This article was published as a part of the Data Science Blogathon.
Introduction
Modern applications are popularly made using container orchestration systems and microservice architecture. In 2014, the first echoes of the word Kubernetes in tech were heard, and the conquest of Kubernetes is due in no small amount to its flexibility and authority. Back then, people were conflicting on “How do you even pronounce it?”
Fast forward eight years, and now it is the most potent container management tool that’s taking the world by storm. As an established open-source solution with a rich ecosystem, it has provided the backbone for many of the world’s most prominent online services.
However, not many people know about it when it gets to Kubernetes in production. Things can get a little more complex, and multiple topics need to be explained in detail.
The primary motivation behind this guide is to give a straightforward overview of the entire world of Kubernetes and help you start with the fundamentals of Kubernetes.
You will discover the importance, principal components, different architectures, challenges faced by users, and how to overcome them. You will learn to deploy your first application on a Kubernetes cluster, and towards the end of the guide, we will have a closer look at some of the key considerations and use cases of the Kubernetes.
So without any further pause, let’s get started. Have Fun!
Table Of Contents
- What Is Kubernetes?
- Why Is Kubernetes Important For Your Organization?
- Basic Kubernetes Concepts & Architecture
- A Detailed Difference Between Kubernetes And Docker
- Challenges For Kubernetes Users & Its Solutions
- Kubernetes Benefits For Companies
- How To Setup Docker and Kubernetes On Linux Systems
- Best Practices For Kubernetes In Production & Enhanced Cluster Productivity
- Examples Of Tech Giants That Are Using Kubernetes To Its Full Potential
- Final Thoughts
- About Author
- References

