Introduction
I was catching up with one of my friends from a past organization. She had always been interested in data science, but was only able to break into it about 10 months ago. She had joined an organization as a data scientist and was clearly learning a lot in her (relatively) new role. Over our conversation, she mentioned a fact / question, which has stuck with me since then. She said that irrespective of how well she performs, she ends up doing every project / analysis multiple times before it is satisfactory for her manager. She also mentioned that these iterations cause her work to take lot more time than it should actually require in hindsight!
Does that sound familiar to you? Do you repeat your analysis multiple times before it becomes presentable and throws out answers to the required questions? Or you end up writing codes for similar activities again and again? If it does, you are at the right place. I’ll share a few ways in which you can increase your productivity and kill these unwanted iterations.
P.S. Don’t get me wrong here. I am not saying that iterations are bad in entirety. In fact, data science as a subject requires you to do things in iterations at times. But not all iterations are healthy and it is those unhealthy iterations we need to avoid. They will be the focus of this article.

What causes these iterations in analysis?
I am defining an iteration healthy / unhealthy using the following definition. Any iteration in analysis, which is happening due to any reason apart from flow of new information is an unhealthy iteration (there is one exception to this, which is mentioned below). Let me explain a few such scenarios:
- The business problem was not laid out correctly. The problem customer wanted to solve is different from the one you have been working on.
- Iteration because you need to collect more variables, which you did not think you will need upfront.
- Iteration because you did not think about the biases or the assumptions impacting your analysis.
On the other hand, if your iteration is happening because you built a model 6 months back and you now have new information, it is a healthy iteration. Another scenario for healthy iteration is when you deliberately start with simple models to develop better understanding and then build complex models.
Now, I am sure I have not covered all possible scenarios here, but I am sure these examples are good enough for you to judge whether an iteration in your analysis is healthy or unhealthy.
Impact of these productivity killers
Let’s get this clear – no one want’s unhealthy iterations and productivity killers in their analysis. Missing out on a few variables initially and then running the entire analysis again after collecting them would not interest any data scientist. Also, there is no fun in doing the same analysis again!
This productivity loss and iterations create frustation and dis-satisfaction among the analysts / data scientists and hence should be avoided at all costs.
Tips to avoid unhealthy iterations and increasing productivity
Tip 1: Focus on big problems (and big problems only):
I am sure every organization has a lot of small problems, which can be solved using data. But, they are not the best use of the data scientists. Focus on just those 3-4 problems, which can have huge impact on the organization. These problems would be challenging and would give you the maximum leverage for your analysis as well. You should not try to solve a smaller problem, if the bigger problem is unsolved.
This might sound trivial, but the number of organizations which make this mistake are non-trivial! I see banks working on marketing analytics when their risk scoring can be improved. Or insurance companies trying to build a reward program for agents, when their customer retention can be improved using analytics.
Tip 2: Create a presentation of your analysis before you start (with possible layouts and branches)
I do this all the time and I can’t tell how beneficial this is. The first thing you should do as soon as you start a project is to layout the presentation of your analysis. This might sound counter-intuitive to start with, but once you develop this habit, it can reduce your project turn around time to a fraction of what it takes otherwise.
So, what do you do?
You layout the story in form of a presentation / a word document or just a story on pen and paper. The actual form is immaterial. What is important is that you layout all possible outcomes at the start of the journey. For example, if you are looking to reduce the charge offs, a structure to lay out on your presentation would be something like this:
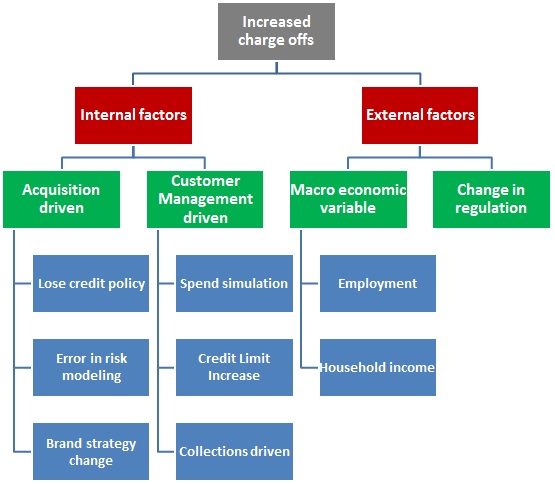
Next, you can take up each factor and define what do you need to see to conclude whether it has driven the increase in charge-off and how will you go about doing this? For example, if the charge-offs for the bank have increased because of increase in credit limit of customers, you would:
- First, need to ascertain that the customers who were not offered a credit limit increase did not worsen off in the charge offs.
