This article was published as a part of the Data Science Blogathon.
Introduction
MongoDB is a free open-source No-SQL document database. It is widely used in the development of web applications and also in the implementations of Big Data solutions. As per the DB-engines report, It is highly ranked compared to the other document DBs like CouchDB, Realm, etc. It is a schema-free database and allows embedded documents that represent complex relationships in a single record.Let’s say that I have a problem statement as below
“I have a huge amount of hierarchial data which I want to Aggregate.”
MongoDB provides an Aggregation Framework that can be used to aggregate a huge amount of hierarchical data. It supports a lot of inbuilt functions and also different types of indexing that improve the performance of queries. In this tutorial, you will learn how to perform an Aggregation Pipeline in MongoDB. An Aggregation Pipeline is one of the basic aggregation frameworks provided by MongoDB. The Aggregation Pipeline processes the input documents in several stages in a serial order. Each result produced in one stage is passed on to the next stage where further processing can be done on this subset of documents to achieve the final aggregated result. All the examples are implemented using MongoDB Version 4.4.5.
Let’s dive in.
Prerequisites
To perform this tutorial, MongoDB should be installed in the system.
Setting up the connection
First, we need to open a connection to the DB using the command ‘mongo‘.When you see ‘>’ in the prompt then you are ready to execute commands related to the database operations used in this post.
Creating Database
Let us create a database ‘testdb’ first using the “use” command.
As you can see above, if the database exists then the above command will use that database else it will create a new database.
Now let us create a collection named ‘products’ inside this database using the command ‘createcollection’

Now insert test documents inside the collection with the help of the command ‘InsertMany‘
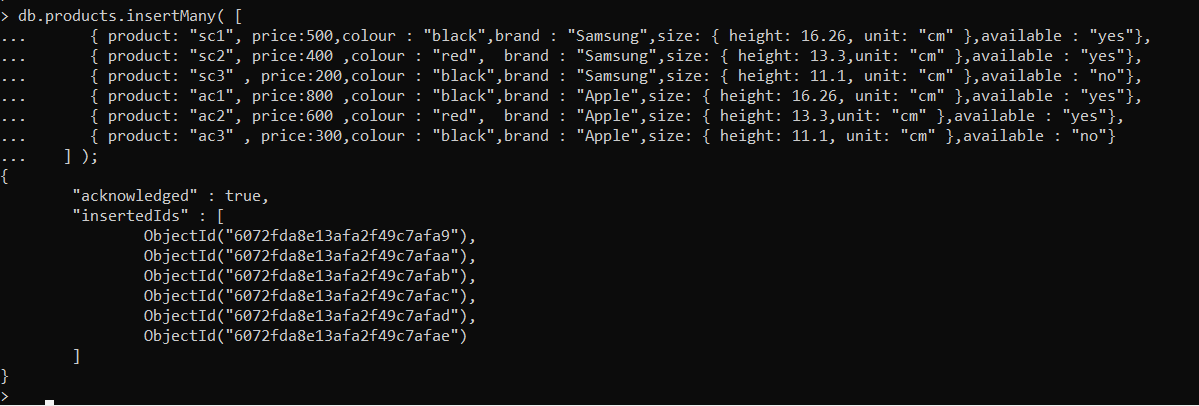
The documents got inserted successfully. You can also check the documents in the collection with the command “find”.

Creation of Aggregation Pipeline
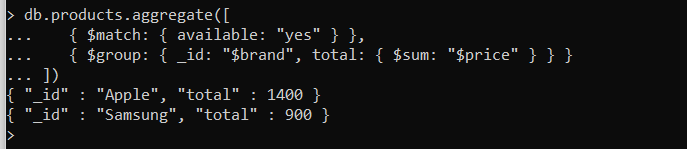
In the above collection, Let’s say we need to find out the total amount of sales that happened for each of the brands
Apple and Samsung for the available phone. So first we need to filter out the documents based on the available = “True”.This is done using the command “Match” and also the first stage of the Aggregation Pipeline. Then we need to find the sum of “price” which is the second stage as shown below. In the second stage, the grouping is done based on the brand and then the total sum of the price is calculated using the command “Group”
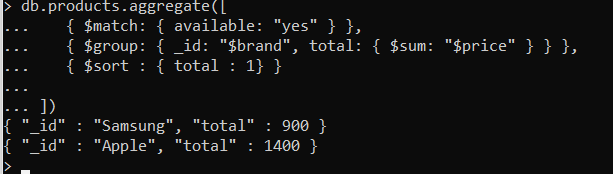
Let us add one more stage to this output called sort to display the sum based on higher price to lower price as below. The command we use here is “Sort”.Here in the sort, 1 means ascending order, and -1 means descending order.
Conclusion
In this article, we have seen how to build an aggregation pipeline using MongoDB.I hope this is useful and if you have any feedback please feel free to comment down in the below section.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.
About the Author
I am Deepti Jakka, I like writing blogs about technical topics. Get to know about me at https://learnfundas.com/






