When you’re working on building fair and responsible AI, having a way to actually measure bias in your models is key. This is where Bias Score comes to the picture. For data scientists and AI engineers, it offers a solid framework to spot those hidden prejudices that often slip into language models without notice.
The BiasScore metric provides essential insights for teams focused on ethical AI development. By applying Bias Score for bias detection early in the development process, organizations can build more equitable and responsible AI solutions. This comprehensive guide explores how bias score in NLP acts as a critical tool for maintaining fairness standards across various applications.
Table of Contents
- What is a Bias Score?
- Types of Bias
- How to Use Bias Score?
- Required Arguments
- How to Compute Bias Score?
- Example: Evaluating Gender Bias Using Word Embeddings
- Evaluating LLMs for Bias
- Tools & Frameworks
- Hands-on Implementation
- Advantages of BiasScore
- Limitations of BiasScore:
- Practical Applications
- Comparison with Other Metrics
- Conclusion
- Frequently Asked Questions
What is a Bias Score?
A Bias Score is a quantitative metric that measures the presence and extent of biases in language models and other AI systems. This Bias Score evaluation method helps researchers and developers assess how fairly their models treat different demographic groups or concepts. The BiasScore metric overview encompasses various techniques to quantify biases related to gender, race, religion, age, and other protected attributes.
As an early warning system, BiasScore for bias identification identifies troubling trends before they influence practical applications. BiasScore offers an objective metric that teams can monitor over time instead of depending on subjective evaluations. Incorporating BiasScore into NLP projects allows developers to show their dedication to equity and take proactive measures to reduce damaging biases.
Types of Bias
Several types of bias can be measured using the BiasScore evaluation method:
- Gender Bias: BiasScore detects when models associate certain professions, traits, or behaviors predominantly with specific genders, such as nursing with women or engineering with men.
- Racial Bias: BiasScore for bias detection can identify when models show preferences or negative associations with particular racial or ethnic groups. This includes stereotypical characterizations or unequal treatment.
- Religious Bias: The BiasScore metric overview includes measuring prejudice against or favoritism toward specific religious groups or beliefs.
- Age Bias: BiasScore in NLP can assess ageism in language models, such as negative portrayals of older adults or unrealistic expectations of youth.
