Introduction
There’s a lot of talk about Business Analytics in today’s corporate world. But why is it so? Is it just another trend that people will forget soon? Well, this article aims to talk about major business analytics tools and then substantiate the stance of the corporate world.
Be approximately right rather than exactly wrong.
As rightly said by John turkey, “Be approximately right rather than exactly wrong”. He was an American mathematician best known for the development of the Fast Fourier Transform algorithm and box plot.
This Quote helps in understanding the need for Analysis in today’s corporate world. The analysis is very important as it helps in understanding the future.
Let me explain this with a real-time case: –

Abstract: The dataset summarizes a heterogeneous set of features about articles published by Mashable in a period of two years (Mashable’s primary focus is on technology, lifestyle, and entertainment news. Website: www.mashable.com)
Case: Please carry out an Exploratory Data Analysis and create a compelling story based on the given dataset; also predict which Article will be more popular in the near future.
I have done the Analysis using:

1. R Studio:
It is an integrated development environment for R, a programming language for statistical computing and graphics. It is open-source software (Click here to download).
2. SPSS:
SPSS Statistics is a software package used for interactive, or batched, statistical analysis; IBM acquired it in 2009. (Click here to download).
3. Power BI:
Power BI is a business analytics service by Microsoft. It aims to provide interactive visualizations and business intelligence capabilities with an interface simple enough for end-users to create their reports and dashboards. (Click here to download).
4. Excel:
Microsoft Excel is a spreadsheet developed by Microsoft for Windows, macOS, Android, and iOS. It features calculation, graphing tools, pivot tables, and a macro programming language called Visual Basic for Applications. (Click here to download).
5. Orange:
Orange is an open-source data visualization, machine learning, and data mining toolkit. It features a visual programming front-end for explorative rapid qualitative data analysis and interactive data visualization. (Click here to download).
Let’s get started with Exploratory Analysis:

Exploratory Analysis is an approach to analyze data sets to summarise their main characteristics, often with visual methods. A statistical model can be used, but primarily exploratory Analysis is done for seeing what the data can tell us beyond the formal modeling or hypothesis testing task.
Exploratory Analysis is a vast term; it includes:
# Variable Identification
# Univariate Analysis
# Bi-variate Analysis
# Missing values treatment
# Outlier treatment
# Variable transformation
# Variable creation
1st STAGE:

VARIABLE IDENTIFICATION
The First Step in Variable Identification is to identify the target (output) variables.

The second step is to identify the type of data (Like — Categorical, Numerical, Ration, etc.).
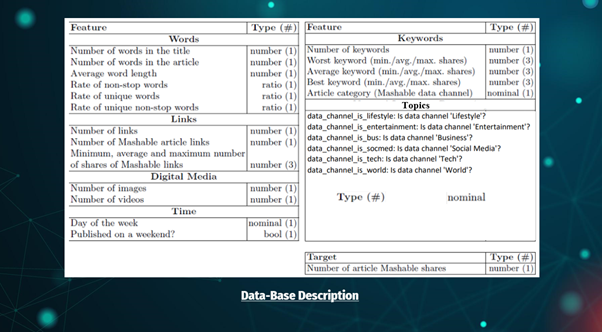
Attribute Information:
1. url: URL of the article (non-predictive)
2. n_tokens_title: Number of words in the title
3. n_tokens_content: Number of words in the content
4. n_unique_tokens: Rate of unique words in the content
5. n_non_stop_words: Rate of non-stop words in the content
6. n_non_stop_unique_tokens: Rate of unique non-stop words in the content
7. num_hrefs: Number of links
8. num_imgs: Number of images
9. num_videos: Number of videos
10. average_token_length: Average length of the words in the content
11. num_keywords: Number of keywords in the metadata
12. data_channel_is_lifestyle: Is data channel ‘Lifestyle’?
13. data_channel_is_entertainment: Is the data channel ‘Entertainment’?
14. data_channel_is_bus: Is the data channel ‘Business’?
15. data_channel_is_socmed: Is the data channel ‘Social Media’?
16. data_channel_is_tech: Is the data channel ‘Tech’?
17. data_channel_is_world: Is the data channel ‘World’?
18. weekday_is_monday: Was the article published on a Monday?
19. weekday_is_tuesday: Was the article published on a Tuesday?
20. weekday_is_wednesday: Was the article published on a Wednesday?
21. weekday_is_thursday: Was the article published on a Thursday?
22. weekday_is_friday: Was the article published on a Friday?
23. weekday_is_saturday: Was the article published on a Saturday?
24. weekday_is_sunday: Was the article published on a Sunday?
25. is_weekend: Was the article published on the weekend?
26. shares: Number of shares (TARGET)

