This article was published as a part of the Data Science Blogathon.
Introduction
In this digital world, spam is the most troublesome challenge that everyone is facing. Sending spam messages to people causes various problems that may, in turn, cause economic losses.
By spamming messages, we lose memory space, computing power, and speed. To remove these spam messages, we need to spend our time. Many methods have been developed to filter spam with varying levels of success.
In this article, we will discuss Naïve Bayes Classifier and Support Vector Classifier and implement these machine learning models to filter spam text messages and compare the results.
Outline of this article
- Naïve Bayes Classifier
- Support Vector Machine (SVM)
- Dataset Download
- Data Pre-processing and Model Building
- Results
1.Naïve Bayes Classifier:
Naïve Bayes is a supervised machine learning algorithm used for classification problems. It is built on Bayes Theorem. It is called Naïve because of its Naïve assumption of Conditional Independence among predictors.
It assumes that all the features in a class are unrelated to each other.
To explain the Naïve Bayes Algorithm, first, we will see Bayes Theorem.
Bayes Theorem:
Let’s take two events A and B. We use the below formula to calculate posterior probability P(B/A) using P(B), P(A), P(A/B).
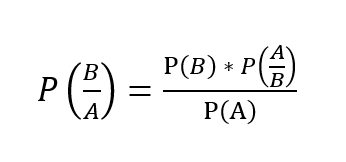
Where P(B/A) is the posterior probability,
P(B) is the prior probability,
It is easy to calculate the posterior probability when we have a single feature. But when we have two or more features, it is difficult to calculate the posterior probability as sometimes, we can get a zero probability problem.
So, we take the Naïve assumption of conditional
independence to calculate posterior probability.
When we have,
Predictors: [ X1, X2 ] and
Target: Y
The formula to calculate the posterior probability is-
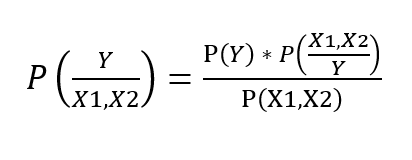
Taking Conditional Independence for P(X1, X2/Y=1),
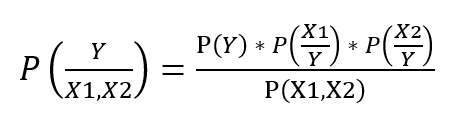
This is the formula to calculate the posterior probability using Naïve Bayes Classifier.
2. Support Vector Machine (SVM)
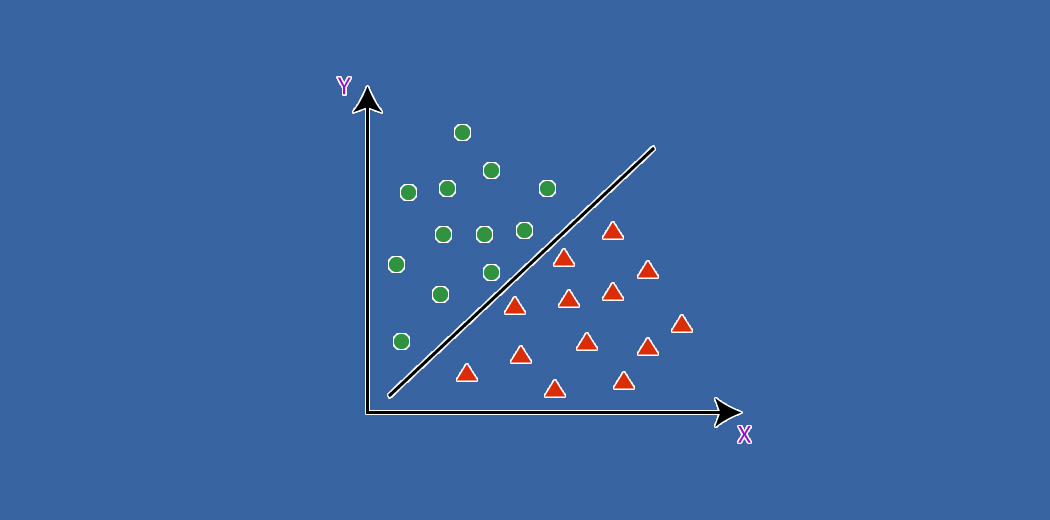
It is a supervised machine learning algorithm by which we can perform Regression and Classification.
In SVM, data points are plotted in n-dimensional space where n is the number of features. Then the classification is done by selecting a suitable hyper-plane that differentiates two classes.
In n-dimensional space, hyper-plane has (n-1) dimensions.
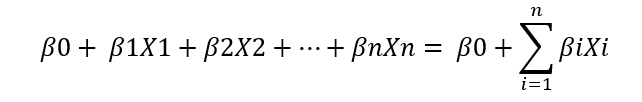
We have an assumption that classes are linearly separable.
The sign of the equation helps to classify classes and the magnitude of the equation helps to understand how far is the observation away from the hyper-plane. When the magnitude is high, we are more certain about the class assignment.
The minimum distance of data points from hyper-plane to either class is called Margin. We need to have a maximum margin so that it will have a high magnitude. So, this hyper-plane is called Maximum Margin Classifier.
Support vectors are the observations that lie on the margin or violate the margin affecting the hyper-plane. Support vectors support
the hyper-plane.
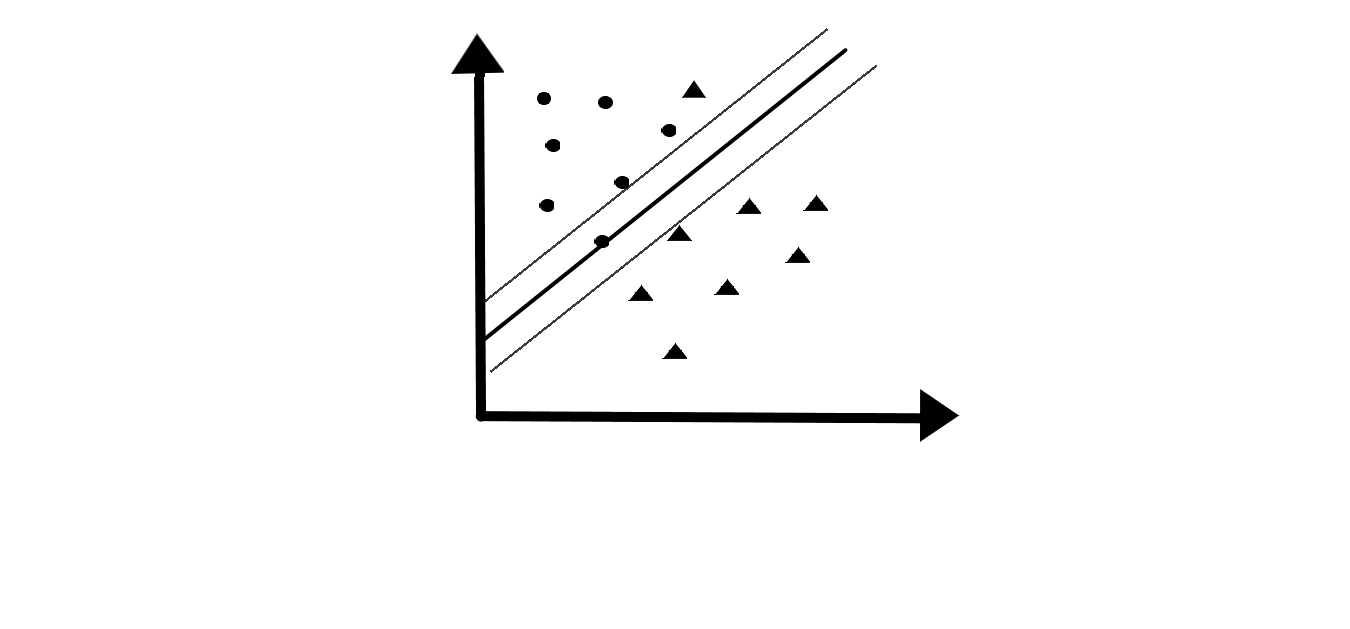
In Support Vector Classifier, we have a maximum margin classifier with a soft margin (this margin can be violated by some observations).
3. Downloading the Dataset
SMS Spam Collection data set is taken from the UCI Machine Learning Repository. This data set is a public set of SMS labeled messages that were collected for mobile phone spam research in 2012. It consists of 5572 messages of which 4825 are ham messages and 747 spam messages. In this data set, every line starts with the label of the message, followed by the text.
Dataset link: https://archive.ics.uci.edu/ml/datasets/SMS+Spam+Collection
4. Data Pre-processing & Models used
The Dataset has two columns:
- Label class of data (ham or spam) and
- Text message
Other unwanted columns are removed.
Python Code:
# Importing packages:
import pandas as pd
import numpy as np
# Reading the dataset:
sms_data = pd.read_csv("spam", encoding='latin-1', sep='\t')
print(sms_data.head())We drop the last four columns as the last three columns don’t have any values and we don’t need a length column.
sms_data.drop(labels = ['Unnamed: 2','Unnamed: 3','Unnamed: 4','length'],axis = 1,inplace = True) sms_data.head()