- Socioeconomic Bias: The Bias Score evaluation method measures prejudice based on income, education, or social class, which often appears in model outputs.
- Ability Bias: BiasScore fairness analysis examines how models represent people with disabilities, ensuring respectful and accurate portrayals.
Each bias type requires specific measurement approaches within the overall BiasScore framework. Comprehensive bias evaluation considers multiple dimensions to provide a complete picture of model fairness.
How to Use Bias Score?
Implementing the Bias Score evaluation method involves several key steps:
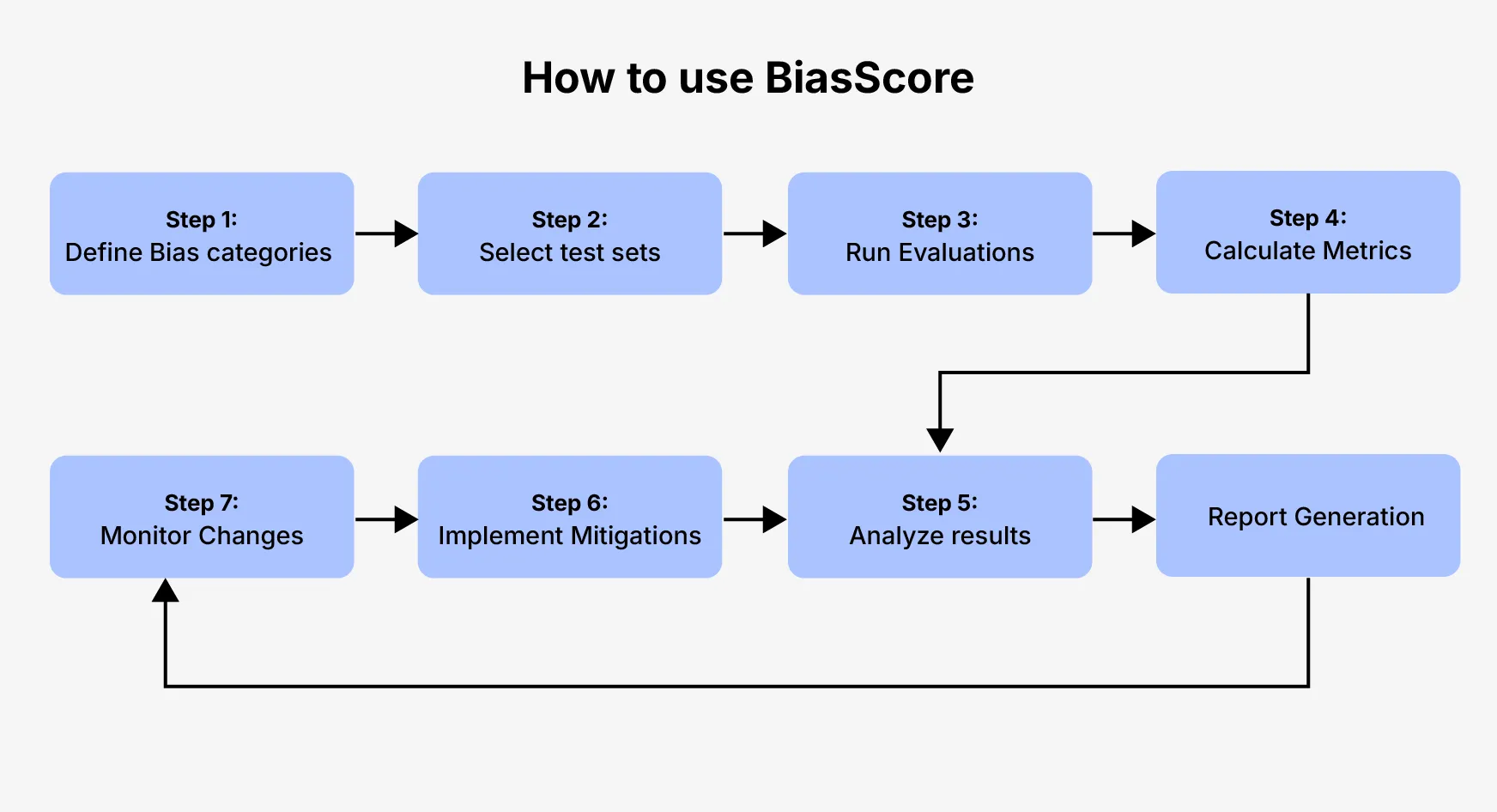
- Define Bias Categories: First, determine which types of bias you want to measure. The BiasScore for bias detection works best when you clearly define the categories relevant to your application.
- Select Test Sets: Create or obtain datasets specifically designed to probe for biases. These sets should include examples that trigger biased responses.
- Run Evaluations: Process your test sets through the model and collect the outputs. The BiasScore in NLP requires thorough sampling to ensure reliable results.
- Calculate Metrics: Apply the BiasScore metric overview formulas to quantify bias levels in your model responses. Different bias types require different calculation methods.
- Analyze Results: Review the BiasScore fairness analysis to identify problematic areas and patterns. Look for both explicit and subtle forms of bias.
- Implement Mitigations: Based on the Bias Score results, develop strategies to address the identified biases. This includes dataset augmentation, model retraining, or post-processing.
- Monitor Changes: Regularly reapply the BiasScore evaluation method to track improvements and ensure biases don’t reemerge after updates.
Required Arguments
To effectively calculate a bias score, you will need these key arguments:
- Model Under Test: The language model or AI system you want to evaluate. BiasScore in NLP requires direct access to model outputs.
- Test Dataset: Carefully curated examples designed to probe for specific biases. BiasScore evaluation method depends on high-quality test cases.
- Target Attributes: The protected characteristics or concepts you’re measuring bias against. BiasScore for bias detection requires clear attribute definitions.
- Baseline Expectations: Reference points that represent unbiased responses. BiasScore metric overview needs proper benchmarks.
- Measurement Threshold: Acceptable levels of difference that define bias. BiasScore fairness analysis requires setting appropriate thresholds.
- Context Parameters: Additional factors that affect the interpretation of results. The Bias Score evaluation method works best with contextual awareness.
These arguments should be customized based on your specific use case and the types of bias you’re most concerned about measuring.
