If you are familiar with Change Data Capture AKA Change Data Tracking, you can just skip the introduction below and get straight to the implementation section. But, in case you’re not, let me introduce the concept first.
American Writer Mark Twain once said: “Data is like garbage”. Today some people say: data is the new oil. But I would say: data is a blooming flower.
Like a flower, data goes through different stages, and takes time to develop, or burst into bloom. Just as the time taken may differ from flower to flower, so different data sets develop at different rates. A single flower is less striking, but when it is part of a bouquet, it becomes really eye-catching. And so it is with data — that’s how companies like Google or Facebook are able to make a profit, even without charging for their services -they simply collect data ‘flowers’ and turn them into data ‘bouquets’.
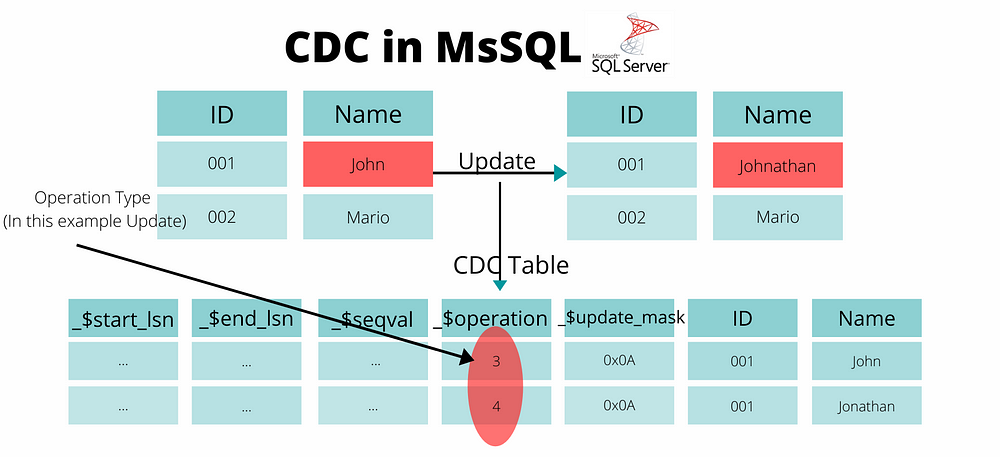
However, this article is not about flowers 😊 so, let’s move right on to our topic. As I explained previously, the state of data is continuously changing over time. Change Data Capture (CDC) is a set of technologies that enable you to identify and capture the previous states of the data so that later, you have a snapshot of past data that you can refer to when taking necessary action. See the example below:
Illustration
With the increasing demand for big-data technologies, Microsoft introduced CDC with MsSQL Server 2008. Today, CDC is available in almost all popular database servers, including MsSQL, Oracle, CockroachDB, MongoDB, etc. But, manual implementation is just one way to get the job done. We can also automate the CDC using triggers and short procedures. In this article, I will discuss how to implement CDC both ways.
Why Change Data Capture is important
Yes, you guessed right, this technology is mostly used in the big-data domain to keep timely snapshots of streaming data in data warehouses. Here, we go through a process called ELT/ETL to insert our data into the data warehouse. This process is efficient with historic data, but when it comes to real-time data it causes too much latency to run complex queries. The easiest way to deal with real-time data is CDC, which enables us to keep our data warehouse up to date and make business decisions faster.
Let’s Get our Hands Dirty with Some Practical Examples
1. Implementing CDC with MsSQL
First, we need to create a new database.
CREATE DATABASE cdcDB
Next, I select the created database from the available databases dropdown, and create a few simple tables – just to demonstrate CDC implementation.
CREATE TABLE Student
(
StudentID int NOT NULL PRIMARY KEY,
FirstName varchar(255) NOT NULL,
LastName varchar(255) NOT NULL,
Age int,
ContactNo char(10) NOT NULL
)
After creating tables, I enable CDC.
EXEC sys.sp_cdc_enable_db
After CDC is enabled for the database, I then enable it on each table.
EXEC sys.sp_cdc_enable_table
@source_schema = 'dbo',
@source_name = 'Student',
@role_name = NULL,
@supports_net_changes = 1
Finally, I insert some values to my table by the following query.
INSERT INTO Student(StudentID,FirstName,LastName,Age,ContactNo)
To confirm whether CDC has been properly implemented, we can just check either at our hierarchy panel or Jobs tab, under the SQL Server Agent.
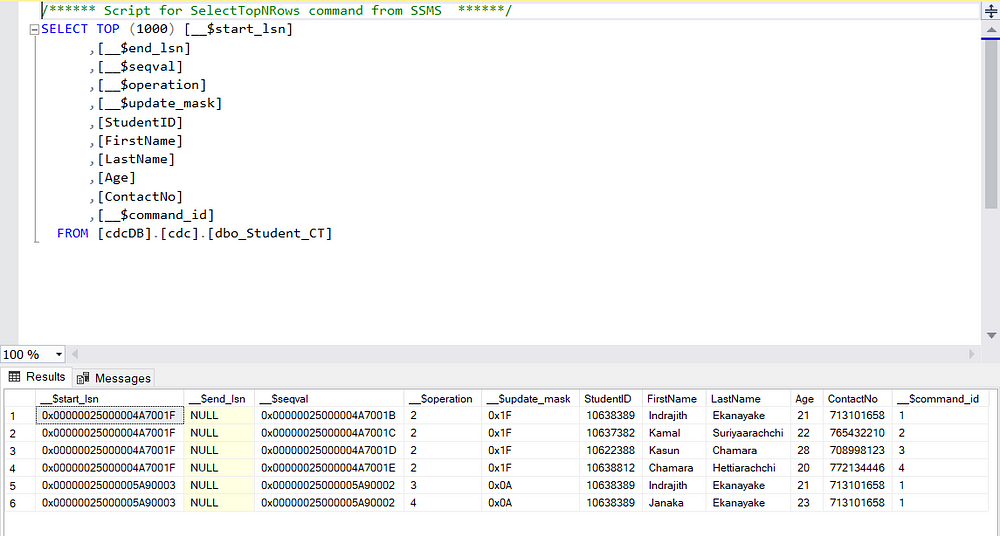
To understand how and what data we are storing in the CDC tables, we can just update a few rows.
