Introduction
AWS Lambda Event Notifications allow you to receive notifications when certain events happen in your Amazon S3 bucket. S3 Event Notifications can be used to initiate the Lambda functions, SQS queues, and other AWS services. The benefit of using S3 Event
Notifications is that it allows you to automate tasks and processes that would otherwise need to be done manually, improving efficiency and reducing errors. This article will cover how a lambda function gets invoked when an object is uploaded in an S3. Before seeing the practical implementation of how to use an Amazon S3 trigger to invoke a lambda function, let’s have a brief introduction to Amazon S3 and Lambda Functions.
Learning Objectives
- Understand the concepts of Amazon S3
- Understand the concepts of AWS Lambda
- Understand the concept of S3 event notification to automate some task
- Key features of AWS Lambda
- Limitations of AWS Lambda
This article was published as a part of the Data Science Blogathon.
Table of Contents
- Overview of Amazon S3
- What is AWS Lambda?
- How to invoke the Lambda function on the S3 trigger?
3.1 Create a bucket
3.2 Modify the existing Lambda Function and Create an IAM Role for Lambda Function - Features of AWS Lambda
- Disadvantages of AWS Lambda
- Conclusion
Overview of Amazon S3
Amazon S3 (Simple Storage Service) is a cloud-based storage service that allows users to store and retrieve data through the internet. It is used because it is highly scalable, reliable, and inexpensive. This makes it a popular choice for storing and managing large amounts of data, backups, media files, and data for web and mobile applications. Additionally, S3 provides features such as data durability, versioning, and security, which makes it a suitable option for a wide range of use cases, including data archiving disaster recovery, and big data analytics. Amazon Simple Storage Service(S3) provides object-level storage. It stores data in the form of an object. To store your data on S3 you have to first create an S3 bucket and the name should be globally unique. You can not create nested buckets i.e. you can not create buckets inside buckets. Amazon S3 uses standard-based REST API. Some of the important key points of Amazon S3 are:
- Amazon S3 is designed to deliver 99.999999999 %(11 9s) durability.
- S3 can store any file type.
- File size can be anywhere between 0 bytes to 5 TB.
- Objects which are larger than 100 MB can be uploaded via multi-part upload.
- Objects in S3 consist of:
- Key(Name of the object)
- Value(Value of the object)
- Version Id
- Metadata
- ACLs(Access Control Lists)
What is AWS Lambda?
AWS Lambda is a computing service for serverless. Serverless means that your code runs on servers, but you don’t have to manage the servers.
One of the important benefits of cloud computing is its ability to abstract the infrastructure layer. This eliminates the need to manually manage the underlying infrastructure or instances that are hosting your applications. By building serverless applications you can focus on the code that makes your business more impactful. Here is an overview of howLambda works:
- Create a Lambda function that contains your code and other dependencies. You can write your code in any of the supported languages (e.g., Node.js, Python, Java, C#, Go, and Ruby).
- After writing the code, configure the triggers for your Lambda function by using Amazon S3 or Amazon Kinesis to invoke the function when certain events occur.
- When the trigger happens, an AWS Lambda gets a request from an event source (Amazon S3, Amazon Kinesis etc.) to start the function.
- AWS Lambda automatically provisions and scales the necessary infrastructure to run your code, including the compute resources (e.g., CPU and memory) and the runtime environment.
- Lambda code is run in an isolated and secure environment, and any output is returned to the event source.
- You only pay for the compute time that your function uses, and you are charged based on the number of requests and the duration of each request. . If the function runs for 1 ms then you will get a bill for only 1 ms.
- AWS Lambda automatically monitors the health of your function and restarts it if necessary.
- You can also set up logging for your function, which allows you to view the logs for your function in CloudWatch.
Let’s see how to create a basic lambda function from the console.
