This article was published as a part of the Data Science Blogathon.
Introduction to SQL
A transaction is a set of operations carried out as a logical unit of work. It is a logical work unit that includes one or more SQL statements. A database system must ensure that transactions are properly executed even if they fail completely or partially. A transaction is most commonly used in banking or the transaction industry.
The below pictorial representation explains the transaction process:
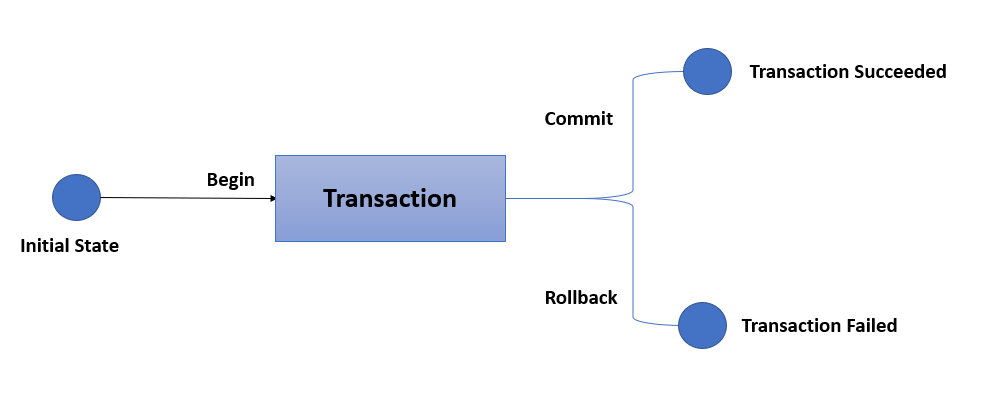
Consider the case of a bank with two customers, Cust A and Cust B. If Cust A wishes to transfer money to Cust B, he or she has three options:
1. Debiting from the Cust A account is successful, as is crediting in the Cust B account.
2. There is no debiting from the Cust A account and no crediting to the Cust B account.
3. Debiting from the Cust A account is successful, but crediting from the Cust B account is not.
The first condition indicates a successful transaction, while the second is less important. We are not required to retransmit, but the third condition will cause a problem if the first operation is successful but the second one fails due to a technical issue. As a result, the Cust A account will be debited but the Cust B account will not be credited. This implies that we will lose the data. We can use transaction management to solve all of these issues. A transaction guarantees that either a debit or a credit will be performed, or that nothing will be performed.
Using Transaction in SQL
The transaction control mechanism uses the following commands:
- BEGIN: To start a transaction.
- COMMIT: To save changes. After the commit command, the transaction can’t rollback.
- SAVEPOINT: Provides points where the transaction can rollback to.
- ROLLBACK: To rollback to a previously saved state.
1. Begin transaction
It denotes the beginning of a local or explicit transaction.
Begin transaction T1
2. Commit Transaction
The database modifications are permanently reflected through commits. “COMMIT” is the statement that initiates the transaction.
Commit;
3. Rollback
Rollback is used to undo modifications, meaning that the record will remain in its original state and not be modified. “ROLLBACK” is the statement that initiates the transaction.
rollback;
4. savepoint
A transaction statement also includes SAVEPOINT. This statement was used to establish a system store point so that the ROLLBACK operation could reach the savepoint’s state.
savepoint s1;
Let’s see one example of a transaction in SQLPlus :
First, create a table:
SQL> create table student( id int, name varchar(15), last_name varchar(15), address varchar(20));
Table created.
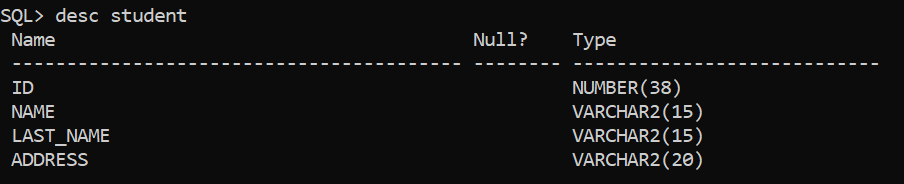
SQL> desc student
Insert Records in table student:
SQL> insert into student values(1,'aarti','parekh','surat');
insert into student values(2,'uday','patel','valsad')
insert into student values(3,'om','parekh','bardoli')
insert into student values(4,'anjali','soni','ahmedabad')
insert into student values(5,'aarav','soni','baroda');
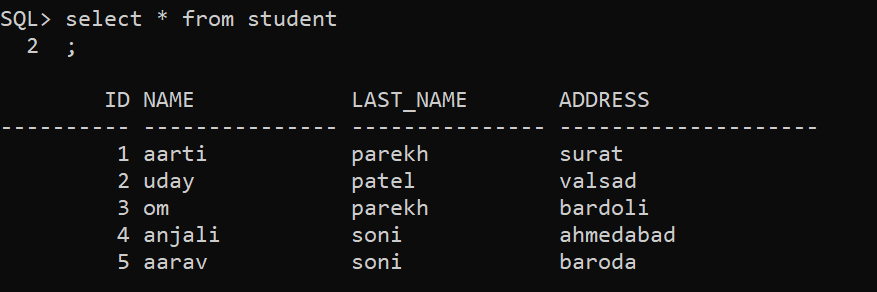
Now we are going to check whether records are inserted or not by using following command
SQL> select * from student
Now let’s try to understand the concept of commit, rollback and savepoint on the above table student.