What Is Kubernetes?
Kubernetes (also known as k8s or “Kube”) is a powerful container management tool. It is a portable, extensible, and open-source orchestration platform that automates multiple manual processes and services to deploy, handle, and scale containerized clusters.
Kubernetes was initially invented and designed by engineers at Google and currently has a large, rapidly growing ecosystem. RedHat was one of the companies to work with Google on Kubernetes when Google was developing more than 2 billion containers deployments each week. Google donated the Kubernetes project to the newly developed Cloud Native Computing Foundation (CNCF) in 2015.
Why Is Kubernetes Important for your Organization?
Kubernetes, without a doubt, is a suitable solution for your company if you use it for the right task and in the appropriate context. It is the next big wave in cloud computing and the most famous platform to control and orchestrate solutions based on containers.
Suppose, if you are asked to manually run containers in production, in that case, you may end up with hundreds or thousands of containers over time, which is absolutely time-killing. It’s not enough to run containers. You also need to deploy, manage, connect, update, integrate, orchestrate, scale-up/down, and make them fault-tolerant.
This is where Kubernetes slips in. If you create a solution based on containers at a large scale, K8s is the tool of choice if you need it. You can quickly deploy, scale multiple instances of containers, operate various services, and scale them up and down with just little practice.
Basic Kubernetes Concepts & Architecture
When you’re just getting started with Kubernetes, it is good to know about the essential components and the functional architecture of Kubernetes beforehand. Kubernetes cluster follows a client-server architecture and is made up of a control plane (master), distributed storage system for maintaining the cluster state (etcd) consistent, and a bunch of cluster nodes (workers).
Kubernetes handles workloads by putting your pods into nodes. Depending on your settings, a node can define a virtual or physical machine. Each node will include the components essential to run pods. There are two separate categories within Kubernetes: Master and Worker nodes.
Let us see each category in detail below:
The Control Plane Or Master Node
It is a global decision-maker for the cluster made up of the Kube-API server, Kube scheduler, cloud-controller-manager, and Kube-controller-manager. It controls scheduling and overall cluster behaviour. Nodes that have these components running don’t have any user containers running. The Control plane is the cluster’s major component and is usually named master nodes.
1. Cloud-controller-manager (master)
The cloud controller manager runs in the master node and handles controller processes and containers in Pods. It is also employed to inspect if a node was terminated or set up routers, load balancers, or volumes in the cloud infrastructure. And, it is a cloud-controller-manager that allows you to connect your clusters with the underlying cloud provider API.
2. Etcd- Data Storage (master)
Etcd is a simple and distributed key-value store used to keep and replicate the Kubernetes cluster data. The information it stores includes the number of pods, their state, namespace, API objects, and service discovery elements. It also contains the cluster information in key-value pairs, and to run etcd, you first need to configure a command-line tool to communicate with the said cluster.
3. Kube-control-manager (master)
The Kubernetes controller manager is a master node component. It is a cluster of controllers bundled within a single binary, and it operates on the control process. The node controller, replication controller, and endpoint controller are present within this manager.
4. Kube-scheduler (master)
The Kube-scheduler is a control plane component responsible for appointing pods to nodes within your cluster based on resource utilization. The scheduler will use compute requests, memory usage, and hardware/software constraints.
Worker Node
A worker node runs the containerized applications and will have an instance of kubelet, Kube-proxy, and certain container runtime. A worker node is controlled by the master node, and it constantly reports to the control plane’s api-server regarding its health.
1. Kubelet (worker)
The kubelet functions as an agent within each node in a Kubernetes cluster. It is responsible for the healthy runnings of pod cycles and watching for new or modified pod specifications from master nodes. It ensures that the state of pods matches the pod specification and frequently talks with the Kubernetes API to forward the health details of the pods.
2. Kube-proxy (worker)
Kube-proxy is a network proxy service that runs on each worker node in a Kubernetes cluster. It performs request forwarding to the correct pods/containers and maintains network rules.
Difference Between Kubernetes And Docker
Kubernetes and Docker are two topics that often confuse people in cloud-native technologies. If you need to make a business decision, you might be wondering how these two relate to each other.
Let us understand the difference between them in detail in the below table:
| Kubernetes | Docker |
| Definition | Kubernetes is an ecosystem for manipulating a cluster of Docker containers called pods. | Docker is a container platform for building, configuring, and distributing containers. | |
| Logging and Monitoring | Kubernetes offers in-built tools for logging and monitoring. |
|
|
| Outcome |
Kubernetes is not a complete solution and uses custom plugins to its functionality.
|
Docker uses its own native clustering solution for Docker containers called Docker Swarm.
|
|
| Installation | The installation is complicated in Kubernetes, but the clusters are powerful once set up. | Installation is quick and easy compared to Kubernetes, but the cluster is weak. | |
| GUI | Kubernetes has its own dashboard. | There is no GUI in Docker. | |
| Scalability | Kubernetes is highly scalable and agile. | Docker is also highly scalable and scales 5X faster than Kubernetes. | |
| Auto-Scaling | Kubernetes allows you to do auto-scaling. | Docker does not allow you to do auto-scaling. | |
| Load Balancing | In Kubernetes, manual intervention is required for balancing load traffic among different containers in separate Pods. | Docker does auto load balancing of traffic between containers in the clusters. | |
| Rolling Updates & Rollbacks |
