Introduction
Data replication, often referred to as database replication, is the process of continuously copying data to maintain real-time consistency across various data resources. Think of it as a safety net that prevents your data from vanishing or slipping through the gaps. In dynamic data landscapes, where information is ever-evolving, replication ensures that even data copies on the opposite side of the world remain seamlessly synchronized with the primary storage. In this article, we will explore all about this concept along with some data replication techniques.
This article was published as a part of the Data Science Blogathon.
Table of contents
- Introduction
- What is Data Replication?
- Data Replication in Distributed Database
- Purpose of Data Replication
- How do you Replicate a Database?
- Full Data Replication vs. Partial Replication
- Examples
- Data Replication Tools
- Top 7 Data Replication Strategies
- Advantages
- Disadvantages
- Conclusion
- Frequently Asked Question
What is Data Replication?
The process of making several copies of a piece of data and storing them at different locations allows for better network accessibility, fault tolerance, and backup copies. Like data mirroring, data replication can be applied to servers and individual computers. Data duplicates can be stored on the same system, on-site and off-site servers, and cloud-based hosts.

Data Replication in Distributed Database
Making numerous copies of data is the process of data replication. Once made, these replicas—also called copies—are stored in a few locations for backup, fault tolerance, and improved network accessibility. The replicated data may be stored on regional and distant servers, cloud-based hosts, or even on all of the same system’s servers.
The process of spreading data from a source server to other servers in a distributed database is known as data replication. This ensures that users may access the data they require without interfering with the work of others.
Purpose of Data Replication
For the following five reasons, you should backup your data to the cloud:
- As we previously mentioned, replication to the cloud keeps your records off-site and away from the business’s location. Even if a fire, flood, or storm seriously damages your primary instance, etc., your backup instance is secure in the cloud.
- It is less expensive to replicate information to the cloud than to do it in your own input center, and it may be utilized to retrieve any lost programs and input. It may not be necessary to pay for hardware, maintenance, or support fees associated with running a second storage center.
- On-demand scalability is made possible through data replication to the cloud. If your firm expands, contracts, or picks back up, you won’t have to spend money on new hardware to maintain your secondary instance. Additionally, no lengthy contracts bind you.
- You have a wide range of geographic options for replicating data to the cloud, depending on the requirements of your organization, including having a cloud instance in the next city across the country.
How do you Replicate a Database?
Replicated organisms may replicate sporadically or often. The distributed architecture of a company’s data sources is involved. The data is replicated and equally distributed across all sources using the organization’s distributed management system.
DDBMS, or distributed database management systems, generally ensure that any alterations, additions, or deletions to the data stored in one location are automatically reflected in the data stored in all the other sites. The system responsible for controlling the shared storage resulting from repository replication is a shared database management system or DDBMS.
Full Data Replication vs. Partial Replication
Full database replication occurs when a primary database is completely replicated across all instances of available replicas. This thorough technique replicates newly acquired, up-to-date, and previously obtained data to all destinations. Although this method is highly thorough, the amount of data it transfers necessitates significant computational power, which strains the network.

In contrast, to complete replication, partial replication only mirrors a subset of the data, typically the most recent updates. Partial replication isolates particular data items depending on the importance of the data at a particular point. For instance, a sizable financial company with its headquarters in London might have numerous satellite offices functioning all over the world, including ones in Boston, Kuala Lumpur, and so forth.
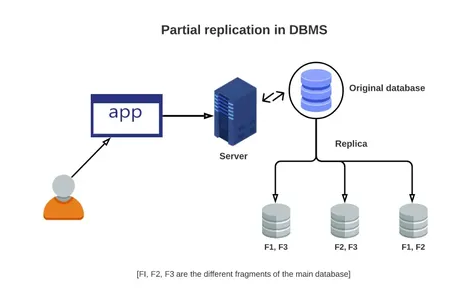
Examples
There are three main categories of data replication: transactional, merge, and snapshot.
1. Transactional Replication
This kind of database replication enables data from a primary database to duplicate data in real-time to a replica instance by reflecting these changes in the order they were produced in the primary database. It enhances reliability. The replication takes a “snapshot” of the data in the primary and uses that snapshot as a reference for what else has to be copied. Transactional replication enables the tracking and distribution of changes.
