This article was published as a part of the Data Science Blogathon.
A centralized location for research and production teams to govern models and experiments by storing metadata throughout the ML model lifecycle.

Introduction
When working on a machine learning project, it’s one thing to receive impressive results from a single model-training run. Keeping track of all of your machine learning attempts, on the other hand, is another; having a framework in place that allows you to draw reliable conclusions from them is something else entirely.
Experiment tracking is the solution to these problems. Experiment tracking is the process of saving all experiment-related information that you care about for each experiment that you run in machine learning.
There are different ways of tracking experiments. However, the most successful method is using tools explicitly designed to monitor and manage machine learning experiments.
By the end of this article, you will learn the most effective and collaborative tool that anyone can use easily for tracking, managing, and monitoring the ML runs and models in one place.
This post is mostly intended for machine learning practitioners who have started exploring MLOps tools and would like to use custom tools based on their use case and need.
“The content which will be found in this blog can assure you, the reader, that any of the opinions expressed in this post are of my very own.”
Let’s begin…
While exploring ML experiment tracking and management tools, I came across MLflow, an open-source platform for managing the end-to-end machine learning lifecycle, which is a great tool and can be an enormous help in every ML project. But the MLflow model registry lacks some functionalities which are essential in an ML model lifecycle, as listed below :
- As an open-source tool, MLflow isn’t the fastest; especially with hundreds or thousands of runs, the UI might get laggy.
- The MLflow model registry lacks code versioning and dataset versioning, making repeatability more challenging.
- There seem to be no model lineage or evaluating history features, such as models created downstream or testing run history.
- Because the team collaboration and access management capabilities aren’t available, you’ll have to develop some time-consuming workarounds if you operate in a group.
- No support for images (labels and descriptions) and interactive visualizations.
- MLflow is an open-source tool. You must set up and manage the MLflow server yourself unless you use the Databricks platform.
Many teams utilize MLflow Model Registry, and they see its worth. However, if the above elements are essential to you or your team and you want to include them in your model registry tool, here is an alternative you should consider.
Best Alternative to MLflow Model Registry
Neptune
The ML metadata store is a vital part of the MLOps stack that manages model-building metadata. Neptune is a centralized metadata store for any MLOps workflow. It allows you to keep track of, visualize, and compare thousands of machine learning models all in one location. It supports experiment tracking, model registry, and model monitoring, and it’s designed in a way that enables easy collaboration. It has Integrated with 25+ other tools and libraries, including multiple model training and hyperparameter optimization tools. Using Neptune, you don’t require a credit card to signup. Instead, a Gmail id will suffice.
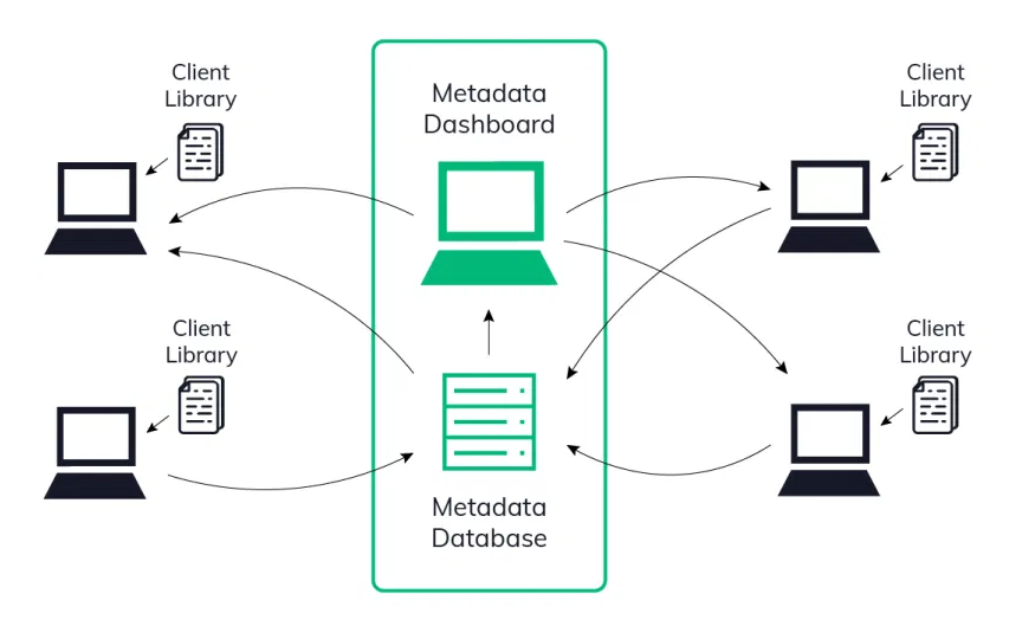
- For using the Neptune features, you need to install the client library — Neptune Client which makes it easy to log and query the ML metadata database.
- Metadata Database — It’s a place where your experiments, models, and datasets metadata are stored, and they can be efficiently logged and queried.
- Metadata dashboard — is a visual interface to the metadata database.
What does Neptune Metadata Store Offer?