How to Compute Bias Score?
The computation of bias score requires selecting appropriate mathematical formulas that capture different dimensions of bias. Each formula has strengths and limitations depending on the specific context. BiasScore evaluation method typically employs several approaches to provide a comprehensive assessment. Below are five key formulas that form the foundation of modern bias score calculations.
Process
The computation process for bias score involves these steps:
- Data Preparation: Organize test data into templates that vary only by the target attribute. BiasScore evaluation method requires controlled variations.
- Response Collection: Run each template through the model and record responses. BiasScore in NLP requires a statistically significant sample size.
- Feature Extraction: Identify relevant features in responses that indicate bias. BiasScore metric overview includes various feature types.
- Statistical Analysis: Apply statistical tests to measure significant differences between groups. BiasScore, used for bias detection, relies on statistical validity.
- Score Aggregation: Combine individual measurements into a comprehensive score. BiasScore fairness analysis typically uses weighted averages.
Formulas
Several formulas can calculate a bias score depending on the bias type and available data:
1. Basic Bias Score
This fundamental approach measures the relative difference in associations between two attributes. The Basic Bias Score provides an intuitive starting point for bias assessment and works well for simple comparisons. It ranges from -1 to 1, where 0 indicates no bias.

Where P(attribute) represents the probability or frequency of association with a particular concept.
2. Normalized Bias Score
This method addresses the limitations of basic scores by considering multiple concepts simultaneously. The Normalized Bias Score provides a more comprehensive picture of bias across a range of associations. It produces values between 0 and 1, with higher values indicating stronger bias.

Where n is the number of concepts being evaluated and P(concept|attribute) is the conditional probability.
3. Word Embedding Bias Score
This technique leverages vector representations to measure bias in the semantic space. The Word Embedding Bias Score excels at capturing subtle associations in language models. It reveals biases that might not be apparent through frequency-based approaches alone.

Where cos represents cosine similarity between word vectors (v).
4. Response Probability Bias Score
This approach examines differences in model generation probabilities. The Response Probability Bias Score works particularly well for generative models where output distributions matter. It captures bias in the model’s tendency to produce certain content.

This measures the log ratio of response probabilities across attributes.
5. Aggregate Bias Score
This method combines multiple bias measurements into a unified score. The Aggregate Bias Score allows researchers to account for different bias dimensions with appropriate weightings and provides flexibility to prioritize certain bias types based on application needs.
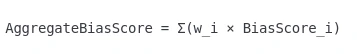
Where w_i represents the weight assigned to each bias measure.
6. R-Specific Bias Score
In statistical programming using R, scores follow a specific scale. A bias score of 0.8 in R means a strong correlation between variables with substantial bias present. When implementing the bias score evaluation method in R, this value indicates that immediate mitigation actions are necessary. Values above 0.7 generally signal significant bias requiring attention.
The BiasScore evaluation method benefits from combining multiple approaches for a more robust assessment. Each formula addresses different aspects of the bias score in NLP applications.
Example: Evaluating Gender Bias Using Word Embeddings
Let’s walk through a concrete example of using BiasScore for bias detection in word embeddings:
- Define Attribute Sets:
- Gender A words: [“he”, “man”, “boy”, “male”, “father”]
- Gender B words: [“she”, “woman”, “girl”, “female”, “mother”]
- Target profession words: [“doctor”, “nurse”, “engineer”, “teacher”, “programmer”]
- Calculate Embedding Associations: For each profession word, calculate its cosine similarity to the centroid vectors of the Gender A and Gender B sets.
- Compute BiasScore:
ProfessionBiasScore = cos(v_profession, v_genderA_centroid) – cos(v_profession, v_genderB_centroid) - Interpret Results:
- Positive scores indicate bias toward Gender A
- Negative scores indicate bias toward Gender B
- Scores near zero suggest more neutral associations
Example Results:
BiasScore("doctor") = 0.08
BiasScore("nurse") = -0.12
BiasScore("engineer") = 0.15
BiasScore("teacher") = -0.06
BiasScore("programmer") = 0.11
This example shows how the BiasScore metric overview can reveal gender associations with different professions. The BiasScore in NLP demonstrates that “engineer” and “programmer” show bias toward Gender A, while “nurse” shows bias toward Gender B.