Kubernetes can deploy rolling updates & accomplishes automated rollbacks.
|
Docker can also deploy rolling updates but not automatic rollbacks. | |
| Data Volumes | Kubernetes can share storage volumes only with other containers in the same Pod. |
Docker can share storage volumes with any other container.
|
Challenges Faced By Kubernetes in Production
While Kubernetes has provided an ideal solution to most microservice application delivery issues, people still face many problems when using or deploying containers. As we implement Kubernetes for container orchestration, some challenges are unique to Kubernetes.
Let’s take a more in-depth glance and see how to avoid these challenges to unlock the full potential:
1. Security Issues
Kubernetes is not meant to enforce policies; hence security remains one of Kubernetes’ most significant challenges. In simple words, it is complex, and if not correctly monitored, it can obstruct recognizing vulnerabilities. Using Kubernetes for deployments indirectly provides an easy way for hackers to break into your system.
Solution: To overcome this challenge, organizations must improve security with 3rd party modules and integrate security and compliance in their build, test, deploy, and production stages. Also, the private key can be hidden for maximum protection when you split a front-end and a backend container through controlled interaction.
2. Network Issues
Traditional networking approaches are incompatible, and many organizations have experienced some issues. The challenges such as high latency and package drops you face continue to rise with the scale of your deployment. Other problems that are seen are complexity and multi-tenancy. Ultimately, the root of the problem is the Linux core setup because the performance of Kubernetes is highly dependent on it. Hence, you need to constantly check CPU frequency governor mode.
Solution: Assign the container network interface (CNI) plugin that allows Kubernetes to seamlessly integrate into the infrastructure and access applications on diverse platforms. Another way to deal with this challenge is to increase the size of network buffers in Linux core, the number of queues in NIC, and set up coalesce.
These solutions make container communication smooth, quick, and protected, resulting in a seamless container orchestration procedure.
3. Interoperability Issues
Interoperability can be a significant issue, just like networking. Communications among native apps can be confusing when you enable interoperable cloud-native apps on Kubernetes. It also affects the deployment of clusters and doesn’t work as satisfactorily in production as in development, quality assurance (QA), or staging. Furthermore, you can face many performances, governance, and interoperability problems when migrating to an enterprise-class production environment.
Solution: Users can implement the same API, UI, and command line to reduce the interoperability challenges. Additionally, they can leverage collaborative projects across different platforms such as Google, RedHat, SAP, and IBM to offer apps that run on cloud-native platforms.
Kubernetes in Production – Benefits
Kubernetes is the fastest growing project after Linux in the open-source software ecosystem. There are countless reasons behind that and why every developer chooses Kubernetes as a solution to solve container orchestration needs.
Let us study each of them in particular below:
1. Kubernetes Can Improve Developers Productivity
Kubernetes, with its declarative constructs and its ops-friendly approach, can lead to significant productivity gains if implemented adequately into your engineering workflows. The Cloud Native Computing Foundation (CNCF) landscape makes it easier to use Kubernetes by efficiently reducing the negative impact of its general complexity. Teams can scale and deploy faster by relying on some existing tools made explicitly for cloud-native software. Instead of one deployment a month, teams can now deploy multiple times a day and build solutions that you could barely ever think of yourself.
2. Kubernetes Is Open-Source and Can Be Cheaper Alternative
Kubernetes is fully open-source software (FOSS), a community-led project overseen by the CNCF, and can sometimes be more affordable than other solutions (relying on your application needs). Although Kubernetes is actively developed and maintained, it is usually more expensive for minimal applications due to general computing needs. With many high-profile companies championing its cause, no one company “owns” it or has unilateral authority over how the platform expands.
3. Portability
Kubernetes can run on virtually any underlying infrastructure such as public cloud, private cloud, on-premise hardware, or even bare metal. Developing applications for Kubernetes means that code can be redeployed multiple times on a variety of other infrastructure and environment configurations, making it a highly portable software.
4. Scalability
Kubernetes makes it effortless to scale the number of containers in use horizontally, relying on the application’s requirements. You can modify this number from the command line or utilize the Horizontal Pod Autoscaler to adjust the number of containers based on usage metrics. It makes sure your application is up and running very reliably by rolling updates to adapt your software without downtime.
5. Self-Healing
There are a few reasons for which the containers can fail. Kubernetes keeps deployments healthy by restarting containers that fail, replacing unresponsive containers, killing containers that don’t reply to your user-defined health check and re-creating containers that stood on a failed backend Node across additional public Nodes. It doesn’t advertise them to consumers until they are ready to serve and helps mitigate the application upkeep process’s common pain point.
How to Setup Docker & Kubernetes On Linux System
This tutorial will help you set up Docker, Kubernetes, and its tools in Linux systems. This code can also be used to set up other Linux distributions.
Note: This example will help you set up Docker, Kubernetes, and essential tools required to deploy your applications on your workstation. If you are looking for a tutorial that will help you build your own cluster and deploy apps on the cluster, then follow this great guide.
Pre-requisites
#1. The first step is to install Docker, as it is required on all the instances of Kubernetes. Open the terminal from the root user account, update the package information, and ensure the apt package is working by running the following command.
Command