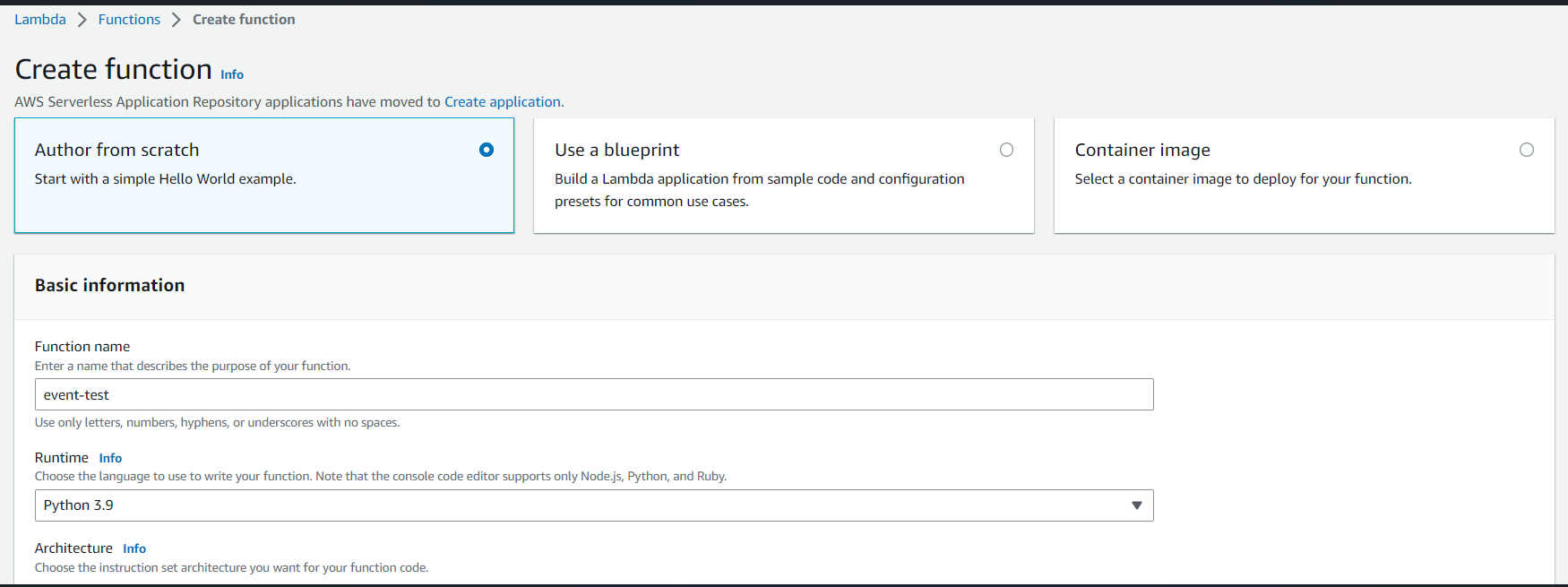
Step 1: Go to AWS Console, search for Lambda, and choose the Create function.
Step 2: Select Author from scratch, give some function name, and choose the Runtime Environment. Leave the rest of the options as default.
Step 3: Click on the Test tab to invoke a function from the console.
Step 4: For the test event, create a new event and give an Event name. For Event sharing settings, choose Private, and for Template, leave it to default.

Step 5: Save it and then click on Test. You can see the logs from the Monitor tab. It will show the logs which Lambda sends to CloudWatch.
S3 Trigger to Invoke Lambda Function
Create a bucket
Step 1: Open AWS Console and search for S3. Click on Create bucket.
Step 2: Under General Configuration, enter a unique bucket name and select the AWS Region. Leave the rest of the options as it is and click on Create bucket.
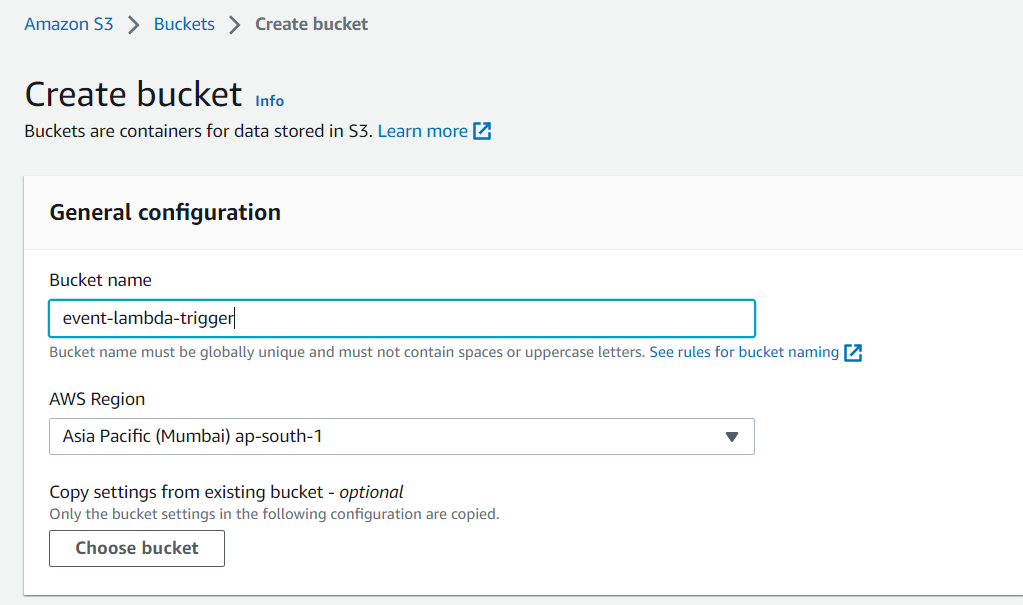
Note: The bucket AWS Region and Lambda function AWS Region should be the same.