- Next, put a mathematical equation trying to size the effect.
Once you have done this with every possible branch of your analysis, you have created a good starting point for yourself.
Tip 3: Define data requirements upfront:
This flows from the last step directly. If you have laid out the analysis comprehensively, you would know the data requirements by the end of it. Here are a few tips to help you out:
- Try and put a structure to your data requirement: Instead of putting down a list of variables, you should design the tables you would want for your analysis. In the case above (increased charge offs), you will need a customer demographic table, a table for past marketing campaigns, transactions done by customers for last 12 months, credit policy changes for the bank etc.
- Collect all the data you might need: Even if you are not 100% sure, whether you will need all the variables in the data set, you should go ahead and collect them at this stage. Normally, it is very little incremental work to include additional variables at this stage, rather than re-asking for variables to be collected at a later point in the analysis.
- Define the time period of the data you are interested in
Tip 4: Make sure your analysis is reproducible:
Again, this might sound as a simple tip – but you see both the beginners as well as the advanced people falter on it. The beginners would perform steps in excel, which would include copy paste of data. For the advanced users, any work done through command line interface might not be reproducible.
Similarly, you need to extra cautious while working with notebooks. You should control your urge to go back and change any previous step which uses the data set which has been computed later in the flow. Notebooks can be very powerful, if the flow is maintained. If the flow is not maintained, they can be very tardy as well.
Tip 5: Keep standard libraries of codes ready and accessible:
There is no point in re-writing codes for simple operations again and again. Not only it takes extra time, but it might lead to possible syntax errors. Another tip to make the most of this is to create a library of these common operations and share it across your entire team.
This will not only make sure the entire team uses the same code, but also make them more efficient.
Tip 6: Similarly, keep a library of intermediate datamarts:
A lot of times, you need same piece of information again and again. For example, you will need total customer spend on a credit card for several analysis and reporting. While you can calculate it every time you need from the transaction tables, it is much better to again create intermediate datamarts of these tables to save time and efforts spent in creating these tables. Similarly, think of summary tables for marketing campaigns. There is no point in re-inventing the wheels every time.
Tip 7: Always use an holdout sample / cross-validation to avoid over-fitting
A lot of beginners under-estimate the power of holdout or cross-validation. A lot of tend to believe that if train is sufficiently large, there are hardly / no chances of over-fitting and hence a cross-validation or holdout sample is not required.
More often that not, this turns out to be blooper in the end. Don’t believe me – check out Kaggle public and private leader boards for any competition. You will always find a few entries in top 10 who end up dropping their ranks as they ended up overfitting their solutions. And you would hope these to be more advanced data scientists.
Tip 8: Work in chunks and take breaks regularly:
When do I work the best? It’s when I provide myself a 2-3 hours window to work on a problem / project. You can’t multi-task as a data scientist. You need to be focuses on a single problem at a time to make sure you get the best out of yourself. 2-3 hour chunks work best for me, but you can decide yours.
End Notes:
So, those were some productivity hacks I use for increasing my productivity. I can’t emphasize the importance of getting things right the first time enough. You have to get into a habit of getting it right every time – that is what will make you an awesome data scientist.
Do you have any tips which makes you more productive? If yes, share it with us in comments below.
If you like what you just read & want to continue your analytics learning, subscribe to our emails, follow us on twitter or like our facebook page.
Kunal Jain is the Founder and CEO of Analytics Vidhya, one of the world's leading communities of Al professionals. With over 17 years of experience in the field, Kunal has been instrumental in shaping the global Al landscape. His expertise spans diverse markets, from developed economies like the UK to emerging ones like India, where he has successfully led and delivered complex data-driven solutions. As a recognized thought leader, Kunal has empowered countless individuals to realize their Al ambitions through his visionary approach to Al education and community building. Before founding Analytics Vidhya, Kunal earned both his undergraduate and postgraduate degrees from IIT Bombay and held key roles at Capital One and Aviva Life Insurance across multiple geographies. His passion lies at the intersection of analytics, Al, and fostering a thriving community of data science professionals.






Nice one. As a peer reviewer, I can say this is a very important and interesting point. Iteration in model takes much longer than expected, and in the end either peer reviewer or modeler lost their patients, hardly we achieve 100% agreement. I think this is because of where people put more focus. I have noticed beginners put more focus on statistics where as experienced put focus on business knowledge and big pictures. It works best if both the parties are open to ideas and learn from each other.