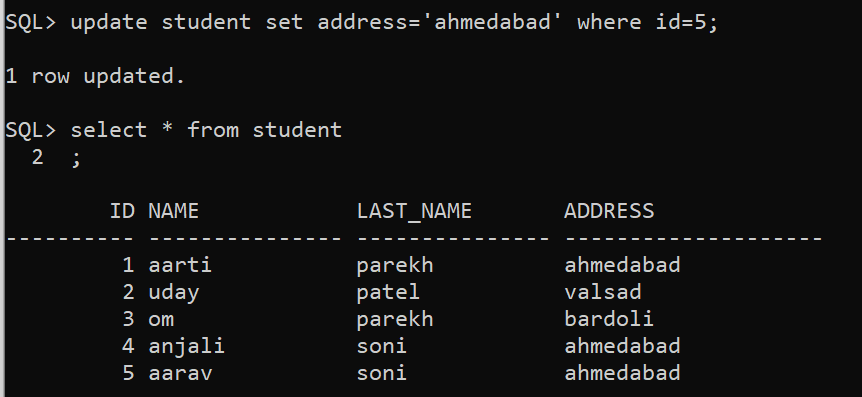
Now, I am going to update the address of the student whose id is 5.
SQL> update student set address='Ahmedabad' where id=5;
1 row is updated.
SQL> commit;
Commit Complete.
So here we have changed the data of students and saved changes successfully by using the commit command.
Now, we are going to create savepoint by following :
SQL> savepoint s1;
Savepoint created.
To understand this concept better, we are going to delete the record which I have updated in the last statement.
SQL> delete from student where id=5;
1 row was deleted.
Let’s check the updated table after the deletion of one record.
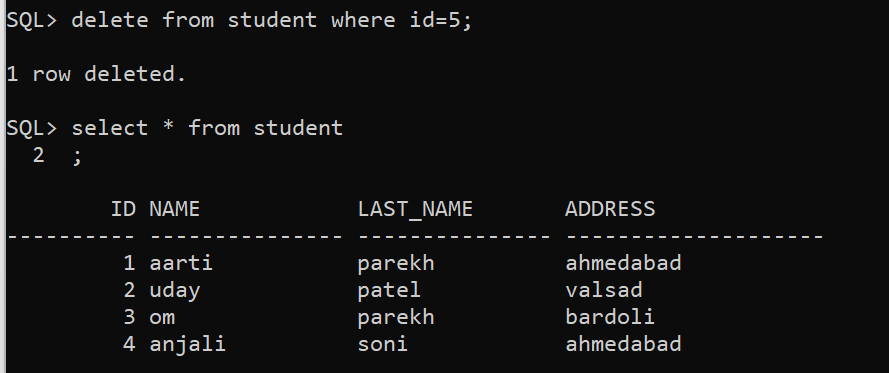
So I have deleted the last row which I have updated but now I want to undo the deletion operation. So we have already created savepoint before the delete operation. So we will roll back to that savepoint and will get records back. So let’s see.
SQL> rollback to s1;
Rollback complete.
Above code undo changes upto savepoint s1 and we will get the original table before the creation of savepoint.
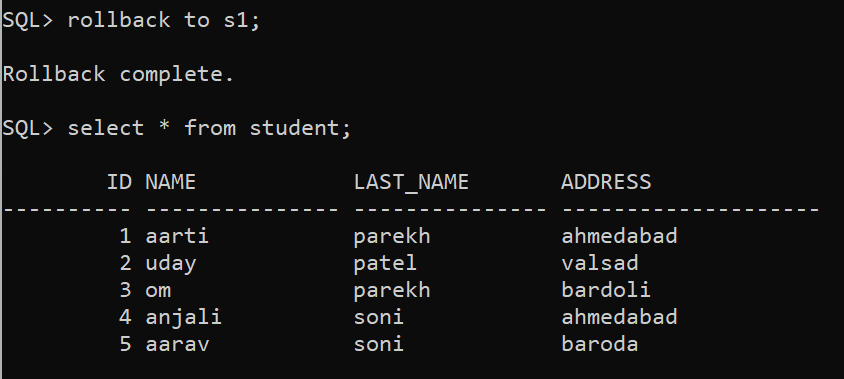
So this is how the transaction works in SQL.
