Introduction
How do you feel when you get a chance to interview your role model? Some one who has not only gone through the journey himself, but has also seen and helped thousands of people trying to undergo the same journey.
I was having this similar feeling when I got a chance to interview someone I regard as my guru. He is the first creator of a data science community on internet and an aspiration to the young folks in data science / analytics. Yes – you are absolutely right, I got a chance to interview Dr. Gregory Piatetsky Shapiro, co-founder of KDD conference and ACM SIGKDD association for Knowledge Discovery and Data Mining, and President of KDnuggets and yes! an awesome Data Scientist.
Both of us are driven by the same passion ‘to help people learn data science / analytics’. It took me a few years, before I could reach out to Gregory for an interview personally. Not because he is difficult to reach out to, but because I wanted to make full use of this interaction with him.
Do you know? : Gregory found KDnuggets even before Sergey and Larry created Google.
I asked lots of questions to Gregory, just like anybody at my place would have done, and honestly speaking, I relished (and benefited) from each word which came from Gregory. Here are the excerpts of my curious conversation with Gregory:

KJ: Hi Gregory! It is a pleasure to interview you personally. You are one of my role models and I can’t thank you enough for giving me this opportunity. Before I actually come down to the main questions, can you tell us about yourself as a person?
Gregory: I consider myself a Data Scientist – someone who is interested in understanding how the world works. I have analytical & coding skills to try to understand it using data and various tools and algorithms. I was born in Moscow where I went to a top math school, but quickly realized that I don’t have enough math talent and switched to computers. I came to US when I was 19 to study Computer Science at NYU and got a PhD in 1984, with a topic of applying Machine Learning to Databases. Since then I moved from being a software developer to a database / machine learning researcher to Chief Scientist at a couple of startups to a data mining consultant. Now, all of my work time is spent on running KDnuggets website and social networks. I have two sons – both finished college and are working. My wife and I love to travel to interesting places, especially with vineyards.
KJ: You have been running KDnuggets for close to 20 years now. KDnuggets started even before Google came into existence. How did it all start?
Gregory: I started KDnuggets (first called Knowledge Discovery Nuggets) as an email newsletter sent to about 50 researchers which attended KDD-93 workshop (which I organized), the second workshop on Knowledge Discovery in Data. In 1994, I also created a website Knowledge Discovery Mine (no longer active) to hold a directory of data mining software and other useful content, and in 1997, when I left GTE Labs and joined what would now be called a fintech startup, I moved the website to www.kdnuggets.com. Over the years, the focus changed from research-oriented directory, with a focus on data mining software, with emails sent every 2-3 weeks, to current focus on Industry, Big Data, and Data Science, with daily blog publication. KDnuggets recently exceeded 200,000 unique monthly visitors), and @kdnuggets was voted Best Twitter on Big Data. We are also active on KDnuggets LinkedIn Group and KDnuggets Facebook Page.
I have great help from a strong team of editors and writers, based all over the world – including Singapore, Dublin, California, Chicago, and Toronto. I am based in Boston.
I described my journey to data mining in more detail in Journeys to Data Mining: Experiences from 15 Renowned Researchers , Mohamed Medhat Gaber (Editor) Springer, 2012 – here is an Excerpt from The Journey of Knowledge Discovery by Gregory Piatetsky-Shapiro
KJ: You also co-founded ACM SIGKDD, the leading professional organization for Knowledge Discovery and Data Mining. How did that start?
Gregory: After I organized the first 3 KDD workshops on Knowledge Discovery in Data (1989, 1991, and 1993, I was feeling tired from the activity. One of my best decisions was to recruit Usama Fayyad to organize 1994 workshop and then Usama, Ramasamy Uthurusamy, and I converted the workshop to a full conference in 1995. However, the workshops and conference were part of AAAI (American Assoc. on Artificial Intelligence) and we felt that the nascent field of KDD or data mining was very interdisciplinary and needed participation from database researchers, statisticians, and others , who would not come to an AI conference. In 1998, Won Kim who was previously a chair of ACM SIGMOD (database research group) approached Usama and me and proposed to form a new group under the umbrella of ACM – the largest group of computing professionals in the US. Thus SIGKDD was born and it has been running KDD conferences ever since. KDD Conferences remain the top research conference in the field.
I have been involved in organizing KDD workshops and conferences for 20 years – from 1989 to 2009, when I served as KDD Chair. This has been entirely a volunteer work, frequently time consuming and occasionally frustrating (like the time I had to deal with VAT tax issues for KDD-09 conference in Paris), but my reward has been in feeling that I was doing a useful work for the entire Data Science community. Now feel like a proud parent whose baby has grown and is completely independent, and very much enjoy not doing any organizing.
KJ: In Hindsight, what was one thing, which you would change in your journey?
Gregory: Use a shorter and simpler name for a website that is easier to spell than KDnuggets!
KJ: The analysts in industry can’t stop debating about SAS vs. R vs. Python? What is your take on it? What is your advice to newbies in the field?
Gregory: Python is certainly easier to learn and embed in other programs – you can see it was designed by a great programmer. R used to have a huge advantage in different statistical models and visualization , especially any packages made by Hadley Wickham, but Python is catching up, especially with scikit-learn and iPython.
SAS however is not going away and remains important in the industry .
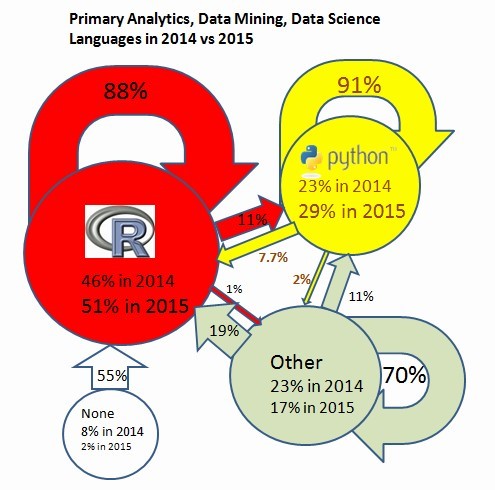
I have done a recent poll on this. Compared to 2013 poll results, the 2015 results show much higher stability, about 88% of R users in 2014 stayed with R and 91% stayed with Python. Percentage of primary R and primary Python users have grown, while percentage of users who chose Other or None have declined. You might find this helpful: Four main languages in analytics / data mining