Modify the existing Lambda Function and Create an IAM Role for Lambda Function
Step 1: Click on Add Trigger and select s3 from the list. Select All objects to create events in the Event type.

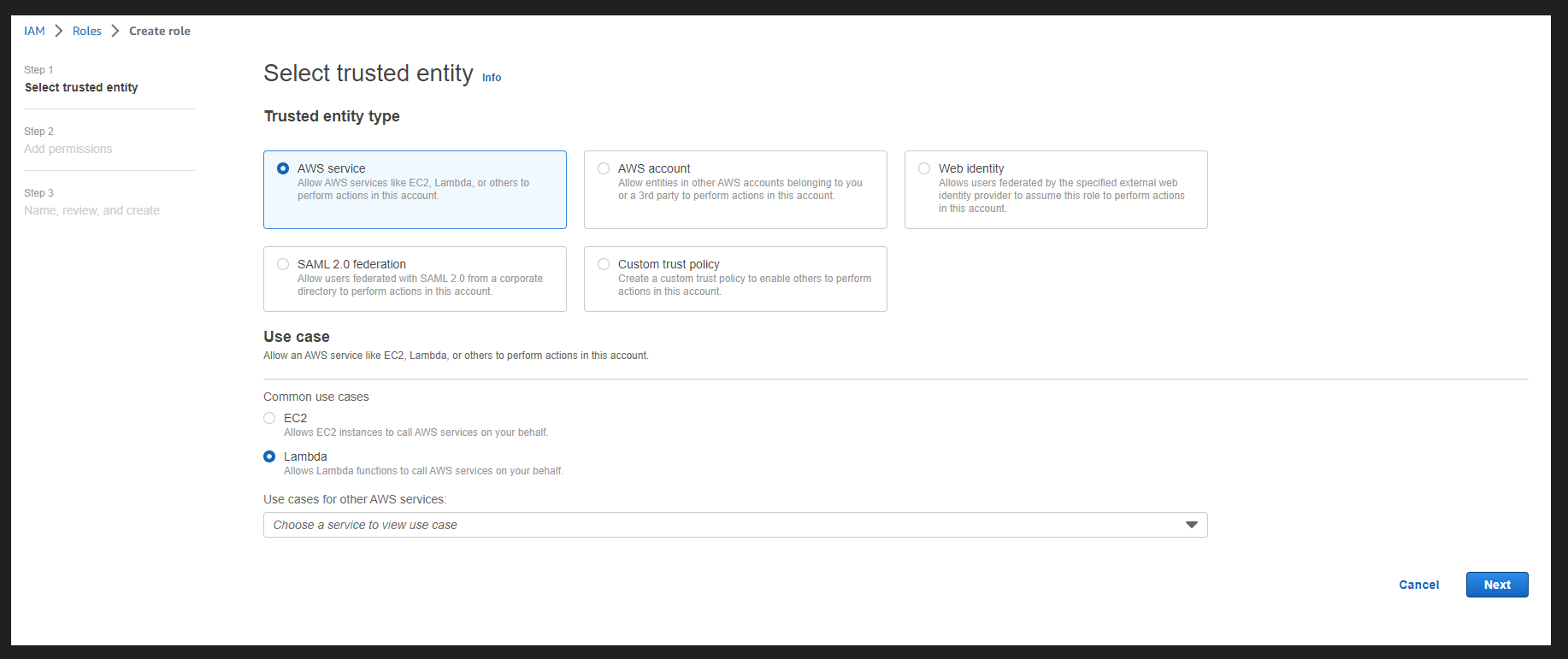
Step 2: Create an IAM Role for Full S3 Access and Full CloudWatch Access. From IAM Roles, click on Create role. Select AWS service from the Trusted entity type and select Lambda from the Use case. Click on Next.
