This article was published as a part of the Data Science Blogathon.
Introduction:
In the real world, the data we gather will be heavily imbalanced most of the time. so, what is an Imbalanced Dataset?. The training samples are not equally distributed across the target classes. For instance, if we take the case of the personal loan classification problem, it is effortless to get the ‘not approved’ data, in contrast to, ‘approved’ details. As a result, the model is more biased to the class which has a large number of training instances which degrades the model’s prediction power.
It also results in an increase in Type II errors, in the case of a typical binary classification problem. This stumbling block is not just limited to machine learning models but can also be predominantly observed in computer vision and NLP machine learning areas as well. These hiccups could be handled effectively by using distinct techniques for each area respectively.
Notes: This article will give a brief overview of various data augmentation methods available without going deep into the technical details. All the images displayed here are taken from Kaggle.
Table of Contents
- Machine Learning – Imbalanced Data(upsampling & downsampling)
- Computer Vision – Imbalanced Data(Image data augmentation)
- NLP – Imbalanced Data(Google trans & class weights)
(1). Machine Learning – Imbalanced Data:
The main two methods that are used to tackle the class imbalance is upsampling/oversampling and downsampling/undersampling. The sampling process is applied only to the training set and no changes are made to the validation and testing data. Imblearn library in python comes in handy to achieve the data resampling.
Upsampling is a procedure where synthetically generated data points (corresponding to minority class) are injected into the dataset. After this process, the counts of both labels are almost the same. This equalization procedure prevents the model from inclining towards the majority class. Furthermore, the interaction(boundary line)between the target classes remains unaltered. And also, the upsampling mechanism introduces bias into the system because of the additional information.
we can take Analytics Vidhya’s loan prediction problem to explain the steps. The training dataset used here can be found in the hackathon link.
All the mentioned below codes can be completely found in the GitHub repository.
SMOTE(SyntheticMinorityOversamplingTechnique) — upsampling:-
It works based on the KNearestNeighbours algorithm, synthetically generating data points that fall in the proximity of the already existing outnumbered group. The input records should not contain any null values when applying this approach.
#import imblearn library from imblearn.over_sampling import SMOTENC oversample = SMOTENC(categorical_features=[0,1,2,3,4,9,10], random_state = 100) X, y = oversample.fit_resample(X, y)
DataDuplication — upsampling:- In this approach, the existing data points corresponding to the outvoted labels are randomly selected and duplicated.
from sklearn.utils import resample
maxcount = 332
train_nonnull_resampled = train_nonnull[0:0]
for grp in train_nonnull['Loan_Status'].unique():
GrpDF = train_nonnull[train_nonnull['Loan_Status'] == grp]
resampled = resample(GrpDF, replace=True, n_samples=int(maxcount), random_state=123)
train_nonnull_resampled = train_nonnull_resampled.append(resampled)
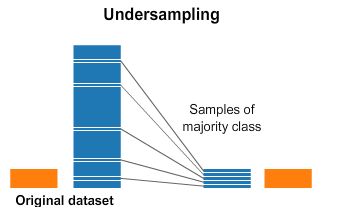
Downsampling is a mechanism that reduces the count of training samples falling under the majority class. As it helps to even up the counts of target categories. By removing the collected data, we tend to lose so much valuable information.
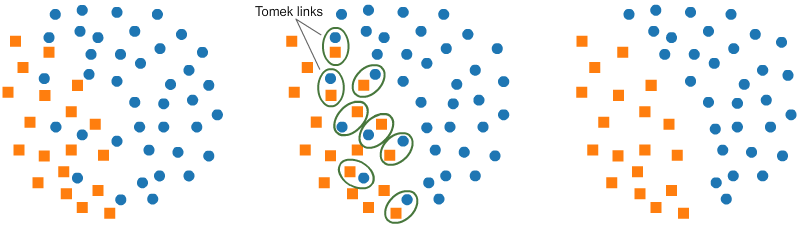
Tomek(T-Links):-
T-Link is basically a pair of data points from different classes(nearest-neighbors). The objective is to drop the sample that corresponds to the
majority and thereby minimalizing the count of the dominating label. This also increases the borderspace between the two labels and thus improving the performance accuracy.
from imblearn.under_sampling import TomekLinks undersample = TomekLinks() X, y = undersample.fit_resample(X, y)
Centroid
Based:- The algorithm tries to find the homogenous clusters in the majority class and retains only the centroid. This would reduce the lion’s share of the majority label. It leverages the logic used in the KMeans clustering. But a lot of useful information is wasted.
(2). Computer Vision – Imbalanced Data:
For unstructured data such as images and text inputs, the above balancing techniques will not be effective. In the case of computer vision, the input to the model is a tensor representation of the pixels present in the image. So just randomly altering the pixel values (in order to add more input records) can completely change the meaning of the picture itself. There is a concept called data augmentation where an image undergoes a lot of transformation but still keeping the meaning intact.
The various image transformations include scaling, cropping, flipping, padding, rotation, Brightness, contrast, and saturation level changes. By doing so, with just a single image, a humongous image dataset can be created.