KJ: Experts in industry are divided whether AI will evolve as a threat. What is your view on this?
Gregory: Just in the last few years we saw the amazing progress of AI and Machine Learning, especially Deep Learning. Google on smartphones now has better voice recognition than many humans and Deep Learning has exceeded human performance on many image recognition tasks. Some people claim that AI will never reach human level, but I remember that people were saying that AI will never beat a master in chess. Then it happened. Critics were saying AI will never beat a world champion in Chess, until IBM Deep Blue defeated Kasparov in 1997. So, predicting that AI will never be able to do X has consistently been a losing bet. I think it is inevitable that AI will reach or exceed human levels, but I hope not for the next 20-30 years.
My main concern is not that AI will want to exterminate people like in Terminator movies but that AI will automate and remove many jobs, leading to a much higher level of unemployment. This will cause huge upheavals and require massive social redistribution.
AI can also automate war – we already see armed drones. At the same time AI has a huge potential upside, for making life easier and better – just try to navigate a city without a GPS ! New personalized medicine will make lives better and longer.
My generation has essentially failed to deal with climate change.
Now it will be up to your generation to find the right balance of technology and social responsibility, and perhaps Data Science can help find better answers to world’s problems.
KJ: How do you think Analytics and Data Science would evolve in India as an industry and as a career option for people in the coming years? What parallels can we draw from the U.S. and other evolved markets?
Gregory: India has a huge number of talented people and I think Analytics and Data Science are an excellent career option for technically inclined young people. Indian is second only to US among KDnuggets readers.
KJ: I will ask for a personal advice as well – What would be your advice to me and what pearls of wisdom can you share with me to evolve Analytics Vidhya community further?
Gregory: I think you have done a great job already growing Analytics Vidhya, and I don’t think you need any advice from me. (but you may consider a name that is easier to remember for non-Indian readers 🙂
KJ: Thanks Gregory for taking time out of your busy schedule. I would like to thank you on behalf of our entire community and would hope that we would gain from your mentorship and guidance in future as well.
This was like a dream come true for me. I was always curious about Gregory’s journey, his perspective and what would be advice to some one like me. Not only this interview has helped me understand him as a person, but has motivated me to do a lot more than what I am doing.
It leaves me smiling as some one who just got a chance to meet and talk to his role model. I can’t thank Gregory enough for taking time out of his busy schedule.
P.S. We just announced our upcoming competition – The D Hack . Register to fight it out for the top spots against some of the best data scientists across the globe!
If you like what you just read & want to continue your analytics learning, subscribe to our emails, follow us on twitter or join our Facebook Group
Kunal Jain is the Founder and CEO of Analytics Vidhya, one of the world's leading communities of Al professionals. With over 17 years of experience in the field, Kunal has been instrumental in shaping the global Al landscape. His expertise spans diverse markets, from developed economies like the UK to emerging ones like India, where he has successfully led and delivered complex data-driven solutions. As a recognized thought leader, Kunal has empowered countless individuals to realize their Al ambitions through his visionary approach to Al education and community building. Before founding Analytics Vidhya, Kunal earned both his undergraduate and postgraduate degrees from IIT Bombay and held key roles at Capital One and Aviva Life Insurance across multiple geographies. His passion lies at the intersection of analytics, Al, and fostering a thriving community of data science professionals.




Very good one Kunal. Thank you.
Hi Kunal - Thanks for this insightful interview. I have a question for Gregory, if he can still answer: Referring back to the question related to AI, what do you think about automation of data science itself? When you say that the a lot of jobs will be lost to machines, do you think the same would apply to data science and data scientists themselves? If yes, what would you advice for people who have just started a career in data science. How can we prepare for the future?
Great interview, Kunal! Thanks for sharing