First of all, you can write any model-building metadata to Neptune including code, git info, files, Jupyter notebooks, datasets, and more. This allows you to have model versions in one central registry and quickly analyze, compare, or extract data. Let’s understand each component of Neptune in detail…
Components of Neptune
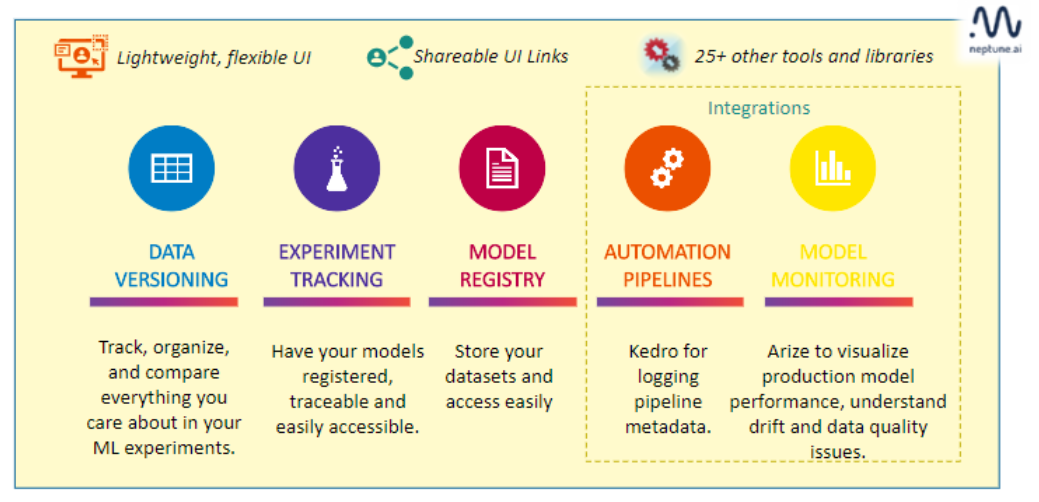
1. Data Versioning
You can log experiment and model training metadata that happens during ML run, including:
- Metrics.
- Hyperparameters.
- Learning curves.
- Training code and configuration files.
- Predictions (images, tables, etc.).
- Diagnostic charts (Confusion matrix, ROC curve, etc.) — you can log interactive graphing charts using external libraries such as Plotly, etc.
- Console logs.
- Hardware logs.
- Model binary or location to your model asset.
- Dataset versions.
- Links to recorded model training runs and experiments.
- Who trained the model.
- Model descriptions and notes.
You can also log artefact metadata such as:
- Dataset hash.
- Preview the dataset/prediction (head of the table, snapshot of the image folder).
- Description.
- Feature column names (for tabular data).
- Who created/modified it.
- When last modified.
- Size of the dataset.
- And more…
2. Experiment Tracking
Now all the logged metadata can be used for experiment tracking that helps you to organize your ML experimentation in a single place by:
- Metrics, parameters, images, and other machine learning metadata can be logged and displayed.
- You can organize your charts, search, group, and compare experiments with no effort.
- Experiments can be visualized and debugged in real-time.
- You are sharing results with your team by sending a persistent link.
- I am querying experiment metadata programmatically.
3. Model Registry
This feature allows you to keep track of your model development by storing it in a central model registry and making it repeatable and traceable. You may version, save, organize, and query models from model development through deployment. Model Registry can be used for a variety of purposes, including:
- Know precisely how every model was built.
- Record dataset, code, parameters, model binaries, and more for every training run.
- The test set prediction previews and model explanations.
- Get back to every model building metadata even months after.
- Share models with your team and access them programmatically.
Furthermore, it enables teams, either geographically close or distant, to collaborate on experiments because everything your team logs to Neptune is automatically accessible to every team member. So reproducibility is no longer a problem. You can use an API to get information about model training runs, including the code, parameters, model binary, and other objects.
Also, Neptune has integration with MLflow and many other libraries, tools, and ML/DL Frameworks, including multiple model training, model monitoring, automated pipelines, and hyperparameter optimization tools. You can add an integration to your notebook,.py project, or containerized ML project if it isn’t already there (in case you are using Kubernetes or Kubeflow).
I have created a public project called IRIS and logged the metadata, which can be used for organizing tracking the experiments. You can check out what metadata has been logged, and the notebook used can be found and downloaded from the notebook section in Neptune.
Neptune is available in the cloud version and can be deployed on-premise. The cloud version allows you to focus on ML, leaving metadata bookkeeping to Neptune. You can start free and then scale as you need it. The pricing details can be found here.
Conclusion
Finally, if you work in a team no matter where you or your colleagues run the training — whether it’s in the cloud, locally, in notebooks, or somewhere else — Neptune can be your one source of truth as well a database of your previous runs. Users can create projects within the app, work on them together, and share UI links (or external stakeholders).
All this functionality makes Neptune the link between all members of the ML team. For any model, you can know who created it and how; you can also check what data your model was trained on, and many more.
So, if you want a fully managed service or more control, the server version, Neptune, is the way to go.
Neptune has excellent documentation with examples, and you can gain more in-depth knowledge from the documentation.
Thank you for reading my article! I hope it helps 🙂
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.