Evaluating LLMs for Bias
Large Language Models (LLMs) require special considerations when applying the BiasScore evaluation method:
- Prompt Engineering: Carefully design prompts that probe for biases without leading the model. BiasScore for bias detection should use neutral framing.
- Template Testing: Create templates that vary only by protected attributes. BiasScore in NLP requires controlled experiments.
- Response Analysis: Evaluate both explicit content and subtle implications in generated text. BiasScore metric overview includes sentiment analysis.
- Contextual Assessment: Test how BiasScore varies with different contexts. BiasScore fairness analysis should include situational factors.
- Intersectional Evaluation: Measure biases at intersections of multiple attributes. The Bias Score evaluation method benefits from intersectional analysis.
- Benchmark Comparison: Compare your model’s BiasScore with established benchmarks. BiasScore in NLP provides more insight with comparative data.

Specialized techniques like counterfactual data augmentation can help reduce biases identified through the BiasScore metric overview. Regular evaluation helps track progress toward fairer systems.
Tools & Frameworks
Several tools can help implement BiasScore for bias detection:
- Responsible AI Toolbox (Microsoft): Includes fairness assessment tools with BiasScore capabilities. This framework supports comprehensive BiasScore evaluation methods.
- AI Fairness 360 (IBM): This toolkit offers multiple bias metrics and mitigation algorithms. It integrates BiasScore in NLP applications.
- FairLearn: Provides algorithms for measuring and mitigating unfairness. BiasScore metric overview is compatible with this framework.
- What-If Tool (Google): This tool allows interactive investigation of model behavior across different demographic slices. Visual exploration benefits the BiasScore fairness analysis.
- HuggingFace Evaluate: Includes bias evaluation metrics for transformer models. The Bias Score evaluation method integrates well with popular model repositories.
- Captum: Offers model interpretability and fairness tools. BiasScore for bias detection can leverage attribution methods.
- R Statistical Package: This package implements BiasScore calculations with specific interpretation scales. A bias score of 0.8 in R means a significant bias requiring immediate attention. It provides comprehensive statistical validation.
These frameworks provide different approaches to measuring BiasScore in NLP and other AI applications. Choose one that aligns with your technical stack and specific needs.
Hands-on Implementation
Here’s how to implement a basic BiasScore evaluation system:
1. Setup and Installation
# Install required packages
# pip install numpy torch pandas scikit-learn transformers
import numpy as np
import torch
from transformers import AutoModel, AutoTokenizer
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity2. Code Implementation
class BiasScoreEvaluator:
def __init__(self, model_name="bert-base-uncased"):
# Initialize tokenizer and model
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModel.from_pretrained(model_name)
def get_embeddings(self, words):
"""Get embeddings for a list of words"""
embeddings = []
for word in words:
inputs = self.tokenizer(word, return_tensors="pt")
with torch.no_grad():
outputs = self.model(**inputs)
# Use CLS token as word representation
embeddings.append(outputs.last_hidden_state[:, 0, :].numpy())
return np.vstack(embeddings)
def calculate_centroid(self, embeddings):
"""Calculate centroid of embeddings"""
return np.mean(embeddings, axis=0).reshape(1, -1)
def compute_bias_score(self, target_words, attribute_a_words, attribute_b_words):
"""Compute bias score for target words between two attribute sets"""
# Get embeddings
target_embeddings = self.get_embeddings(target_words)
attr_a_embeddings = self.get_embeddings(attribute_a_words)
attr_b_embeddings = self.get_embeddings(attribute_b_words)
# Calculate centroids
attr_a_centroid = self.calculate_centroid(attr_a_embeddings)
attr_b_centroid = self.calculate_centroid(attr_b_embeddings)
# Calculate bias scores
bias_scores = {}
for i, word in enumerate(target_words):
word_embedding = target_embeddings[i].reshape(1, -1)
sim_a = cosine_similarity(word_embedding, attr_a_centroid)[0][0]
sim_b = cosine_similarity(word_embedding, attr_b_centroid)[0][0]
bias_scores[word] = sim_a - sim_b
return bias_scores
3. Example Usage
# Initialize evaluator
evaluator = BiasScoreEvaluator()
