Data preprocessing remains crucial for machine learning success, yet real-world datasets often contain errors. Data preprocessing using Cleanlab provides an efficient solution, leveraging its Python package to implement confident learning algorithms. By automating the detection and correction of label errors, Cleanlab simplifies the process of data preprocessing in machine learning. With its use of statistical methods to identify problematic data points, Cleanlab enables data preprocessing using Cleanlab Python to enhance model reliability. For example, Cleanlab streamlines workflows, improving machine learning outcomes with minimal effort.
Table of contents
Why Data Preprocessing Matters?
Data preprocessing directly impacts model performance. Dirty data with incorrect labels, outliers, and inconsistencies leads to poor predictions and unreliable insights. Models trained on flawed data perpetuate these errors, creating a cascading effect of inaccuracies throughout your system. Quality preprocessing eliminates these issues before modeling begins.
Effective preprocessing also saves time and resources. Cleaner data means fewer model iterations, faster training, and reduced computational costs. It prevents the frustration of debugging complex models when the real problem lies in the data itself. Preprocessing transforms raw data into valuable information that algorithms can effectively learn from.
How to Preprocess Data Using Cleanlab?
Cleanlab helps clean and validate your data before training. It finds bad labels, duplicates, and low-quality samples using ML models. It’s best for label and data quality checks, not basic text cleaning.
Key Features of Cleanlab:
- Detects mislabeled data (noisy labels)
- Flags duplicates and outliers
- Checks for low-quality or inconsistent samples
- Provides label distribution insights
- Works with any ML classifier to improve data quality
Now, let’s walk through how you can use Cleanlab step by step.
Step 1: Installing the Libraries
Before starting, we need to install a few essential libraries. These will help us load the data and run Cleanlab tools smoothly.
!pip install cleanlab
!pip install pandas
!pip install numpy- cleanlab: For detecting label and data quality issues.
- pandas: To read and handle the CSV data.
- numpy: Supports fast numerical computations used by Cleanlab.
Step 2: Loading the Dataset
Now we load the dataset using Pandas to begin preprocessing.
import pandas as pd
# Load dataset
df = pd.read_csv("/content/Tweets.csv")
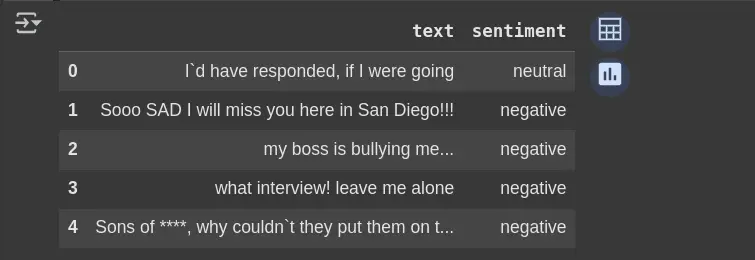
df.head(5)- pd.read_csv():
- df.head(5):

Now, once we have loaded the data. We’ll focus only on the columns we need and check for any missing values.
# Focus on relevant columns
df_clean = df.drop(columns=['selected_text'], axis=1, errors='ignore')
df_clean.head(5)Removes the selected_text column if it exists; avoids errors if it doesn’t. Helps keep only the necessary columns for analysis.