Let’s take the computer vision hackathon posted in Analyticsvidhya and the dataset used can be found here. The requirement is to classify vehicles into emergency and non-emergency categories. For illustration purposes, the image ‘0.jpg’ is considered.

from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
img = load_img('images/0.jpg')
x = img_to_array(img)
x = x.reshape((1,) + x.shape)
print(x.shape)
# the .flow() command below generates batches of randomly transformed images
# and saves the results to the `preview/` directory
i = 0
for batch in datagen.flow(x, batch_size=1,
save_to_dir='preview', save_prefix='vehichle', save_format='jpeg'):
i += 1
if i > 19:
break # otherwise the generator would loop indefinitely
The entire code along with a pre-trained model can be found in the GitHub repository.
The link can be referred to for the detailed usage of the ImageDataGenerator.
(3). NLP – Imbalanced Data:
Natural Language processing models deal with sequential data such as text, moving images where the current data has time dependency with the previous ones. Since text inputs fall under the category of unstructured data, we handle such scenarios differently. For example, if take a ticket classification language model, where an IT ticket has to be assigned to various groups based on the sequence of words present in the input text.
Google Translation(google trans python package): This is one of the useful techniques to expand the count of minority groups. Here, we translate the given sentence to ‘non-English’ language and then again translating to ‘English’. In this way, the significant details of the input message are maintained but the order of words / sometimes new words with similar meaning are introduced as a new record and thus boosting the count of insufficient class.
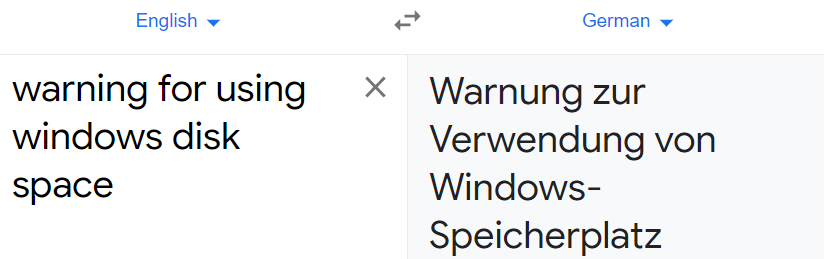
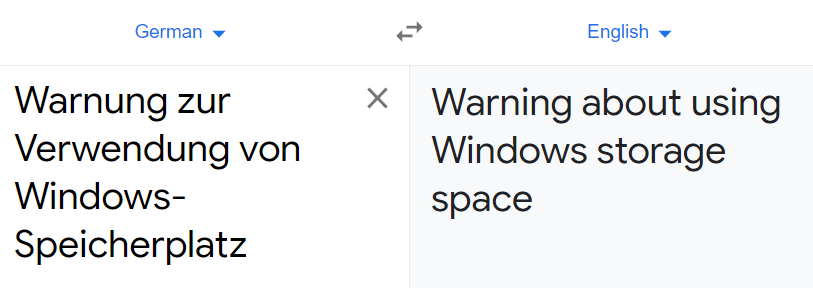
Input text – “warning for using windows disk space”
Data Augmented text – “Warning about using Windows storage space”
Even though the meaning of the above sentence is the same, there are new words introduced and thus it enhances the learning ability of a language model by expanding the input sample count.
The below-executed code can be found in the GitHub repository. This example includes just only one non-English code. There are many of them and the entire list of language codes that can be used in the google trans can be found here.
from googletrans import Translatortranslator = Translator()
def German_translation(x): print(x) german_translation = translator.translate(x, dest='de') return german_translation.text
def English_translation(x): print(x)
english_translation = translator.translate(x, dest='en') return english_translation.text
x = German_translation("warning for using windows disk space")
English_translation(x)
Class weights: The second option is to leverage the class weights parameter during the fit model process. For each class in the target, a weightage is assigned. The minority class will get more weightage when compared to the majority ones. As a result, during the backpropagation, more loss value is associated with the minority class and the model will give equal attention to all the classes present in the output.
import numpy as np
from tensorflow import keras
from sklearn.utils.class_weight import compute_class_weight
y_integers = np.argmax(raw_y_train, axis=1)
class_weights = compute_class_weight('balanced', np.unique(y_integers), y_integers)
d_class_weights = dict(enumerate(class_weights))
history = model.fit(input_final, raw_y_train, batch_size=32, class_weight = d_class_weights, epochs=8,callbacks=[checkpoint,reduceLoss],validation_data =(val_final, raw_y_val), verbose=1)
This option is also available in machine learning classifiers such as ‘SVM’ where we give class_weight = ‘balanced’.
# fit the training dataset on the classifier SVM = svm.SVC(C=1.0, kernel='linear', degree=3, gamma='auto', class_weight='balanced', random_state=100)
The entire python code using class weights can be found in the GitHub link.
Conclusion
So far we have discussed various methods to handle imbalanced data in different areas such as machine learning, computer vision, and NLP. Even though these approaches are just starters to address the majority Vs minority target class problem. There are other advanced techniques that can be further explored. Please refer to this article for additional insights about handling disproportionate datasets.






