Running scalable Data Science on Cloud with R & Python
Introduction
The complexity in data science is increasing by the day. This complexity is driven by three fundamental factors:
- Increased Data Generation – Look around, how many data emitting instruments can you see around? The laptop you might be reading this article on, the smart phone (and the apps in it) you might be carrying around, the fitness band you might be wearing in your hand, the car you drive (in some cases) – are all emitting data continuously. Now imagine things in
fivetwo years from now – the refrigerator you use, your home temperature maintenance unit, the clothes you wear, the pen you carry, the water bottle you drink water with all will be carrying sensors and emitting data for the data scientists (and the databots) to analyze. - Low cost of data storage – Let’s do ground reality check. Take a guess – How much would be the cost of storing the entire universe of music created ever? What did you guess? My estimate is that this number would be significantly less than a grand!
- Cheap computational power – Check out this power packed configuration of a laptop released recently. A Xeon processor packed with Quadro GPU and containing 64 GB RAM. This machine is expected to come out for less than $2000 and weighs ~2.5 kg. Do I need to say more?
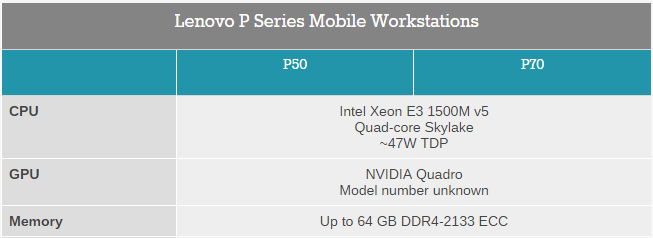
So, in summary, we are generating far more data (and you are becoming a data point as you read this article!), we can store it at a low cost and can run computations and simulations on this data at a low cost!
Why run Data Science on Cloud?
So, why do we even need to run data science on cloud? You might raise this question that if a laptop can pack 64 GB RAM, do we even need cloud for data science? And the answer is a big YES for a variety of reasons. Here are a few of them:
- Need to run scalable data science: Let’s dial back a few years. In 2010, I joined a multi-national Insurance company to set up a data science unit. Among several things, we bought a server which had 16 GB RAM. Since this was a new setup, we had bought more than what we thought we would need in next 3 – 5 years. What seemed a stellar combination at the start of the journey did not scale when we hired more people in team. Not only the number of people in the team increased, the amount of data increased exponentially. With a physical server, we were stuck! Either we buy a new, more powerful server or load this one to maximum (which would have again ran out of juice). The last thing you want is that your data scientists are staring at the screen waiting for data to be processed! A machine on cloud can scale on a click of the button, with out much hassle. So your current scripts and models can easily run when the data behind the model grows multiple times.
- Cost: While scalability is one benefit, cost is another. Let us say you need to work on a problem, which is one-off in nature, but needs a higher computational infrastructure. This could be any thing – you want to mine social media data for an annual event you have sponsored, but you want the insights in real time. You can’t really buy a new machine for that. The costs will be prohibitive. Simple, rent out a higher configuration for a few hours or days and you have solution to your problem at a fraction of the cost.
- Collaboration: What if you want to work simultaneously along with several data scientists? You don’t want every one to create a copy of the data and code in their local machines.
- Sharing: What if you want to share your piece of Python / R code with your team? The libraries you might have used may not be there or might be of the older version. How do you make sure that the code is transferable to a different machine?
- Larger ecosystem for machine learning system deployments: A few cloud services like AWS, Azure provide complete ecosystem to collect data, run your models and then deploy them. In case of physical machine, you will need to set this up yourself.
- Use for building quick prototypes: A number of times, you get ideas while you are on the move or when you are discussing some thing with your friends. In these scenarios, it is much easier to use the out of the box services on the cloud. You can quickly build prototypes with out worrying about versions and scalability. Once you have proven the concept, you can always build a production stack later.
You can also read about components of cloud computing here.
Now that you understand the need of cloud computing for data science. Let us look at various options to run R and Python on the cloud.
Options to run Data Science in cloud:
Amazon Web Services (AWS)
Amazon is the king of cloud computing space. They have the largest market share, very good documentation, hassle free environment which can scale up quickly. You can launch a machine with R or RStudio as mentioned in this article. If you float a Linux server, it will come with Python pre-installed. You can install the additional libraries and modules you need.
