Overview:
Assume the job of a Data Engineer, extracting data from multiple sources of file formats, transforming it into particular data types, and loading it into a single source for analysis. Soon After reading this article, With the aid of several practical examples, you will be able to put your skills to the test by implementing web scraping and extracting data with APIs. With Python and data engineering, you’ll be able to start gathering huge datasets from many sources and transforming them into a single primary source or start web scraping for useful business insights.
This article was published as a part of the Data Science Blogathon

Synopsis:
- Why data engineering is more reliable?
- Process of the ETL cycle
- Step by step Extract, Transform, the Load function
- About Data engineering
- About myself
- Conclusion
Why data engineering is more reliable?
It is a more reliable and fastest-growing tech occupation in the current generation, as it concentrates more on web scraping and crawling datasets.
Process(ETL cycle):
Have you ever wondered how data from many sources were integrated to create a single source of information? Batch processing is a sort of collecting data and learn more about “how to explore a type of batch processing” called Extract, Transform, and Load.
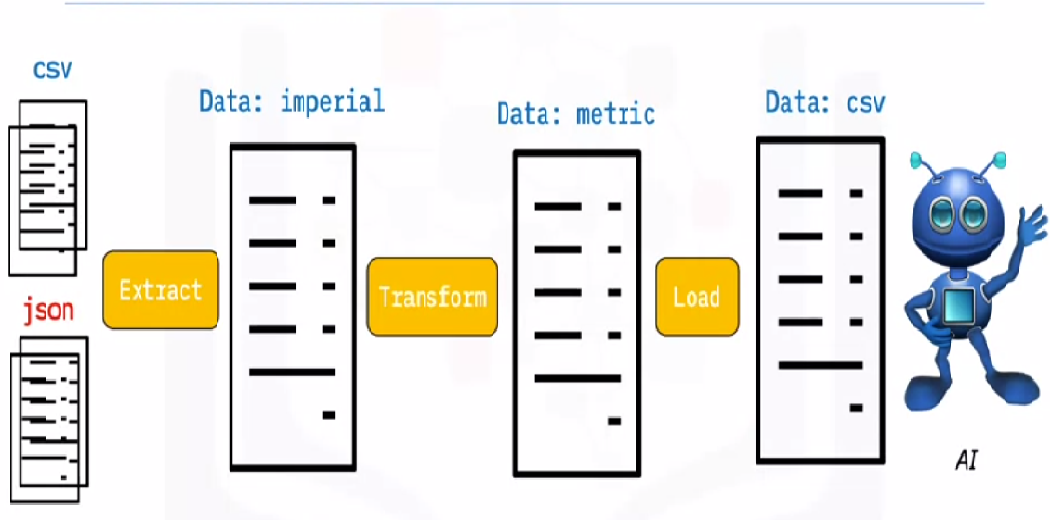
ETL is the process of extracting huge volumes of data from a variety of sources and formats and converting it to a single format before putting it into a database or destination file.
Some of your data is stored in CSV files, while others are stored in JSON files. You must gather all of this information into a single file for the AI to read. Because your data is in imperial units, but the AI needs metric units, you’ll need to convert it. Because the AI can only read CSV data in a single large file, you must first load it. If the data is in CSV format, let’s put the following ETL with python and have a look at the extraction step with some easy examples.
By looking at the list of.json and.csv files. The glob file extension is preceded by a star and a dot in the input. A list of.csv files are returned. For.json files, we can do the same thing. We may create a file that extracts names, heights, and weights in CSV format. The file name of the.csv file is the input, and the output is a data frame. For JSON formats, we can do the same thing.