UPDATE Student
SET FirstName = 'Janaka', Age= '23'
WHERE StudentID = 10638389;
So, we are now looking at the CDC CT(Change Table) and we can identify that there are additional records, as seen below.
CDC CT(Change Table)
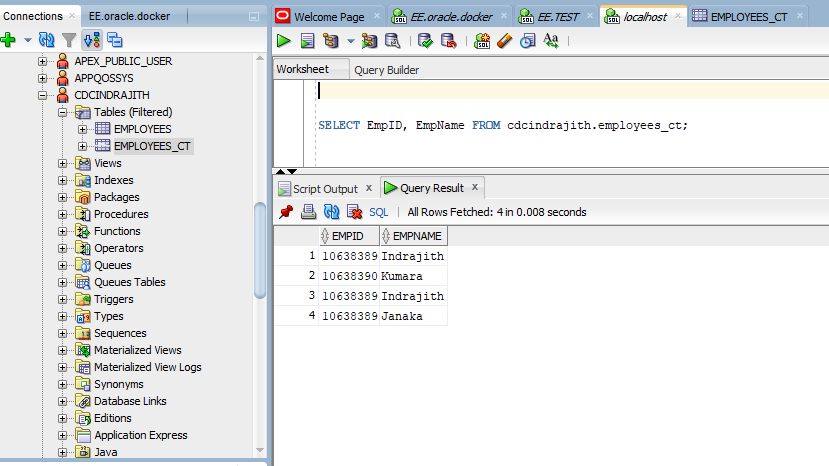
2. Implementing CDC with Oracle
First, I need to mention that I’m running Oracle 11g Enterprise Edition using docker image and I’m writing queries using Oracle SQL Developer’s latest version on the host machine. The server and Oracle SQL developer are connected via port: 1521.
To implement CDC, I begin by creating a tablespace called “ts_cdcindrajith” in my cdcAssignment folder, inside my F drive.
Finally, I insert some data into the salary table and then try to update and delete queries as well.
INSERT INTO Salary(SalDate,Task,PaidPerTask,EmpName)
VALUES
(2020-11-20, 4, 4000 , 'Indrajith'),
(2020-10-20, 11, 10000 , 'Kusum');
UPDATE Salary
SET EmpName = 'Janaka'
WHERE EmpName = 'Indrajith';
DELETE FROM Salary WHERE EmpName = 'Kusum';
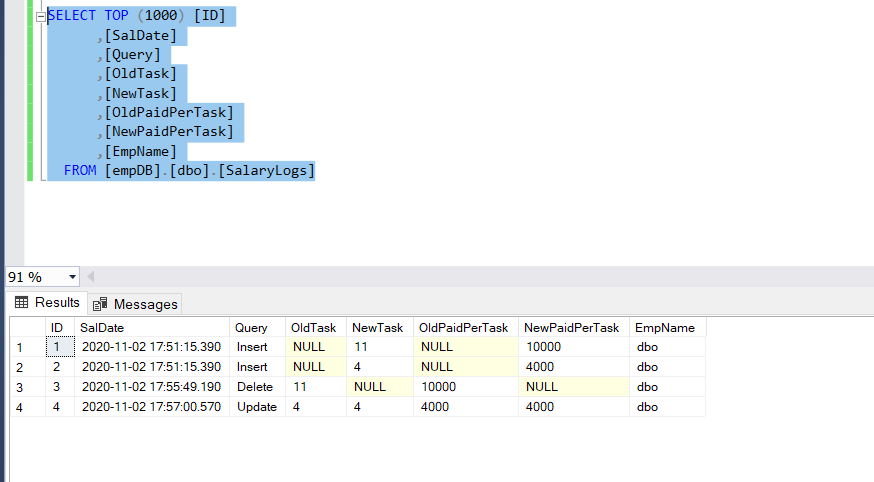
Towards the end, let’s check the salary logs table to understand whether the log files are updated or not.
SalaryLogs table
We see here that the log files are up to date.
Summary
In short, CDC identifies and captures data that has changed in tables of a source database as a result of CRUD operations. This is useful to people who need to export their data into a data warehouse or a business intelligence application. Changed data is maintained in CDC tables in the source database.
In this article, we briefly discussed what is Change Data Capture, why CDC is useful, and most importantly illustrated three methods for implementing CDC. I believe that the rapid evolution of big-data will have many more CDC implications in the future.
Thanks for reading!
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.