So, now we are done with VARIABLE IDENTIFICATION and will proceed with UNI-VARIATE & BI-VARIATE ANALYSIS.
2nd STAGE:

A. UNI_VARIATE ANALYSIS:
Uni-Variate Analysis helps in exploring variables one by one. Method to perform uni-variate Analysis will depend on whether the variable type is categorical or continuous.
B. BI-VARIATE ANALYSIS:
Bi-variate Analysis helps in finding out the relationship between those variables. Bi-variate Analysis can be performed for any combination of categorical and continuous variables. The combination could be Categorical & Categorical, Categorical & Continuous, and Continuous & Continuous. Different methods are used to tackle these combinations during the analysis process.
I have done these analyses by visualizing the Data as:
A PICTURE ALWAYS REINFORCES THE CONCEPT.
To analyze, there should be a common base. For this, the Median Value was taken as a base value from the share’s column. And two new columns were added.

Two new columns were named POPULARITY (one is the Categorical column and the other is the Numerical column).

All the shares, which have a value less than or equal to 1500, are considered as Un-Popular and vice versa.
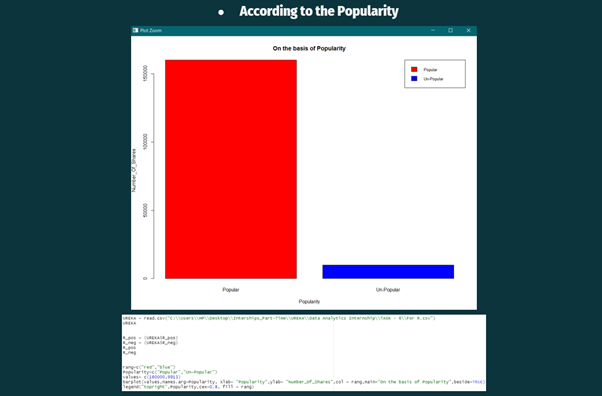
In the above Visualisation, it can be observed that the articles published by Mashable in the past two-years were popular among people.
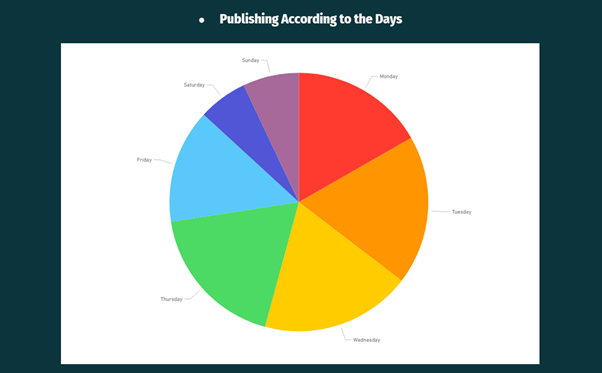
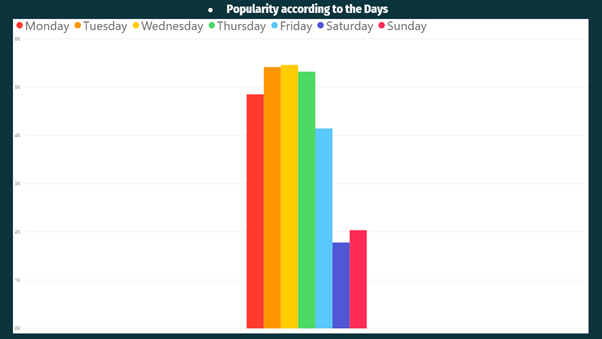
In the above two visualizations (publishing according to the days & popularity according to the days), it can be observed that Mashable usually publish fewer articles on weekends as people don’t like to read more articles on weekends the reason can be any — Maybe people will get only Saturday and Sunday as holidays, and they might want to relax or travel instead of reading articles.