Step 1:
Open the notebook and Import the functions and required modules
import glob
import pandas as pd
import xml.etree.ElementTree as ET
from datetime import datetimeData used:
The files dealership_data contain CSV, JSON, and XML files for used car data which contain features named car_model, year_of_manufacture, price, and fuel. So we are going to extract the file from the raw data and transform it into a target file and load it in the output.
Download the source file from the cloud:
!wget https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-PY0221EN-SkillsNetwork/labs/module%206/Lab%20-%20Extract%20Transform%20Load/data/datasource.zipExtract the zip file:
nzip datasource.zip -d dealership_dataSet the path for the target files:
tmpfile = "dealership_temp.tmp" # store all extracted data
logfile = "dealership_logfile.txt" # all event logs will be stored
targetfile = "dealership_transformed_data.csv" # transformed data is stored
Step 2 (EXTRACT):
The Function extract will extract large amounts of data from multiple sources in batches. By adding this function, it will now discover and load all the CSV file names, and the CSV files will be added to the date frame with each iteration of the loop, with the first iteration being attached first, followed by the second iteration, resulting in a list of extracted data. After we’ve gathered the data, we’ll go on to the “Transform” step of the process.
Note: If the “ignore index” is set to true, the order of each row will be the same as the order in which the rows were appended to the data frame.
CSV Extract Function
def extract_from_csv(file_to_process):
dataframe = pd.read_csv(file_to_process)
return dataframeJSON Extract Function
def extract_from_json(file_to_process):
dataframe = pd.read_json(file_to_process,lines=True)
return dataframeXML Extract Function
def extract_from_xml(file_to_process):
dataframe = pd.DataFrame(columns=['car_model','year_of_manufacture','price', 'fuel'])
tree = ET.parse(file_to_process)
root = tree.getroot()
for person in root:
car_model = person.find("car_model").text
year_of_manufacture = int(person.find("year_of_manufacture").text)
price = float(person.find("price").text)
fuel = person.find("fuel").text
dataframe = dataframe.append({"car_model":car_model, "year_of_manufacture":year_of_manufacture, "price":price, "fuel":fuel}, ignore_index=True)
return dataframeExtract function():
Now call the extract function using its function call for CSV , JSON , XML.
def extract():
extracted_data = pd.DataFrame(columns=['car_model','year_of_manufacture','price', 'fuel'])
#for csv files
for csvfile in glob.glob("dealership_data/*.csv"):
extracted_data = extracted_data.append(extract_from_csv(csvfile), ignore_index=True)
#for json files
for jsonfile in glob.glob("dealership_data/*.json"):
extracted_data = extracted_data.append(extract_from_json(jsonfile), ignore_index=True)
#for xml files
for xmlfile in glob.glob("dealership_data/*.xml"):
extracted_data = extracted_data.append(extract_from_xml(xmlfile), ignore_index=True)
return extracted_dataStep 3(Transform):
After we’ve gathered the data, we’ll go on to the “Transform” phase of the process. This function will convert the column height, which is in inches, to millimeters and the column pounds, which is in pounds, to kilogram, and return the results in the variable data. In the input data frame, the column height is in feet. Convert the column to convert it to meters and round it to two decimal places.
def transform(data):
data['price'] = round(data.price, 2)
return dataStep 4(Loading and Logging):
It’s time to load the data into the target file now that we’ve gathered and specified it. We save the pandas data frame as a CSV in this scenario. We’ve now gone through the steps of extracting, transforming, and loading data from various sources into a single target file. We need to establish a logging entry before we can finish our work. We’ll achieve this by writing a logging function.
Load function:
def load(targetfile,data_to_load):
data_to_load.to_csv(targetfile)Log function:
All the data are written will be appended to the current information when the “a” is added. We can then attach a timestamp to each phase of the process, indicating when it starts and when it finishes, by generating this type of entry. After we’ve defined all the code required to perform the ETL process on the data, the last step is to call all the functions.
def log(message):
timestamp_format = '%H:%M:%S-%h-%d-%Y'
#Hour-Minute-Second-MonthName-Day-Year
now = datetime.now() # get current timestamp
timestamp = now.strftime(timestamp_format)
with open("dealership_logfile.txt","a") as f: f.write(timestamp + ',' + message + 'n')Step 5(Running ETL Process):
We first start by calling the extract_data function. We receive data from this step and then transfer it to the second step for transforming the data. After completing this, we load the data into the target file. Also, note that we add the start and completion time and date before and after every step.
The log that you have started the ETL process:
log("ETL Job Started")The log that you have started and ended the Extract step:
log("Extract phase Started")
extracted_data = extract()
log("Extract phase Ended")You have started and ended the Transform Step:
log("Transform phase Started")
transformed_data = transform(extracted_data)
log("Transform phase Ended")You have started and ended the Load phase:
log("Load phase Started")
load(targetfile,transformed_data)
log("Load phase Ended")ETL Cycle is ended:
log("ETL Job Ended")By this process, we discussed some basic extract, transform and load function
- How to write a simple Extract function.
- How to write a simple Transform function.
- How to write a simple Load function.
- How to write a simple logging function.
“Without big data, you are blind and deaf and in the middle of a freeway.” – Geoffrey Moore.
At most, we have discussed all the ETL processes. Further, let’s see, ” what are the benefits of the data engineer job?”.
About Data Engineering:
Data engineering is a vast field with many names. It may not even have a formal title in many institutions. As a result, it’s generally better to start by defining the aims of data engineering work that lead to the expected outputs. The users who rely on data engineers are as diverse as the data engineering teams’ talents and results. Your consumers will always define what issues you handle and how you solve them, regardless of what sector you pursue.
About Myself:
Hello, my name is Lavanya, and I’m from Chennai. I am a passionate writer and enthusiastic content maker. The most difficult problems always thrill me. I am currently pursuing my B. Tech in Chemical Engineering and have a strong interest in the fields of data engineering, machine learning, data science, and artificial intelligence, and I am constantly looking for ways to integrate these fields with other disciplines such as science and chemistry to further my research goals.
Conclusion:
I hope you enjoyed my article and gained an understanding of what Python is all about in a nutshell, which will provide you with some direction as you begin your journey to learn data engineering. This is only the tip of the iceberg in terms of possibilities. There are many more sophisticated topics in data engineering, for instance, to learn. However, before we can grasp such notions, I will be elaborating in the next article. Thank You!
Analytics Vidhya does not own the media shown in this article; instead, the authors use them at their discretion.
Hello, my name is Lavanya, and I’m from Chennai. I am a passionate writer and enthusiastic content maker. The most intractable problems always thrill me. I am currently pursuing my B. Tech in Computer Engineering and have a strong interest in the fields of data engineering, machine learning, data science, and artificial intelligence, and I am constantly looking for ways to integrate these fields with other disciplines such as science and computer to take further my research goals.







Very excellent work
Awesome dude
Wonderful, Marvelous, Excellent !!!