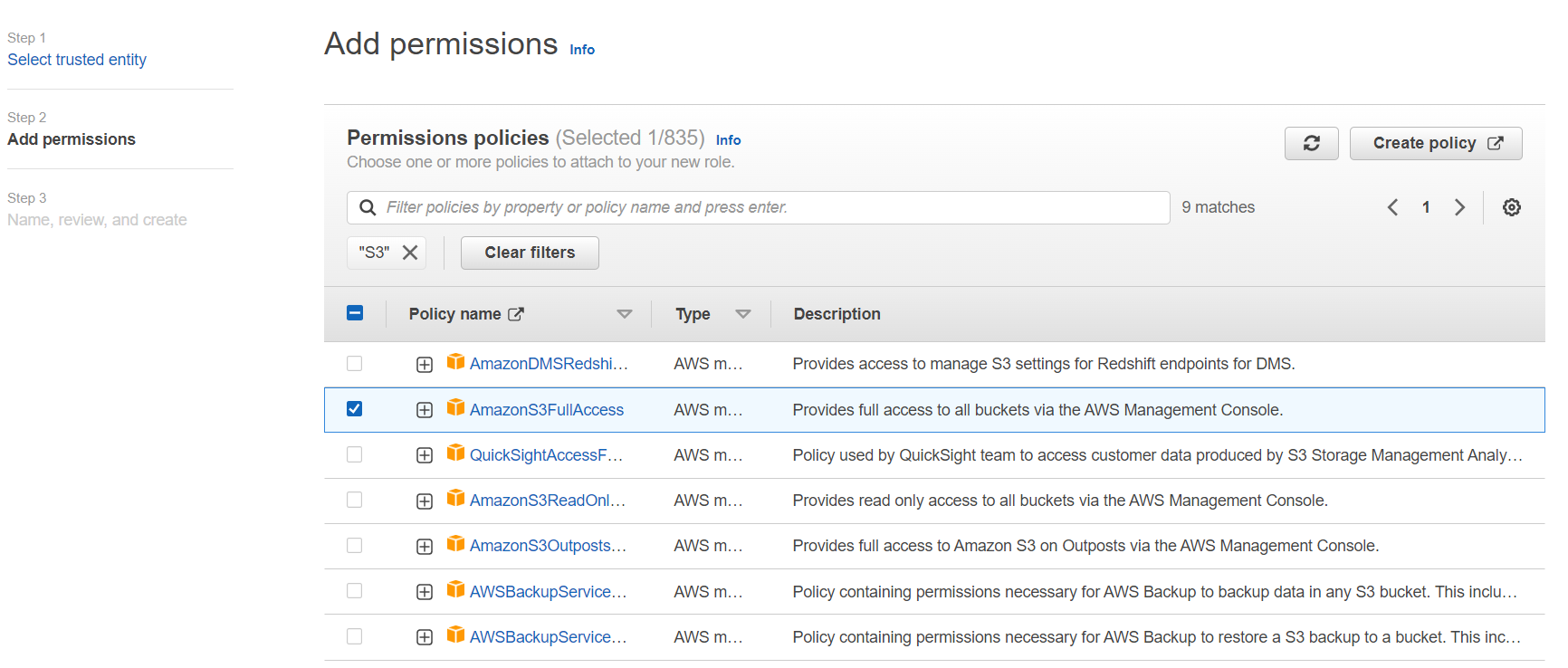
Step 3: From Permission policies, select AmazonS3FullAccess and CloudWatchFullAccess and click on Next.
Step 4: Give the Role name and leave the rest of the fields with a default value. Click on Create role.
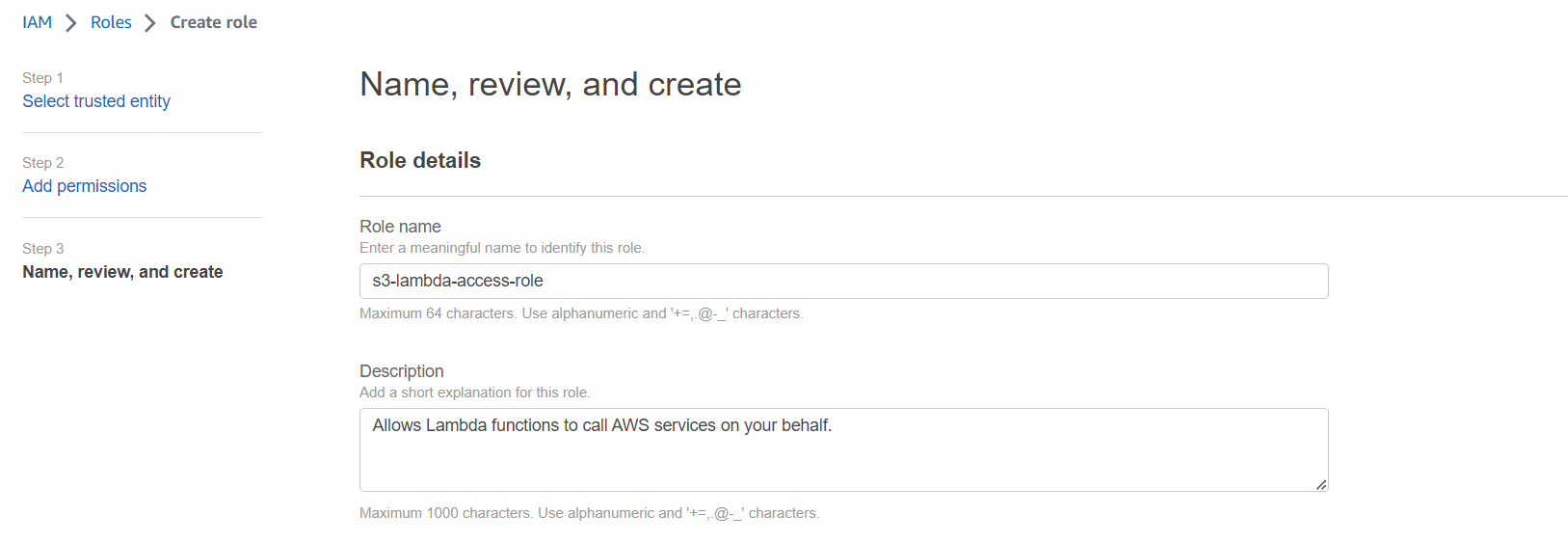
Step 5: Once the role is created, go to your existing lambda function and add Permission.
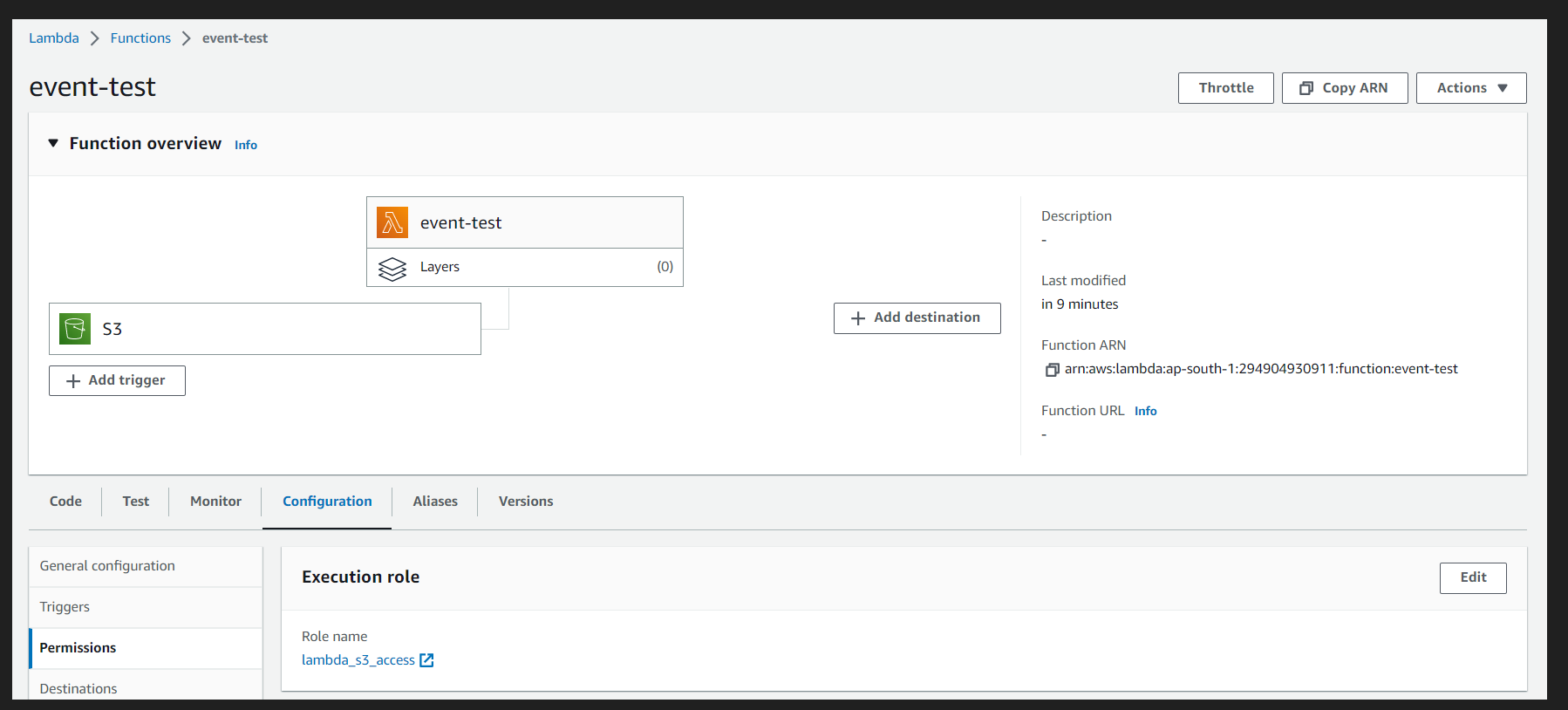
Step 6: Go to the lambda_handler function and change the existing code. To access the s3 object, you need Boto3. Boto3 is Python SDK to access AWS services, and by default, it comes with a lambda function, so you don’t have to install it explicitly.
import boto3
from urllib.parse import unquote_plus
def lambda_handler(event, context):
"""Read file from s3 on trigger."""
s3 = boto3.client("s3")
if event:
file_obj = event["Records"][0]
bucketname = str(file_obj["s3"]["bucket"]["name"])
filename = unquote_plus(str(file_obj["s3"]["object"]["key"]))
print("Filename: ", filename)
fileObj = s3.get_object(Bucket=bucketname, Key=filename)
file_content = fileObj["Body"].read().decode("utf-8")
print(file_content)
return "File is uploaded in S3"
Step 7: Upload a file in your bucket.
Step 8: Go to CloudWatch and check the logs.
Features of AWS Lambda
- Event-driven: AWS Lambda can be triggered by a wide variety of events, such as changes to data in an S3 bucket or a new message in an SQS queue.
- Automatic Scaling: AWS Lambda automatically scales your application in response to incoming requests, so you don’t have to worry about provisioning or managing servers.
- Pay-per-use: With AWS Lambda, you only pay for the compute time that you consume. There are no upfront costs or long-term commitments.
- Built-in Security: AWS Lambda integrates with other AWS services to provide built-in security features such as automatic patching, network isolation, and encryption of data at rest and in transit.
- Flexible Deployment Options: AWS Lambda allows you to deploy your code as a standalone function or as part of a larger serverless application, using the AWS Serverless Application Model (SAM) or AWS CloudFormation.
- Support for Multiple Languages: AWS Lambda supports a variety of programming languages including Node.js, Python, Java, C#, and Go.
Disadvantages of AWS Lambda
- Cold Starts: When a Lambda function runs for the first time there may be a delay before the function starts. This is known as a “cold start.” This can be caused by the time it takes to spin up a new container for the function.
- Memory Limitations: Each Lambda function can be configured with a specific amount of memory, which also determines the amount of CPU and network bandwidth available to the function. If an application requires more resources than what is allocated, it may experience performance issues.
Conclusion
This article shows how you can deploy your code on AWS Lambda. By using AWS Lambda you can focus more on your business logic rather than worrying about how to manage the underlying infrastructure or instances. You pay only for the compute time,i.e. only for the time your code runs. By using an event-driven architecture with
S3, you can build more automated and scalable workflows for your data and easily integrate S3 with other AWS services to create powerful, serverless applications.
Some of the key takeaways from the article are:
- You have learned how to create a basic lambda function.
- You have also learned how to add IAM Role to get full access to Amazon S3 and CloudWatch.
- You have also learned how a lambda function is invoked when you upload an object in an S3 bucket.
- You can configure S3 to automatically resize an image when it’s uploaded to a specific bucket.
- You can configure S3 to automatically create a backup of an object when it’s created or updated.
- You can configure S3 to automatically trigger an AWS Lambda function to process data when it’s uploaded to a specific bucket.
- You can use Lambda Layers to manage common dependencies for your Lambda functions in a separate layer.
I hope you liked the article. You can connect with me on Linkedin for further discussion or comment below. HappyLearning 🙂
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
A passionate data science professional with 3+ years of experience as a Data Scientist. Proficient in data processing and experience in building end-to-end Machine Learning solutions including Deep Learning, NLP. Worked on various cloud platform including AWS, Azure and GCP.