#2. In the following line, we add the new GPG key, a tool employed in secure apt to sign files and check their signatures. After that, update the API package image.
Command

#3. If all the commands have been executed successfully, you can install the Docker engine. But, it is essential to verify that the kernel version you are using is correct. If not, consider updating the package index.
Command

#4. After this, run the command to install the Docker Engine and the Docker daemon. Verify if the Docker is installed or not.
Command

#5. Now, run the following command to install etcd 2.0 on Kubernetes Master Machine.
Command
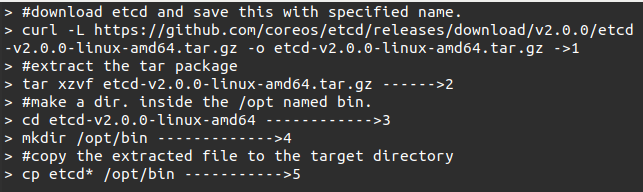
#6. Now is the final stage where we will build Kubernetes and install it on all the machines on the cluster. The following command will create an _output dir in the root of the Kubernetes folder. From here, we can extract this folder into any folder of our choice. In our example, we extract it in /opt/bin.
Command

#7. Now is the networking part. This section will make an entry in the host file to start with the Kubernetes master and node setup. This can be done on the node machine.
Command

#8. We will make actual configurations on Kubernetes Master by copying all the configuration files to their current locations.
Command
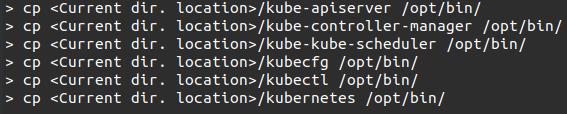
#9. After copying all the configuration files to the required locations, return to the same directory where we built the Kubernetes folder.
Command
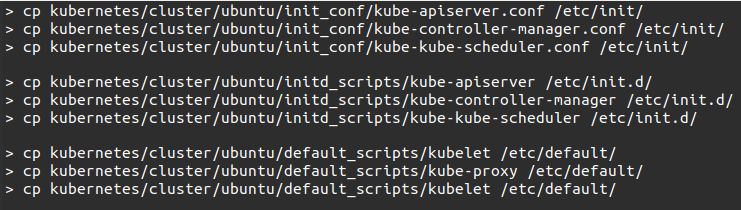
#10. Now update the copied configurations file under /etc.dir. Configure etcd on the master utilizing the below command.
Command

#11. Now we will configure Kube-apiserver on the master. Modify the /etc/default/kube-apiserver file, which we copied before.
Command
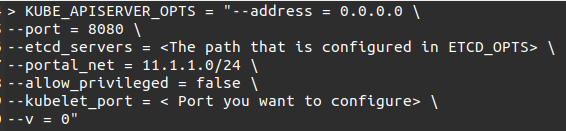
#12. Next, we will configure the Kube Controller Manager by adding the below content in /etc/default/Kube-controller-manager.
Command

#13. Configure the Kube scheduler in the respective file, and we are good to go ahead by bringing up the Kubernetes Mater by restarting the Docker.
Command

#14. The worker node will run two services: kubelet and Kube-proxy. Copy the binaries(we downloaded earlier) to their required folders to configure the worker node.
Command
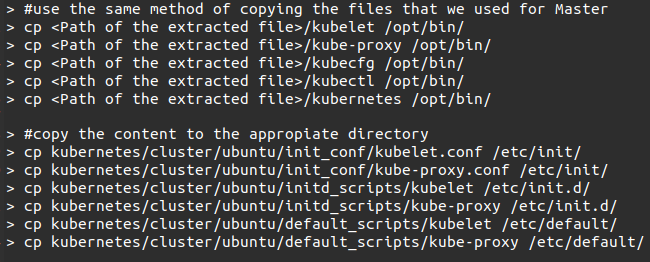
#15. To configure the kubelet and Kube-proxy file, open the configuration at /etc/init/kubelet.conf.
Command
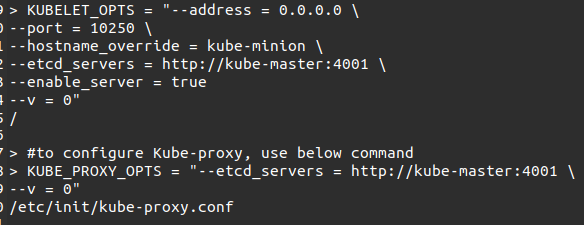
#16. All the configurations for Master and Worker are done. Restart the Docker service and check by running the following commands.
Command