Now, the popularity has been compared with the different themes (Analysis is based on the Data of past two-years):
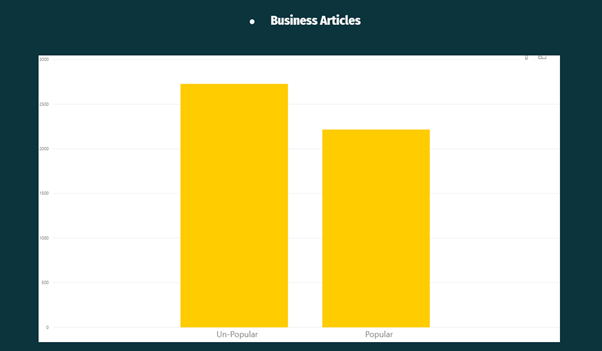
From the above Visualisation, it can be observed that Business Articles were less popular on the Mashable website.
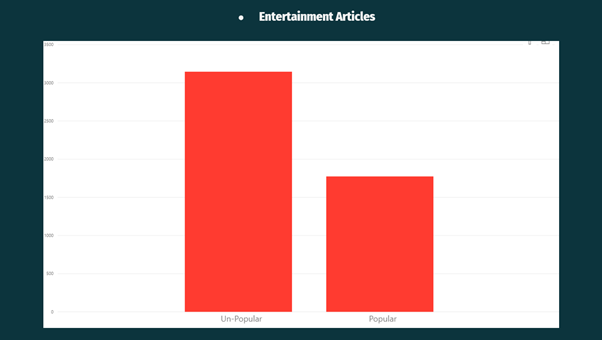
From the above Visualisation, it can be observed that Entertainment Articles are were less popular on the Mashable website.
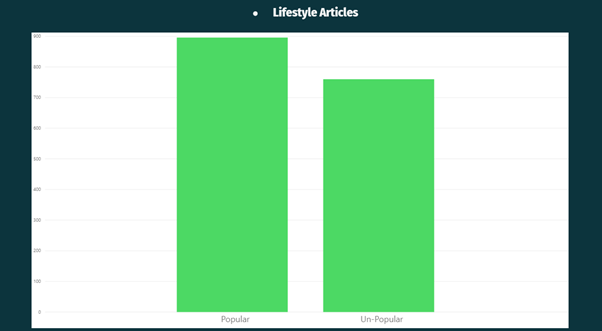
From the above Visualisation, it can be observed that Lifestyle Articles were more popular on the Mashable website.
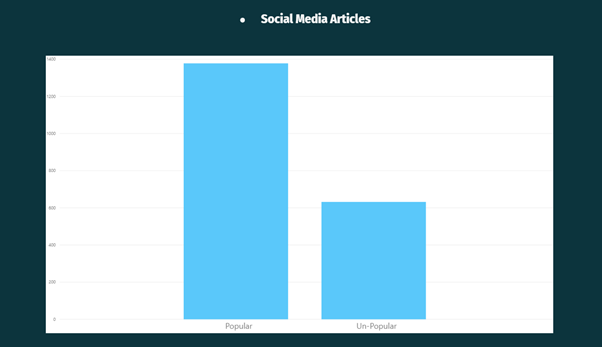
From the above Visualisation, it can be observed that Social Media Articles were more popular on the Mashable website.
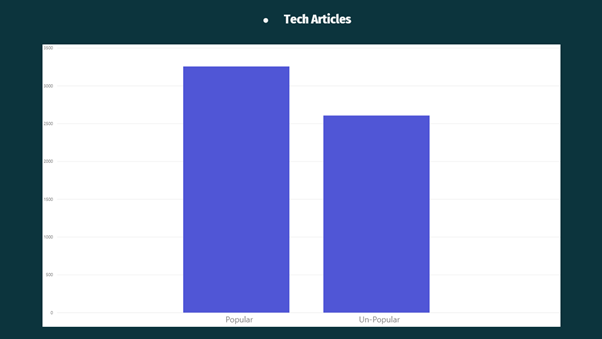
From the above Visualisation, it can be observed that Techy Articles were more popular on the Mashable website.
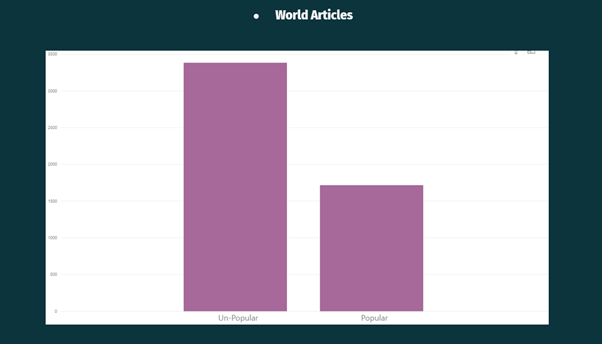
From the above Visualisation, it can be observed that World Articles were less popular on the Mashable website.
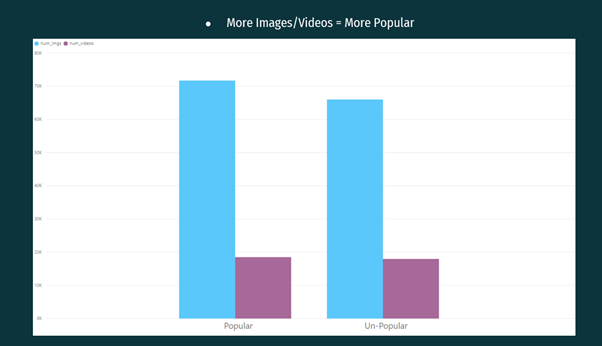
From the above Visualisation, it can be observed that the Articles having more images and videos were more popular as compared to the articles having fewer images and videos.
Content is also a major factor on which popularity depends
It can be in any form like — unique, short or long, etc.
So, to analyze CONTENT, we again need to have a common base.
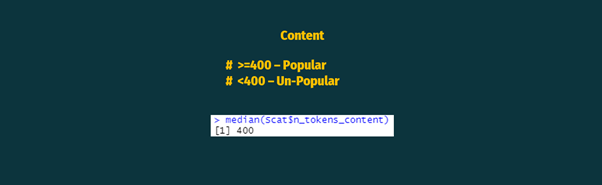
Again, the median value was taken as a common base and marked as:
Content less than or equal to 400 words as popular and vice versa.
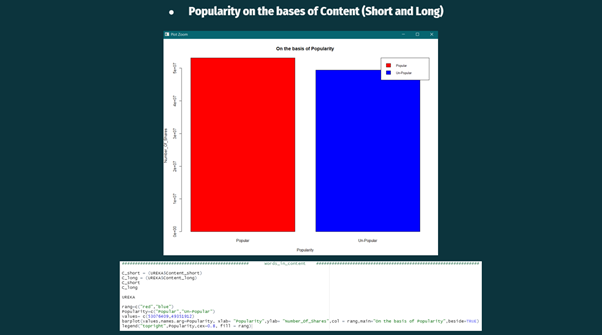
From the above visualization, it can be observed that the short articles were more popular than the long articles.
So, now we are done with VARIABLE IDENTIFICATION, UNI-VARIATE & BI-VARIATE ANALYSIS and will proceed for MISSING VALUE TREATMENT (if any).
3rd STAGE:

MISSING VALUES
Now, there is a need to find the missing values and rectify them (if any).
Missing data can be treated in 4 ways:
a. Deletion
b. Mean/Median/Mode
c. Predictive Modelling
d. KNN
The Data has been checked using the DATA TABLE TOOL (Orange Data Mining software).
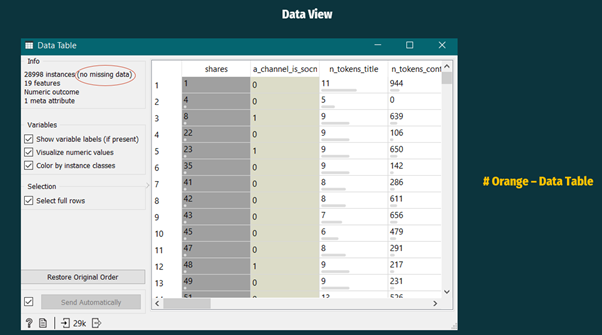
And it can be seen that the Data does not have any MISSING VALUES. Hence, we can skip this STAGE.
So, now we are done with VARIABLE IDENTIFICATION, UNI-VARIATE & BI-VARIATE ANALYSIS, MISSING VALUE TREATMENT and will proceed for OUTLIER TREATMENT (if any).
4th STAGE:

OUTLIERS were checked using BOX-PLOT and SCATTER-PLOT (R Studio). It was observed that there were a few OUTLIERS. The OUTLIERS were rectified by deleting them.
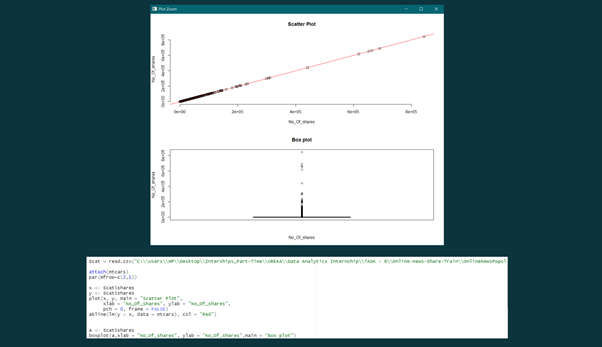
And again, BOX — PLOT & SCATTER — PLOT was used to check the OUTLIERS. Now, we don’t have any OUTLIER.
So, now we are done with VARIABLE IDENTIFICATION, UNI-VARIATE & BI-VARIATE ANALYSIS, MISSING VALUE TREATMENT, OUTLIERS, and will proceed for VARIABLE TRANSFORMATION & VARIABLE CREATION.
5th STAGE:

The final stage is to predict which article will be more popular in the near future. But for now, let’s check for any one of the articles.
Chosen Article — Social Media
(Social Media Article was randomly chosen).
For this, four different models were selected:
1. Decision Tree:
A Decision Tree is used to comprehend & predict both numerical values and categorical value problems. But there is a drawback that it generally results in overfitting of the data/information. Yet, we can dodge the over fittings by utilizing a pre-pruning approach, for instance, creating a tree with fewer leaves and branches.
2. Stochastic Gradient Descent:
The Stochastic Gradient Descent minimizes a chosen loss function with a linear function. The algorithm approximates a true gradient by considering one sample at a time and simultaneously updates the model based on the gradient of the loss function. For regression, it returns predictors as minimizers of the sum, i.e., M-estimators, and is especially useful for large-scale and sparse datasets.
3. Random Forest:
Random Forest is a tree-based learning algorithm with the power to form accurate decisions as it many decision trees together. As its name says — it’s a forest of trees. Hence, Random Forest takes more training time than a single decision tree. Each branch and leaf within the decision tree works on the random features to predict the output. Then this algorithm combines all the predictions of individual decision trees to generate the final prediction, and it can also deal with the missing values.
4. Artificial Neural Network:
ANN is like our brain; millions and billions of cells — called neurons, which processes information in the form of electric signals. Similarly, in ANN, the network structure has an input layer, a hidden layer, and the output layer. It is also called Multi-Layer Perceptron as it has multiple layers. The hidden layer is known as a “distillation layer” that distills some critical patterns from the data/information and passes it onto the next layer. It then makes the network quicker and more productive by distinguishing the data from the data sources, leaving out the excess data.
- It captures a non-linear relationship between the inputs.
- It helps in converting the information/data into more useful insight.
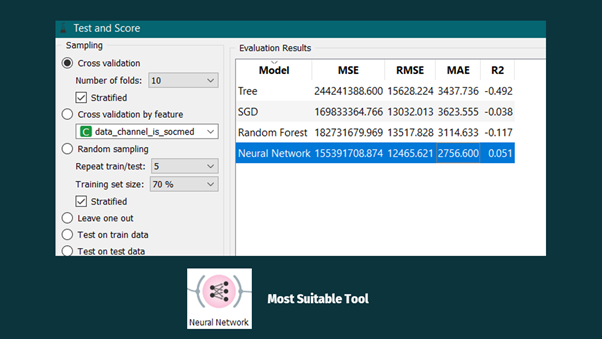
From the above image, it can be observed that the Artificial Neural Network has the lowest Mean Square Error.
So, this value is taken for further calculations.
Further calculations were done using SPSS-
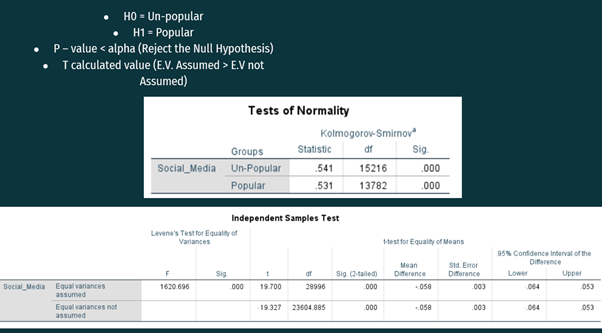
H0 = Un-popularity
H1 = Popularity
In the Test of Normality Table, it can be seen that the significance level is less than alpha, i.e., 0.05. Alpha is a universal value. So, the null hypothesis can be rejected, and it can be concluded that the Social media article will be more prevalent soon.
But, for a Deep Analysis. Independent Samples T-test is used:
In the second table, it can be observed that:
In Levene’s Test for Equality of Variances column, the significance Level is less than the alpha value, so, the hypothesis of Levene’s Test can be rejected.
Now, we will look at the T-test for equality of means and corresponding Confidence Interval.
In the T calculated value, we can see that equal variances not assumed has lesser value than equal variance assumed. Hence, there is a slight risk that social media articles will get unpopular in the near future.
From the confidence Interval column, we can see that there is a 0.058% (Average of Upper Bond C.I and Lower Bond C.I) chance that social media articles will get unpopular.
The chances are significantly less, but still, Mashable needs to take some precautions:
Below mentioned are some SUGGESTIONS to reduce the risk:

INCREASE
# Number of embedded links.
# Number of images.
# Number of videos.
# Amount of subjectivity in content.
# Number of more popular words.
DECREASE
# Number of longer words in the content.
# Amount of multi-topic discussion in an article as it can confuse.
# Number of negative words as it can lead to controversies.
From the above case, it can be seen that there is a need for Analysis in today’s corporate world. And it is not a trend that will be vanished in some time; in fact, it is a feeling which helps in growing and developing the corporate world.
“The greatest power of analysis is when it forces you to notice what you never expected and helps you growing.”
Personally, I enjoyed writing this article and would love to learn from your feedback.
Contacts
In case you have any questions or any suggestions on what my next article should be about, please leave a comment below or mail me at [email protected].
If you want to keep updated with my latest articles and projects, follow me on Medium.
Connect with me via:



