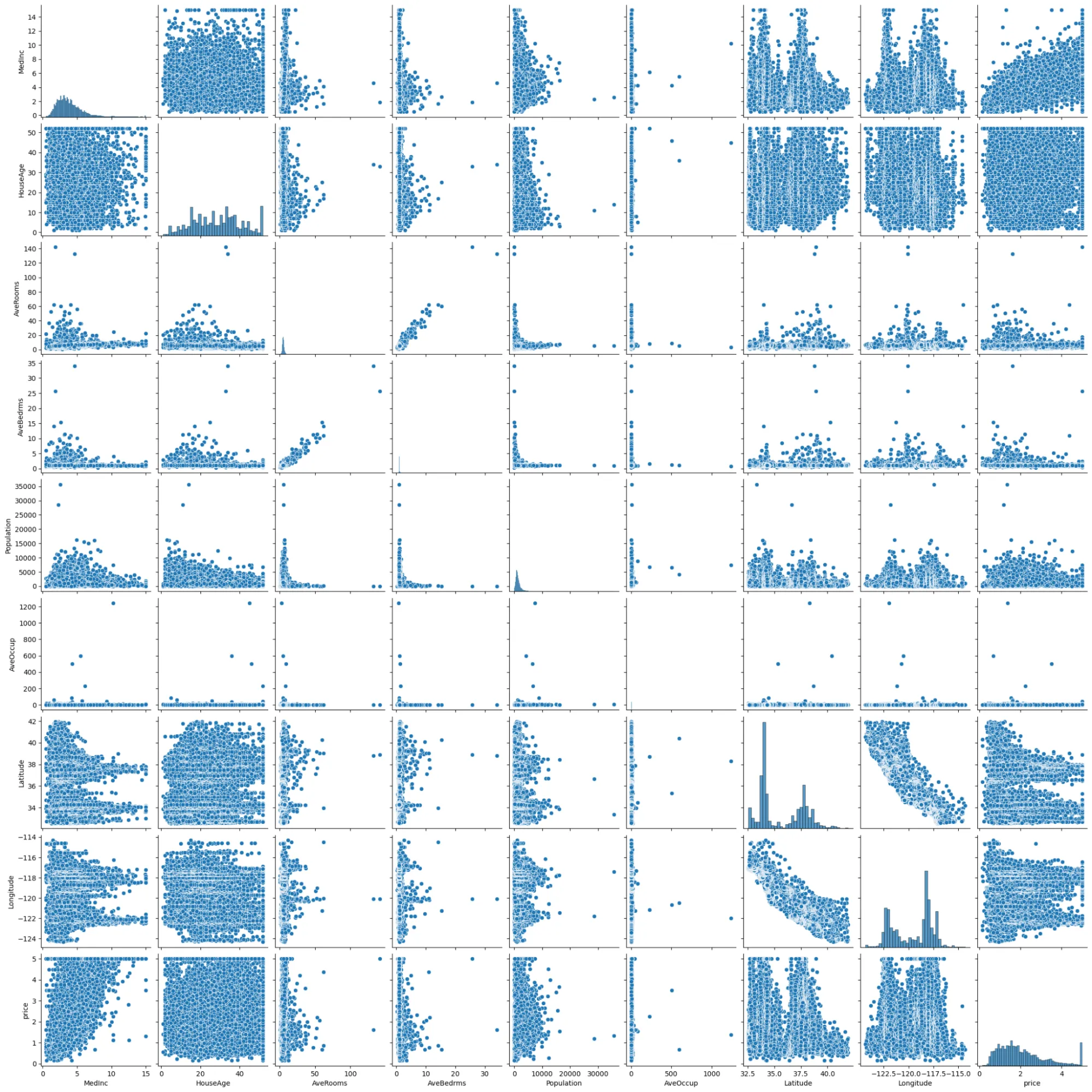
This gives the first rows of our data with all numeric features and the target price. We then inspect and clean it: for example, check for missing values or outliers with info and describe methods:
print(dataset.info())
print(dataset.isnull().sum())
print(dataset.describe())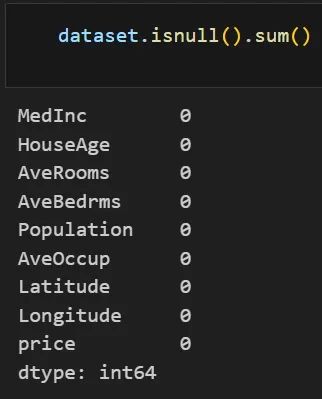
These summaries confirm no missing values and reveal the data ranges. For instance, describe() shows the population and income ranges.
sns.regplot(x="AveBedrms",y="price",data=dataset)
plt.xlabel("Avg. no. of Bed rooms")
plt.ylabel("House Price")
plt.show()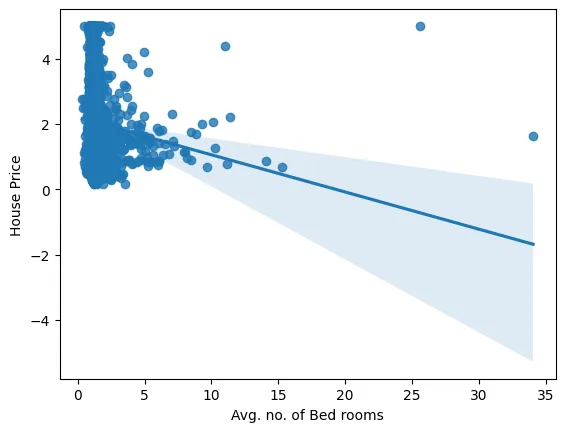
This plot shows the variation of the house price with the number of bedrooms.
In practical terms, this means:
- Identify and correct any missing values, outliers, and measurement errors before modeling.
- Clean and label the data properly and double-check everything so that bias or noise does not creep in.
- Bring in data from other sources or go for synthetic examples to cover those rare cases.
Focus on the Problem First, Not the Model
The most common mistake in machine learning projects is focusing on a particular technique before understanding what you’re trying to solve. Therefore, before embarking on modeling, it’s crucial to gain a comprehensive understanding of the business environment and user requirements. This involves involving stakeholders from the beginning, fosters alignment, and ensures shared expectations.
In practical terms, this means:
- Identify business decisions and outcomes that will provide direction for the project, e.g,. loan approval, pricing strategy.
- Measure success through quantifiable business metrics instead of technical indicators.
- Collect domain knowledge and set KPIs like revenue gain or error tolerance accordingly.
- Sketching the workflow, here, our ML pipeline feeds into a web app used by real estate analysts, so we ensured our input/output schema matches that app.
In code terms, it translates to selecting the feature set and evaluation criteria before working on the algorithm. For instance, we might decide to exclude less important features or to prioritize minimizing overestimation errors.
Measure What Really Matters
The success of your models should be evaluated on the reality of their business outcomes, not their technical scorecard. Recall, precision, or RMSE might not mean much if it does not lead to improved revenue, efficiency, or improve the satisfaction amongst your users. Therefore, always set model success against KPI’s that the stakeholders value.
For example, if we have a threshold-based decision (buy vs. skip a house), we could simulate the model’s accuracy on that decision task. In code, we compute standard regression metrics but interpret them in context:
from sklearn.metrics import mean_squared_error, r2_score
pred = model.predict(X_test)
print("Test RMSE:", np.sqrt(mean_squared_error(y_test, pred)))
print("Test R^2:", r2_score(y_test, pred))In practical terms, this means:
- Define metrics against actual business results such as revenue, savings, or engagement.
- Don’t just rely on technical measures such as precision or RMSE.
- Articulate your results in business vernacular that stakeholders understand.
- Provide actual value using measures like ROI, conversion rates, or lift charts.
Start Simple, Add Complexity Later
Many machine learning projects fail due to overcomplicating models too early in the process. Establishing a simple baseline gives perspective, reduces overfitting, and simplifies debugging.