Due to the gradual nature of this process, transactional replication isn’t the greatest choice when looking for a backup repository alternative. Transactional replication is a good choice when data is frequently changing from a single location when real-time consistency is required across all data locations, when each minute change must be taken into account in addition to the overall consequence of the change, and when data frequently changes from a single location.
2. Snapshot Replication
Snapshot replication, as its name suggests, copies data from the primary to the replica by “capturing” it at a specific moment in time. When data is sent from the primary to the replica, snapshot replication, like a photograph, captures how the data looks at that precise time but ignores subsequent changes. As a result, avoid utilizing snapshot replication to build a backup.
Snapshot replication won’t have access to updated data if there is a storage failure. You can start with a snapshot to maintain consistency, but ensure that all changes made to the primary are propagated to every replica.
On the other side, this approach is quite useful for data recovery after an unintentional deletion. Imagine it being similar to your Google Docs Version History. Wouldn’t it be nice to continue working on your presentation the way it was four hours ago? You could click back on that version, or “snapshot,” from four hours ago and see what your information looks like if Google Docs takes a snapshot of your work at hourly intervals.
3. Merge Replication
This method typically starts with a snapshot of the information, distributes it across its replicas, and maintains data synchronization throughout the system. In contrast to other replication types, merge replication allows individual data updates from each node while integrating those updates into a single, coherent whole.
You must determine the most relevant aspects to arrange in your situation. Repository replication technologies can be selected depending on elements like price, feature, and accessibility. A company should commit to making payments. The goal is to find the best repository replication solutions for the project within the budget allotted.
Data Replication Tools
Some of the top data replication tools are as follows:
Rubrik
Rubrik is a service that offers rapid backups, archiving, immediate recovery, analytics, and copy management for managing and backing up data in the cloud. It includes cutting-edge data center technologies and offers simplified backups. An easy-to-use user interface makes giving tasks to any user group simple. Depending on the use case, it may be required to integrate various clusters into a single dashboard. However, this has some restrictions.
Shareplex
SharePlex is a different real-time replication repository replication technology. The program is incredibly adaptable and compatible with a wide range of storage. A message queuing technique makes quick data transit possible and is greatly scalable. Both the tool’s method for gathering change data and its monitoring services have some drawbacks.
Hevo data
As businesses’ capacity to collect data develop tremendously, data teams are crucial to guiding data-driven decisions. They still have trouble creating a single source of truth from the diverse data in their warehouse. Because of broken pipelines, poor data quality, bugs, errors, and a lack of control and visibility over the data flow, data integration is a pain. 1000+ data teams utilize Hevo’s Data Pipeline Platform to swiftly and effectively aggregate data from more than 150 sources. Millions of data events from SaaS apps, repositories, file storage, and streaming sources may be instantly copied because of Hevo’s fault-tolerant architecture.
Top 7 Data Replication Strategies
- Log-Based Incremental Replication: This method involves replicating only the changes recorded in transaction logs, which track modifications to the database. It efficiently reduces data transfer during replication, making it ideal for large databases.
- Key-Based Incremental Replication: Replicates data based on specific keys or columns, ensuring the copying of only relevant data to the target system. This strategy proves useful when replicating a subset of the database is required.
- Full Table Replication: This approach replicates entire database tables each time a change occurs. It offers simplicity but can result in higher data transfer volumes.
- Snapshot Replication: Takes snapshots of the entire database at specific intervals and transfers them to the target system. This ensures data consistency but may not be suitable for real-time applications.
- Transactional Replication: Replicates changes in real-time, often employed in scenarios where data accuracy and consistency are critical, such as in financial systems.
- Merge Replication: Manages data changes in both the source and target systems. It is suited for scenarios where data can be updated in both locations and needs synchronization.
- Bidirectional Replication: Allows data to flow in both directions, ensuring updates in one system reflect in the other. This maintains consistency in environments with multiple data sources.