Now we’ll create a corpus and append messages, before appending messages to the corpus, we need to follow certain pre-processing steps.
We import ‘re’ package and remove punctuation, special characters and convert all characters to lower case.
Now, we need to split a message into words to remove stop-words and to perform stemming.
We import English stop-words from the NLTK package and removed them if found in the sentence.
While removing stop-words, we perform stemming that is if the word is not a stop-word, it will be converted to its root form. This is called stemming.
Then we are joining the words in the list again to form a message without any stop-words and all words will be present in its
root form. Then we append messages to the corpus.
# Importing packages:
import re import nltk from nltk.corpus import stopwords from nltk.stem.porter import PorterStemmer
# Creating a corpus of refined messages:
stemming = PorterStemmer()
corpus = []
for i in range (0,len(sms_data)):
s1 = re.sub('[^a-zA-Z]',repl = ' ',string = sms_data['v2'][i])
s1.lower()
s1 = s1.split()
s1 = [stemming.stem(word) for word in s1 if word not in set(stopwords.words('english'))]
s1 = ' '.join(s1)
corpus.append(s1)
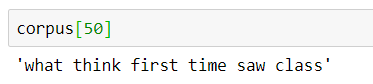
corpus[50]
We’ll import Count-Vectorizer from Scikit-learn library to tokenize and vectorize the text.
# Importing package:
from sklearn.feature_extraction.text import CountVectorizer countvectorizer =CountVectorizer()
By using this Count-Vectorizer we’ll tokenize a collection of text documents and built a vocabulary, this vocabulary is also used to encode new documents.
To use this Count-Vectorizer, first, we’ll create an instance of Count-Vectorizer class.
Then fit () function is used to learn vocabulary from the document and the transform() function is used to encode as a vector.
x = countvectorizer.fit_transform(corpus).toarray()
This vector represents the length of the entire vocabulary and the count for the number of times each word appeared in the document.
Now we have a numeric vector that has been converted from a string of text.
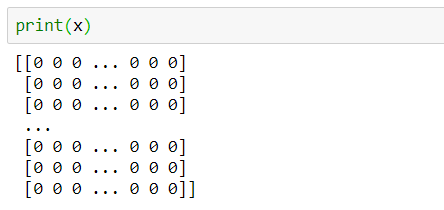
print(x)
y = sms_data['v1'].values print(y)