So, we begin modeling with a simple baseline (e.g., linear regression) and only add complexity when it clearly helps. This avoids overfitting and keeps development agile. In our notebook, after scaling features, we first fit a plain linear regression:
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X_train, y_train)
reg_pred = model.predict(X_test)
print("Linear model R^2:", r2_score(y_test, reg_pred))
# 0.5957702326061665
LinearRegression i ?
LinearRegression()This establishes a performance benchmark. If this simple model meets requirements, no need to complicate matters. In our case, we then tried adding polynomial features to see if it reduces error:
from sklearn.preprocessing import PolynomialFeatures
train_rmse_errors=[]
test_rmse_errors=[]
train_r2_score=[]
test_r2_score=[]
for d in range(2,3):
polynomial_converter = PolynomialFeatures(degree=d,include_bias=False)
poly_features = polynomial_converter.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(poly_features, y,test_size=0.3, random_state=42)
model = LinearRegression(fit_intercept=True)
model.fit(X_train,y_train)
train_pred = model.predict(X_train)
test_pred = model.predict(X_test)
train_RMSE = np.sqrt(mean_squared_error(y_train,train_pred))
test_RMSE = np.sqrt(mean_squared_error(y_test,test_pred))
train_r2= r2_score(y_train,train_pred)
test_r2 = r2_score(y_test,test_pred)
train_rmse_errors.append(train_RMSE)
test_rmse_errors.append(test_RMSE)
train_r2_score.append(train_r2)
test_r2_score.append(test_r2)
# highest test r^2 score:
highest_r2_score=max(test_r2_score)
highest_r2_score
# 0.6533650019044048In our case, the polynomial regression outperformed the Linear regression, therefore we’ll use it for making the test predictions. So, before that, we’ll save the model.
with open('scaling.pkl', 'wb') as f:
pickle.dump(scaler, f)
with open('polynomial_converter.pkl', 'wb') as f:
pickle.dump(polynomial_converter, f)
print("Scaler and polynomial features converter saved successfully!")
# Scaler and polynomial features converter saved successfully!In practical terms, this means:
- Start with baseline models (like linear regression or tree-based models).
- Baselines provide a measure of improvement for complex models.
- Add complexity to models only when measurable changes are returned.
- Incrementally design models to ensure debugging is always straightforward.
Plan for Deployment from the Start
Successful machine learning projects are not just in terms of building models and saving the best weight files, but also in getting them into production. You need to be thinking about important constraints from the beginning, including latency, scalability, and security. Having a deployment strategy from the beginning simplifies the deployment process and improves planning for integration and testing.
So we design with deployment in mind. In our project, we knew from Day 1 that the model would power a web app (a Flask service). We therefore:
- Ensured the data preprocessing is serializable (we saved our StandardScaler and PolynomialFeatures objects with pickle).
- Choose model formats compatible with our infrastructure (we saved the trained regression via pickle, too).
- Keep latency in mind: we used a lightweight linear model rather than a large ensemble to meet real-time needs.
import pickle
from flask import Flask, request, jsonify
app = Flask(__name__)
model = pickle.load(open("poly_regmodel.pkl", "rb"))
scaler = pickle.load(open("scaling.pkl", "rb"))
poly_converter = pickle.load(open("polynomial_converter.pkl", "rb"))
@app.route('/predict_api', methods=['POST'])
def predict_api():
data = request.json['data']
inp = np.array(list(data.values())).reshape(1, -1)
scaled = scaler.transform(inp)
features = poly_converter.transform(scaled)
output = model.predict(features)
return jsonify(output[0])This snippet shows a production-ready prediction pipeline. It loads the preprocessing and model, accepts JSON input, and returns a price prediction. By thinking about APIs, version control, and reproducibility from the start. So, we can avoid the last-minute integration headaches.
In practical terms, this means:
- Clearly identify at the start what deployment needs you have in terms of scalability, latency, and resource limits.
- Incorporate version control, automated testing, and containerization in your model development workflow.
- Consider how and when to move data and information around, your integration points, and how errors will be handled as much as possible at the start.
- Work with engineering or DevOps teams from the start.