Advantages
Replication of the data can give users consistent access to the information. It also increases the number of concurrent users accessing the data. Data redundancies are removed by combining databases and updating slave databases with partial data. Furthermore, data replication speeds up database access.
1. Availability and Reliability of Data
Data replication makes ensuring that data is accessible. This is especially helpful for multinational companies with offices spread out around the globe. As a result, data is still accessible to other sites in the event of hardware failure or any other problem in one place.
2. Server Efficiency
Replication of data can improve and accelerate server performance. Users can get data much more quickly when businesses operate various data copies across multiple servers. Additionally, administrators can use fewer processor cycles on the primary server for resource-intensive writing activities when all data read operations are routed to a replica.
3. More efficient network performance
By retrieving the necessary data from the site where the transaction is being completed, maintaining copies of the same data in many locations can reduce data access latency.
4. Data Analytics Assistance
Businesses that are heavily focused on data typically replicate information from various sources into their data repositories, including data warehouses or data lakes. This facilitates the completion of joint projects by the analytics team, which is distributed across numerous sites.
5. Enhanced Test System Performance
Data dissemination and synchronization for test systems that demand quick accessibility for quicker decision-making are made simpler by duplication.
Disadvantages
The upkeep of data replication requires a lot of hardware and storage space. Replication is expensive, and maintaining the infrastructure to maintain data consistency is challenging. It also makes more software components vulnerable to security and privacy issues.
Replication offers numerous benefits, but there should also be a balance between them in an organization. The biggest obstacle to maintaining consistent data across an organization is a lack of resources:
1. Higher prices
Greater storage and processing overheads result from maintaining duplicate copies of the same data in several places and distributed database systems.
2. Time Restrictions
Internal staff must dedicate time to managing the duplication process to ensure that the copied data is compatible with the original data.
3. Bandwidth
Network traffic may rise as a result of maintaining consistency among data replicas.
4. Unreliable Data
This might only be an issue for a few hours, or your data might completely lose sync. Database administrators should continuously ensure that data is updated to address this issue. The method of replicating data should be thoroughly thought out, put into action, evaluated, and polished as necessary.
Conclusion
This article thoroughly explains each Data Replication Strategy and provides all the information you need to know. It gives a quick overview of a variety of related ideas, which aids users in better understanding them and putting them to use for data replication and recovery in the most effective manner. The difficulties that many data engineers have were also discussed, and most crucially, how a data replication tool may aid data teams in making better use of their time and resources. Replication of data has obvious advantages. Companies must be ready for the difficulties brought on by the expanding number of sources and destinations. Therefore, it is crucial to implement a scalable and dependable data replication mechanism.
The Key takeaways of this article are as follows:
- Because data is stored in many places, users can retrieve it from the servers closest to them and experience lower latency.
- Businesses can spread traffic across multiple servers thanks to data replication, which enhances server performance and eases the load on individual servers.
- Effective disaster recovery and data protection are provided via data replication. Due to data availability, millions of dollars could be wasted every hour a crucial data source is down.
- Businesses can use various techniques depending on the use case and the present data architecture.
Frequently Asked Question
Q1. What is data replication and example?
A. Data replication is the process of copying data from one source to another to enhance redundancy or accessibility. For example, a company might replicate its database to a backup server to ensure data availability in case of server failure.
Q2. What is the purpose of data replication?
A. The purpose of data replication is to improve data availability, reliability, and disaster recovery preparedness. It reduces the risk of data loss and minimizes downtime by maintaining duplicate copies of data.
Q3. What are the steps of data replication?
A. The steps of data replication typically involve data extraction from the source, any necessary data transformation, data transmission to the target, and loading the data into the target system.
Q4. What are the two basic styles of data replication?
A. The two basic styles of data replication are snapshot replication, which captures data at a specific moment, and continuous replication, which keeps data synchronized in real-time, ensuring that changes are propagated immediately
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I currently working as an Assistant professor in the Information technology department at SAL COLLEGE OF ENGINEERING, AHMEDABAD .I am currently doing Ph.D. in Medical Image processing. My research interest are computer vision, deep learning, machine learning, database etc.