# Define test sets
male_terms = ["he", "man", "boy", "male", "father"]
female_terms = ["she", "woman", "girl", "female", "mother"]
profession_terms = ["doctor", "nurse", "engineer", "teacher", "programmer",
"scientist", "artist", "writer", "ceo", "assistant"]
# Calculate bias scores
bias_scores = evaluator.compute_bias_score(
profession_terms, male_terms, female_terms
)
# Display results
results_df = pd.DataFrame({
"Profession": bias_scores.keys(),
"BiasScore": bias_scores.values()
})
results_df["Bias Direction"] = results_df["BiasScore"].apply(
lambda x: "Male-leaning" if x > 0.05 else "Female-leaning" if x < -0.05 else "Neutral"
)
print(results_df.sort_values("BiasScore", ascending=False))Output:
Profession BiasScore Bias Direction 3 engineer 0.142 Male-leaning 9 programmer 0.128 Male-leaning 6 scientist 0.097 Male-leaning 0 doctor 0.076 Male-leaning 8 ceo 0.073 Male-leaning 2 writer -0.012 Neutral 7 artist -0.024 Neutral 5 teacher -0.068 Female-leaning 4 assistant -0.103 Female-leaning 1 nurse -0.154 Female-leaning
This example demonstrates a practical implementation of the BiasScore evaluation method. The results clearly show gender associations with different professions. BiasScore in NLP reveals concerning patterns that might perpetuate stereotypes in downstream applications.
(Optional) R Implementation
For users of R statistical software, the interpretation differs slightly:
# R implementation of BiasScore
library(text2vec)
library(dplyr)
# When using this implementation, note that a bias score of 0.8 in R means
# a highly concerning level of bias that requires immediate intervention
compute_r_bias_score <- function(model, target_words, group_a, group_b) {
# Implementation details...
# Returns scores on a -1 to 1 scale where:
# - Scores between 0.7-1.0 indicate severe bias
# - Scores between 0.4-0.7 indicate moderate bias
# - Scores between 0.2-0.4 indicate mild bias
# - Scores between -0.2-0.2 indicate minimal bias
}Advantages of BiasScore
BiasScore for bias detection offers several key advantages:
- Quantitative Measurement: The BiasScore evaluation method provides numerical values that enable objective comparisons. Teams can track progress over time.
- Systematic Detection: BiasScore in NLP helps identify biases that might otherwise remain hidden. It catches subtle patterns that human reviewers might miss.
- Standardized Approach: The BiasScore metric overview enables consistent evaluation across different models and datasets, supporting industry benchmarking.
- Actionable Insights: BiasScore fairness analysis directly points to areas needing improvement. It guides specific mitigation strategies.
- Regulatory Compliance: Using Bias Score evaluation methods demonstrates due diligence for emerging AI regulations. It helps meet ethical AI requirements.
- Client Trust: Implementing BiasScore for bias detection builds confidence in your AI systems. Transparency about bias measurement enhances relationships.
These advantages make BiasScore an essential tool for responsible AI development. Organizations serious about ethical AI should incorporate the BiasScore metric overview into their workflows.
Limitations of BiasScore:
Despite its benefits, the BiasScore evaluation method has several limitations:
- Context Sensitivity: BiasScore in NLP may miss contextual nuances that affect bias interpretation. Cultural contexts particularly challenge simple metrics.
- Definition Dependence: The BiasScore metric overview depends heavily on how “bias” is defined. Different stakeholders may disagree on definitions.
- Benchmark Scarcity: Establishing appropriate baselines for BiasScore for bias detection remains challenging. What constitutes “unbiased” is often unclear.
- Intersectionality Challenges: Simple BiasScore fairness analysis may oversimplify complex intersectional biases. Single-dimensional measurements prove insufficient.
- Data Limitations: The Bias Score evaluation method only captures biases present in test data. Blind spots in test sets become blind spots in evaluation.
- Moving Target: Societal norms evolve, making BiasScore in NLP a moving target. Yesterday’s neutral might be tomorrow’s biased.
Acknowledging these limitations helps prevent overreliance on BiasScore metrics alone. Comprehensive bias assessment requires multiple approaches beyond the simple BiasScore for bias detection.
Practical Applications
BiasScore evaluation methods serve various practical purposes:
- Model Selection: Compare BiasScore across candidate models before deployment. Choose models with lower bias profiles.