Now we’ll see the basics of “Transaction Management”
A transaction is made up of four properties, which are also known as ACID rules.
ACID Properties
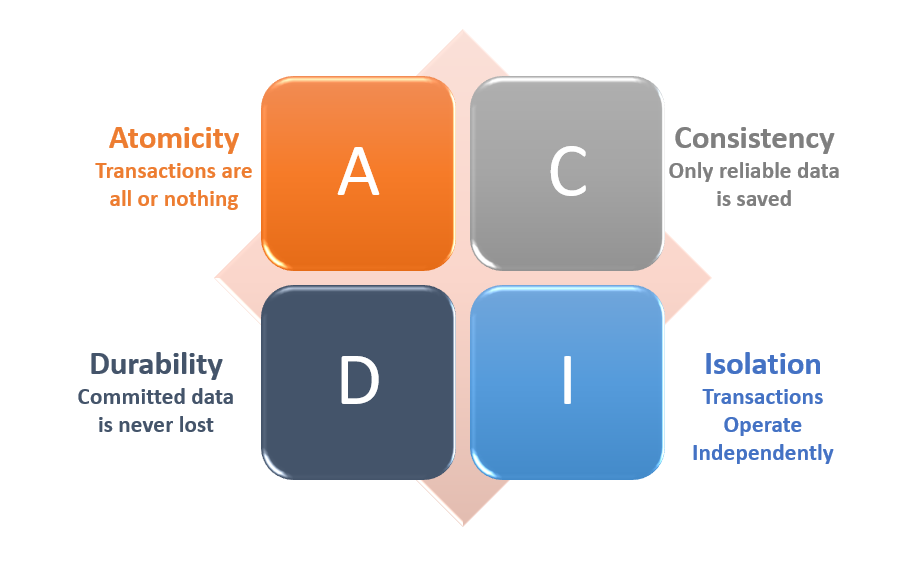
1. Atomicity
2. Consistency
3. Isolation
4. Durability
1. Atomicity
Atomicity indicates that a transaction must be treated as an atomic unit, which means that either all or none of its operations must be executed.
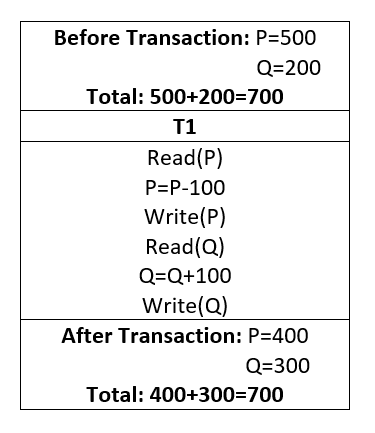
For example, consider a transaction to transfer Rs. 100 from account P to account Q.
In this transaction, if Rs. 100 is deducted from account A then it must be added to account B.
Let’s assume the following transaction T which has two transactions T1 and T2:

If the transaction fails after completing T1 but before completing T2, the amount is deducted from P but not added to Q. consequently, the database is in an inconsistent condition. As a result, the transaction must be completed in its entirety to ensure that the database state is correct.
2. Consistency
After any transaction, the database must maintain consistency. If the database was consistent before a transaction, it must be consistent once the transaction is finished. In our example, the total of P and Q must remain the same before and after the execution of the transaction.
3. Isolation
Changes made in one transaction are not visible in other transactions until that transaction is committed. The results of intermediate transactions must be hidden from continuously running transactions. For any pair of transactions, one should begin execution only after the other has been completed.
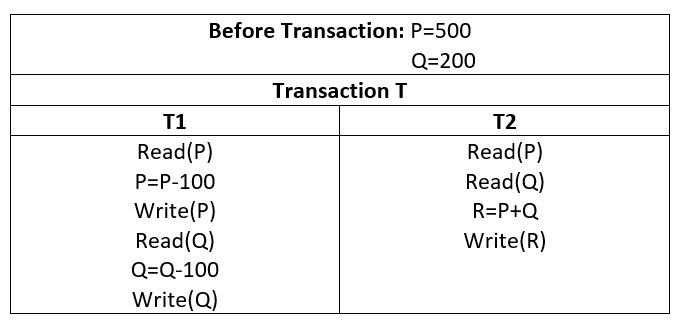
• In the above example, after T2 Transaction,
P=500
Q=200
P+Q=700 which is incorrect. Because Transaction T1 read the correct value of P but Transaction T1 performs some operation on P which is not reflected in Transaction T2 which is 400. But T2 reads the original value of Q which is 200.