Keep an Eye on Models After Launch
Deployment is not the end of the line; models can drift or degrade over time as data and environments change. Ongoing monitoring is a key component of model reliability and impact. You should watch for drift, anomalies, or drops in accuracy, and you should try to tie model performance to business outcomes. Making sure you regularly retrain models and log properly is very important to ensure that models will continue to be accurate, compliant, and relevant to the real world, throughout time.
We also plan automatic retraining triggers: e.g., if the distribution of inputs or model error changes significantly, the system flags for re-training. While we did not implement a full monitoring stack here, we note that this principle means establishing ongoing evaluation. For instance:
# (Pseudo-code for monitoring loop)
new_data = load_recent_data()
preds = model.predict(poly_converter.transform(scaler.transform(new_data[features])))
error = np.sqrt(mean_squared_error(new_data['price'], preds))
if error > threshold:
alert_team()In practical terms, this means:
- Use dashboards to monitor input data distributions and output metrics.
- Consider monitoring technical accuracy measures parallel with business KPIs.
- Configure alerts to do initial monitoring, detect anomalies, or data drift.
- Retrain and update models regularly to ensure you are maintaining performance.
Keep Improving and Updating
Machine learning is never finished, i.e, the data, tools, and business needs change constantly. Therefore, ongoing learning and iteration are fundamentally processes that enable our models to remain accurate and relevant. Iterative updates, error analysis, exploratory learning of new algorithms, and expanding skill sets give teams a better chance of maintaining peak performance.
In practical terms, this means:
- Schedule regular retraining with incremental data.
- Collect feedback and analysis of errors to improve models.
- Experiment with newer algorithms, tools, or features that increase value.
- Invest in progressive training to strengthen your team’s ML knowledge.
Build Fair and Explainable Models
Fairness and transparency are essential when models can influence people’s daily lives or work. Data and algorithmic bias can lead to detrimental effects, whereas black-box models that fail to provide explainability can lose the trust of users. By working to ensure organizations are fair and present explainability, organizations are building trust, meeting ethical obligations, and providing transparent rationales about model predictions. Especially when it comes to sensitive topics like healthcare, employment, and finance.
In practical terms, this means:
- Investigate the performance of your model across groups (e.g., by gender, ethnicity, etc.) to identify any disparities.
- Be intentional about incorporating fairness techniques, such as re-weighting or adversarial debiasing.
- Use explainability tools (e.g., SHAP, LIME, etc.) to be able to explain predictions.
- Establish diverse teams and make your models transparent with your audiences.
Note: For the complete version of the code, you can visit this GitHub repository.
Conclusion
An effective ML system builds clarity, simplicity, collaboration, and ongoing flexibility. One should start with goals that are clear, work with good quality data, and think about deployment as early as possible. Ongoing retraining and diverse stakeholder views and perspectives will only improve your outcomes. Together with accountability and clear processes, organizations can implement machine learning solutions that are sufficient, trustworthy, transparent, and responsive over time.
Frequently Asked Questions
Q1. Why is data quality more important than using advanced algorithms?
A. Because poor data leads to poor results. Clean, unbiased, and well-labeled datasets consistently outperform fancy models trained on flawed data.
Q2. How should ML project success be measured?
A. By business outcomes like revenue, savings, or user satisfaction, not just technical metrics such as RMSE or precision.
Q3. Why start with simple models first?
A. Simple models give you a baseline, are easier to debug, and often meet requirements without overcomplicating the solution.
Q4. What should be planned before model deployment?
A. Consider scalability, latency, security, version control, and integration from the start to avoid last-minute production issues.
Q5. Why is monitoring after deployment necessary?
A. Because data changes over time. Monitoring helps detect drift, maintain accuracy, and ensure the model stays relevant and reliable.
Hello! I'm Vipin, a passionate data science and machine learning enthusiast with a strong foundation in data analysis, machine learning algorithms, and programming. I have hands-on experience in building models, managing messy data, and solving real-world problems. My goal is to apply data-driven insights to create practical solutions that drive results. I'm eager to contribute my skills in a collaborative environment while continuing to learn and grow in the fields of Data Science, Machine Learning, and NLP.