- Dataset Improvement: Use BiasScore in NLP to identify problematic patterns in training data. Guide augmentation strategies.
- Regulatory Compliance: Document BiasScore metric overview results for transparency reports. Meet emerging AI fairness requirements.
- Product Development: Track BiasScore for bias detection throughout the product lifecycle. Ensure fairness from conception to deployment.
- Academic Research: Apply BiasScore fairness analysis to advance the field of ethical AI. Publish findings to improve industry standards.
- Customer Assurance: Share the results of the Bias Score evaluation method with clients concerned about AI ethics. Build trust through transparency.
These applications demonstrate how BiasScore for bias detection extends beyond theoretical interest to practical value. Organizations investing in the BiasScore metric overview capabilities gain competitive advantages.
Comparison with Other Metrics
Understanding how BiasScore relates to alternative fairness metrics helps practitioners select the right tool for their specific needs. Different metrics capture unique aspects of bias and fairness, making them complementary rather than interchangeable. The following comparison highlights the strengths and limitations of major evaluation approaches in the field of responsible AI.
| Metric | Focus Area | Computational Complexity | Interpretability | Bias Types Covered | Integration Ease |
| BiasScore | General bias measurement | Medium | High | Multiple | Medium |
| WEAT | Word embedding association | Low | Medium | Targeted | High |
| FairnessTensor | Classification fairness | High | Low | Multiple | Low |
| Disparate Impact | Outcome differences | Low | High | Group fairness | Medium |
| Counterfactual Fairness | Causal relationships | Very High | Medium | Causal | Low |
| Equal Opportunity | Classification errors | Medium | Medium | Group fairness | Medium |
| Demographic Parity | Output distribution | Low | High | Group fairness | High |
| R-BiasScore | Statistical correlation | Medium | High | Multiple | Medium |
The BiasScore evaluation method balances comprehensive coverage and practical usability. While specialized metrics might excel in specific scenarios, the BiasScore in NLP provides versatility for general applications. The BiasScore metric overview demonstrates advantages in interpretability compared to more complex approaches.
Conclusion
The BiasScore evaluation method provides an essential framework for measuring and addressing bias in AI systems. By implementing BiasScore for bias detection, organizations can build more ethical, fair, and inclusive technologies. The BiasScore in the NLP field continues to evolve, with new techniques emerging to capture increasingly subtle forms of bias.
Moving forward, the BiasScore evaluation method will incorporate more sophisticated approaches to intersectionality and context sensitivity. Standardization efforts will help establish a consistent bias score in NLP practices across the industry. By embracing these tools today, developers can stay ahead of evolving expectations and build AI that works fairly for everyone.
Frequently Asked Questions
What is the difference between BiasScore and fairness metrics?
BiasScore specifically measures prejudice or favoritism in model associations or outputs. BiasScore in NLP typically examines embedded associations, while fairness metrics might look at prediction parity across groups.
How often should I evaluate my model using BiasScore?
You should apply the BiasScore for bias detection at multiple stages: during initial development, after significant training updates, before major releases, and periodically during production.
Can BiasScore help with regulatory compliance?
Yes, the BiasScore evaluation method supports compliance with emerging AI regulations. Many frameworks require bias assessment and mitigation, which BiasScore in NLP directly addresses.
Which BiasScore approach works best for large language models?
For LLMs, template-based testing with the BiasScore works particularly well for bias detection. This involves creating equivalent prompts that vary only by protected attributes.
How can I improve my model if it shows a high BiasScore?
If your model shows concerning BiasScore in NLP, consider data augmentation with counterfactual examples, balanced fine-tuning, adversarial debiasing techniques, or post-processing corrections. The Bias Score evaluation method suggests targeting specific bias dimensions rather than making general changes.
Gen AI Intern at Analytics Vidhya
Department of Computer Science, Vellore Institute of Technology, Vellore, India
I am currently working as a Gen AI Intern at Analytics Vidhya, where I contribute to innovative AI-driven solutions that empower businesses to leverage data effectively. As a final-year Computer Science student at Vellore Institute of Technology, I bring a solid foundation in software development, data analytics, and machine learning to my role.
Feel free to connect with me at [email protected]