• In our example once our transaction starts from the first step (step 1) its result should not be accessed by any other transaction until the last step (step 6) is completed.
• So transaction results should not be accessible to another transaction until the first transaction is completed.
4. Durability
• After a transaction completes successfully, the changes it has made to the database persist (permanent), even if there are system failures.
• Our transaction must be saved permanently once we’ve completed the last step (step 6). If the system fails, it should not be eliminated.

If the database is lost, however, the recovery manager is in charge of ensuring the database’s long-term viability. We must use the COMMIT command to commit the values every time we make a change.
Schedule
A schedule is a method of combining transactions into a single batch and executing them in a specific order. It is the order in which instructions in a system are performed in a chronological (sequential) order. In a database, a schedule is essential because when multiple transactions run in parallel, the outcome of the transaction may be influenced. This means that if one transaction updates the values that the other transaction accesses, the sequence in which these two transactions execute will affect the outcome of another transaction. As a result, a schedule is made to carry out the transactions.
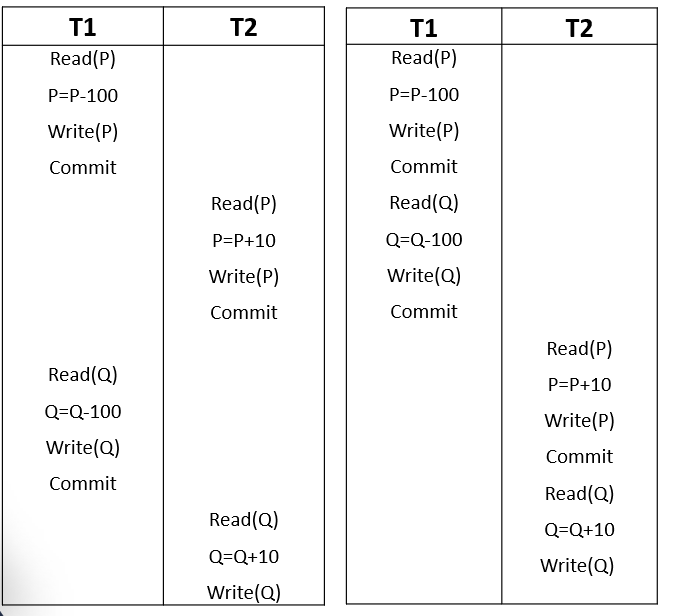
Kindly see the below example of the schedule:

In the above example, Transaction T1 reads and updates the values of P and Q. After committing the operation to perform by T1, T2 start its execution and performs operations.
Serial Schedule
A serial schedule is one in which no transaction begins until the previous one has been completed, and transactions are carried out one after the other. Because transactions are processed in sequential order, this type of schedule is known as a serial schedule. The above schedule is an example of a serial schedule.
Serial schedules are used as a benchmark in multi-transaction environments. The execution sequence of a transaction’s instructions cannot be modified, however, the instructions of two transactions can be performed in random order. If two transactions are mutually independent and work on different segments of data, this execution is harmless; but, if the two transactions are working on the same data, the outcomes may differ. This constantly changing outcome may cause the database to become inconsistent.
To tackle this difficulty, we allow a transaction scheduled to be executed in parallel if its transactions are serializable or have some equivalence connection.
Equivalent Schedule
Two schedules are considered to be equivalent if they provide the same result after execution.
They may produce the same result for some values while producing different results for others.
As a result, this equivalence isn’t widely thought to be noteworthy. Following is the example of an Equivalent schedule where both the schedules are producing the same result after Execution.
Benefits of using Transaction in SQL
Using transactions enhances performance; for example, inserting 100 entries using transactions takes less time than standard insertion. In a typical transaction, COMMIT would be executed after each query execution, increasing the execution time each time; however, in a transaction, there is no need to run the COMMIT statement after each SQL query. In the end, COMMIT would permanently reflect all of the modifications to the database. Also, if you use a transaction, reversing the modifications is a lot easier than it is with a regular transaction. ROLLBACK will undo all of the modifications at the same time, restoring the system to its former state.
Conclusion
This article will provide a fundamental understanding of SQL transactions along with the ACID Properties. In relational database systems, transactions using SQL are beneficial because they ensure database integrity. We have also seen the basics of scheduling which can able to manage multiple transactions which are running concurrently. so we can see that by using scheduling, operations are performed based on the sequence and only one operation can be performed at a time.
Are you preparing for a job interview? Read this article on 20 SQL Coding Interview Questions and strengthen your concepts more than ever!
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I currently working as an Assistant professor in the Information technology department at SAL COLLEGE OF ENGINEERING, AHMEDABAD .I am currently doing Ph.D. in Medical Image processing. My research interest are computer vision, deep learning, machine learning, database etc.







it Is very useful article