Train – Test Split
We’ll divide data into train and test randomly using a train-test split in the ratio of 70:30.
# Splitting train and test data:
from sklearn.model_selection import train_test_split x_train,x_test,y_train,y_test = train_test_split(x,y,test_size = 0.3, stratify=y,random_state=100)
Models:
1. Multinomial Naïve Bayes.
# Importing package and fitting model:
from sklearn.naive_bayes import MultinomialNB multinomialnb = MultinomialNB() multinomialnb.fit(x_train,y_train)

# Predicting on test data:
y_pred = multinomialnb.predict(x_test)

2. SVM
#Importing package and fitting model:
from sklearn.svm import LinearSVC linearsvc = LinearSVC() linearsvc.fit(x_train,y_train)

# Predicting on test data:
y_pred = linearsvc.predict(x_test)

5. Results of our Models
# Importing packages:
from sklearn.metrics import classification_report, confusion_matrix from sklearn.metrics import accuracy_score print(classification_report(y_test,y_pred)) accuracy_score(y_test,y_pred)
1. Multinomial Naïve Bayes.
.PNG)
Accuracy in %: 98.026
2. SVM.
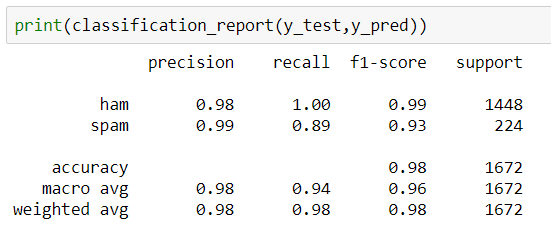
Accuracy in %: 98.325
By seeing the above results, we can say that the Naïve Bayes model and SVM are performing well on classifying spam messages with 98% accuracy but comparing the two models, SVM is performing better. These models can efficiently predict if the message is spam or not.