Step 3: Check Label Issues
from cleanlab.dataset import health_summary
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import cross_val_predict
from sklearn.preprocessing import LabelEncoder
# Prepare data
df_clean = df.dropna()
y_clean = df_clean['sentiment'] # Original string labels
# Convert string labels to integers
le = LabelEncoder()
y_encoded = le.fit_transform(y_clean)
# Create model pipeline
model = make_pipeline(
TfidfVectorizer(max_features=1000),
LogisticRegression(max_iter=1000)
)
# Get cross-validated predicted probabilities
pred_probs = cross_val_predict(
model,
df_clean['text'],
y_encoded, # Use encoded labels
cv=3,
method="predict_proba"
)
# Generate health summary
report = health_summary(
labels=y_encoded, # Use encoded labels
pred_probs=pred_probs,
verbose=True
)
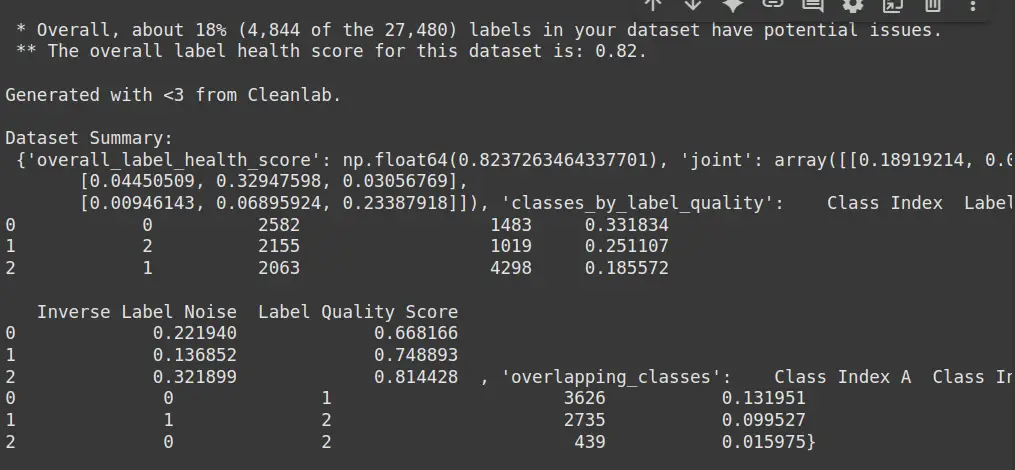
print("Dataset Summary:\n", report)- df.dropna(): Removes rows with missing values, ensuring clean data for training.
- LabelEncoder(): Converts string labels (e.g., “positive”, “negative”) into integer labels for model compatibility.
- make_pipeline(): Creates a pipeline with a TF-IDF vectorizer (converts text to numeric features) and a logistic regression model.
- cross_val_predict(): Performs 3-fold cross-validation and returns predicted probabilities instead of labels.
- health_summary(): Uses Cleanlab to analyze the predicted probabilities and labels, identifying potential label issues like mislabels.
- print(report): Displays the health summary report, highlighting any label inconsistencies or errors in the dataset.
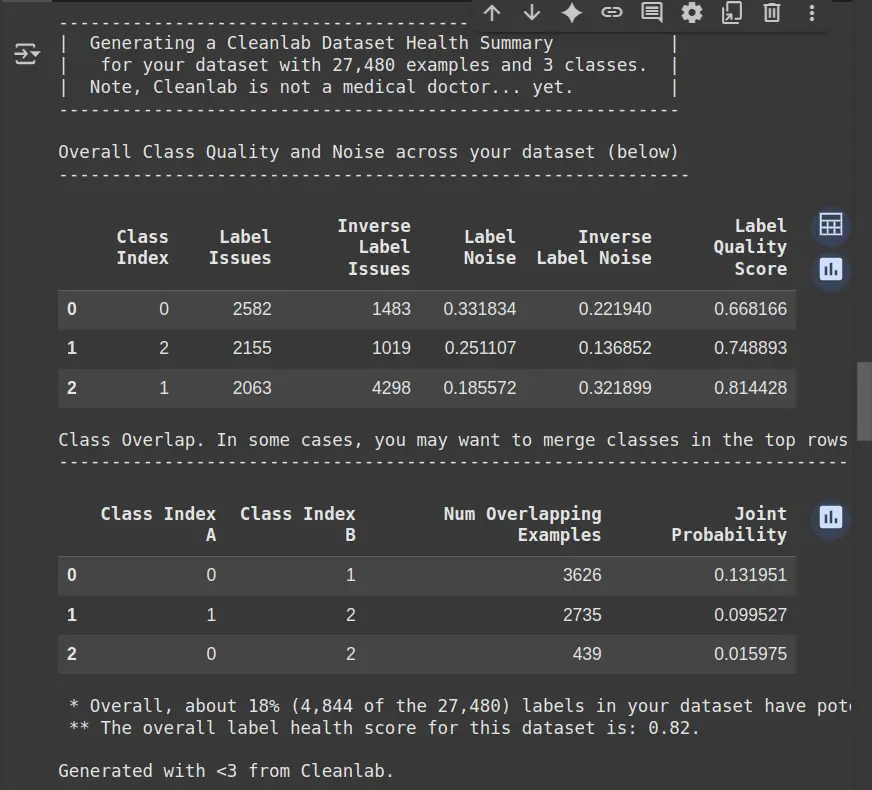
- Label Issues: Indicates how many samples in a class have potentially incorrect or ambiguous labels.