Conclusion: You have now successfully installed Docker and Kubernetes on your system. After this step, you are now ready to deploy your applications on the Kubernetes cluster. This guide here can help you learn How to deploy your first application on the cluster.
Best Practices For Kubernetes in Production
Kubernetes advances a future-proof container solution to enhance productivity, and it has become the most prevalent tool in the DevOps domain, according to CNCF’s 2020 survey.
With popularity, the complexities to manage and handle your cluster also grow. To use your Kubernetes clusters to their full potential, I recommend following the best practices covered in this guide.
1. Always Confirm You Are Using The Latest Version
With its regular version updates, you must always ensure that you are using the latest stable version of Kubernetes in your production cluster because Kubernetes releases new features, bug fixes, and platform upgrades with its periodic updates. Downloading the latest versions will ensure that you don’t miss out on updated security patches that defer potential attack vectors while repairing reported vulnerabilities. Updated security is crucial; hence it is better to update the cluster on the latest version of Kubernetes.
2. Use Version Control For COnfigurations Files
Use GitOps, a Git-based workflow, to store your configuration files linked to your deployment, ingress, services, and other crucial data. It should be done before pushing data to your cluster, as it will help you keep track of who made the changes. Also, adapting to a git-based workflow helps improve productivity by bringing down deployment times, improving error traceability, and automating CI/CD workflows.
3. Monitor Control-Plane Components
One common mistake many practitioners make is forgetting to monitor the Kubernetes cluster’s brain (the control plane). Some of the crucial components of the control panel are the following:
- Kubernetes API Service
- kubelet
- controller-manager
- etcd
- Kube-proxy
- Kube-DNS.
These components are the heart of your Kubernetes cluster, and monitoring them helps determine issues/threats within the cluster and increase its latency.
4. Audit Your Logs On A Regular Basis
The logs of any cluster have a lot to tell, and all records stored at /var/log/audit.log must be audited regularly. Auditing the logs helps to:
- Pinpoint threats
- Monitor resource consumption
- Record key event heartbeats of the Kubernetes cluster
The Kubernetes cluster’s audit policy is present at /etc/Kubernetes/audit-policy.yaml, and you can customize it according to your requirements.
5. Use Small Container Images
Most developers mistake using the base image, usually consisting of up to 80% of packages and libraries they won’t need. It is always advised to employ smaller docker images that take less storage space and allow you to create faster builds. Go for Alpine Images, which are almost 10 times smaller than the base image, and add necessary libraries and packages on the go as needed for your application.
Tech Giants using Kubernetes in Production
Many engineers from Google, Amazon, Red Hat, and others have already understood the power of Kubernetes. Let us see how they are using it:
1. Amazon
Amazon EC2, a top-rated AWS service, uses Kubernetes to manage its clusters, computer instances and run containers on these instances. EC2 uses the processes of deployment, maintenance, and scaling that enables you to run any kind of containerized application utilizing the identical on-premise and in-cloud toolkit. Also, very few people know that amazon has collaborated with Kubernetes’ community. It contributes to its code-base, which assists users in taking advantage of AWS’s components and services. Amazon EKS is a certified conformant used to handle the Kubernetes control plane.
2. Microsoft
AKS is a wholly managed service that uses Kubernetes in Azure without managing its clusters individually. Azure can handle all the intricacies of Kubernetes, while one focuses on the clusters. Some essential features are Pay only for the nodes, more manageable cluster upgrades, and Kubernetes RBAC and Azure Active Directory integration.
3. Apache Spark
Spark is a free and open-source distributed computing framework that handles numerous data sets with the help of a cluster of machines. But it does not control the device. This is where Kubernetes supports. It designs its own driver that runs within the Kubernetes Pod. The driver creates executors that also run within Kubernetes pods. It connects them and executes the code scripts.
Kubernetes in Production – Final Thoughts
Here we are at the end. I hope this guide provided you with the background knowledge and information on major Kubernetes definitions, components, differences, and architecture. The goal of this guide was to brief you on the Kubernetes world to start using it in your team right away.
Please let me know the most critical Kubernetes information we are still missing in the comment section below.
About Author
I am a Data Scientist with a Bachelors’s degree in computer science specializing in Machine Learning, Artificial Intelligence, and Computer Vision. Mrinal is also a freelance blogger, author, and geek with five years of experience in his work. With a background working through most areas of computer science, I am currently pursuing Masters in Applied Computing with a specialization in AI from the University of Windsor, and I am a Freelance content writer and content analyst.
References
1. https://kubernetes.io/docs/tutorials/kubernetes-basics/
2. https://www.redhat.com/en/topics/containers/what-is-kubernetes
3. https://www.tutorialspoint.com/kubernetes/index.htm
4. https://auth0.com/blog/kubernetes-tutorial-step-by-step-introduction-to-basic-concepts/
5. https://github.com/kubernetes/kubernetes
6. https://en.wikipedia.org/wiki/Kubernetes
7. https://cloud.google.com/learn/what-is-kubernetes
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.
Data Scientist and a Technical Writer! I will give you the best of Open-Source and AI.
Talks about #chatgpt, #opensource, #contentcreation, #communitybuilding, and #artificialintelligence
Technical Writer | Data Science, ML, AI, Open-Source | Do More with Data - Litmus