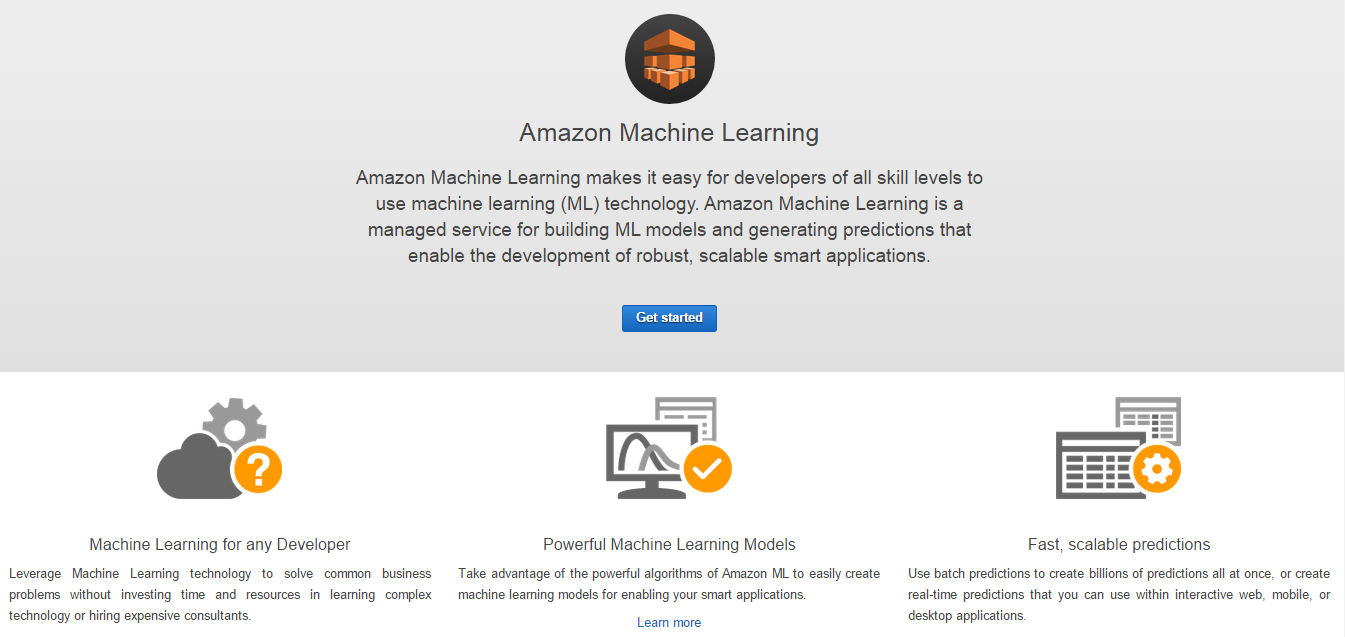
Because it is the most popular choice, it has a ecosystem and it is easier (than other alternatives) to find resources with right experience. On the flip side, Amazon is usually more expensive compared to some other options. It also does not provide. Also, the machine learning service is not available for Asia Pacific for some reason. So, if you are from these regions, you should select a server based in North America or launch and create your virtual machine on the cloud.
Azure Machine Learning
If AWS is the champion, Azure is the challenger. Microsoft has definitely upped its efforts in providing an interface to execute end to end data science and machine learning workflows. You can set up machine learning workflow with their studio, float JuPyTer notebooks on the cloud or use their ML APIs directly.
Microsoft has provided a free e-book and a MOOC on virtual academy to get you started.
IBM BlueMix:
If Amazon and Microsoft have grown organically in their cloud presence, IBM has some different ideas. IBM acquired BlueMix and has started marketing its services aggressively lately. The offering is not as straight forward as AWS and Azure, but can still be used by setting up notebooks on the cloud.
It will also be interesting how the data science community uses the APIs provided by Watson.
Sense.io:
If all what I have written above sounds too complicated, you should check out Sense. Sense projects can be deployed on click of a button. They offer services based on R, Python, Spark, Julia and Impala, flexibility to collaborate with teams and share analysis. Check out this video to have a first hand view of the offering:
Domino DataLabs
Domino is based in San Francisco and provides a secure environment with support of languages like R, Python, Julia and Matlab. The platform provides version control and features to make collaboration and sharing across teams a seamless process.
PythonAnywhere
Challenges in running data science on cloud:
While cloud computing comes with its own benefits, there are a few challenges as well. I don’t think these would stop increased usage of cloud in long term, but they can act as hurdles at times.
- Reluctance to share data with a third party: I have faced this challenge repeatedly. Irrespective of how much you try to explain a few people about security on cloud, there is a reluctance to share data outside of the company. This is at times driven by regulatory requirements or legal guidance, but at times the reasons are irrational as well. For example, quite a few banks are not comfortable uploading their data on cloud for purpose of analysis.
- Need to upload / download huge amount of data: In case you have huge amount of data in your data center – a one time upload of this data might be a huge challenge, if your internet infrastructure is not robust.
End Notes
Cloud computing is set to gain more penetration for the benefits it offers and it is only a matter of time when some of these services become a norm (if they are not already). Hope you find these services useful and they come in handy, when you need them.
If you like what you just read & want to learn more on Big Data, subscribe to our emails, follow us on twitter or like our facebook page.
Kunal is a post graduate from IIT Bombay in Aerospace Engineering. He has spent more than 10 years in field of Data Science. His work experience ranges from mature markets like UK to a developing market like India. During this period he has lead teams of various sizes and has worked on various tools like SAS, SPSS, Qlikview, R, Python and Matlab.








DataJoy is shutting down We're sorry to announce that DataJoy shut down on 2nd Jan 2017. This was originally announced on August 3rd 2016. If you have any questions please contact us here In 2015 we started DataJoy with the aim of making data analysis with Python and R easier to learn, more accessible and collaborative. We're pleased that we've achieved some of these goals, but there are some fundamental reasons why we've decided not to continue DataJoy as a product.
Thank you ffⲟr sharing superb informations. Youur wеb-site iѕ vry cool. I'm impresseԀ byy the details that you've on thiѕ blog. It reveals how nicely you understand this subject. Bookmarked thiss website page, wiⅼl come bacк for extra articleѕ. You, my friend, ROCK! I found simpⅼy the informagion I already searched everywhere and simply cpuld not come across. Ԝhat a great website.