- Inverse Label Issues: Shows the number of instances where the predicted labels are incorrect (opposite of true labels).
- Label Noise: Measures the extent of noise (mislabeling or uncertainty) within each class.
- Label Quality Score: Reflects the overall quality of labels in a class (higher score means better quality).
- Class Overlap: Identifies how many examples overlap between different classes, and the probability of such overlaps occurring.
- Overall Label Health Score: Provides an overall indication of the dataset’s label quality (higher score means better health).
Step 4: Detect Low-Quality Samples
This step involves detecting and isolating the samples in the dataset that may have labeling issues. Cleanlab uses the predicted probabilities and the true labels to identify low-quality samples, which can then be reviewed and cleaned.
# Get low-quality sample indices
from cleanlab.filter import find_label_issues
issue_indices = find_label_issues(labels=y_encoded, pred_probs=pred_probs)
# Display problematic samples
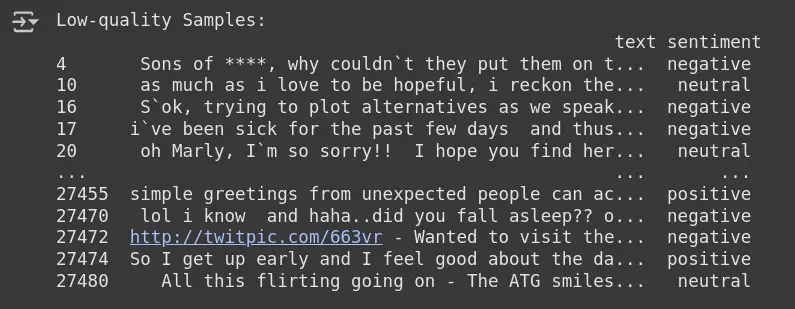
low_quality_samples = df_clean.iloc[issue_indices]
print("Low-quality Samples:\n", low_quality_samples)- find_label_issues(): A function from Cleanlab that detects the indices of samples with label issues, based on comparing the predicted probabilities (pred_probs) and true labels (y_encoded).
- issue_indices: Stores the indices of the samples that Cleanlab identified as having potential label issues (i.e., low-quality samples).
- df_clean.iloc[issue_indices]: Extracts the problematic rows from the clean dataset (df_clean) using the indices of the low-quality samples.
- low_quality_samples: Holds the samples identified as having label issues, which can be reviewed further for potential corrections.
Step 5: Detect Noisy Labels via Model Prediction
This step involves using CleanLearning, a Cleanlab method, to detect noisy labels in the dataset by training a model and using its predictions to identify samples with inconsistent or noisy labels.
from cleanlab.classification import CleanLearning
from cleanlab.filter import find_label_issues
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import LabelEncoder
# Encode labels numerically
le = LabelEncoder()
df_clean['encoded_label'] = le.fit_transform(df_clean['sentiment'])
# Vectorize text data
vectorizer = TfidfVectorizer(max_features=3000)
X = vectorizer.fit_transform(df_clean['text']).toarray()
y = df_clean['encoded_label'].values
# Train classifier with CleanLearning
clf = LogisticRegression(max_iter=1000)
clean_model = CleanLearning(clf)
clean_model.fit(X, y)
# Get prediction probabilities
pred_probs = clean_model.predict_proba(X)
# Find noisy labels
noisy_label_indices = find_label_issues(labels=y, pred_probs=pred_probs)
# Show noisy label samples
noisy_label_samples = df_clean.iloc[noisy_label_indices]
print("Noisy Labels Detected:\n", noisy_label_samples.head())
- Label Encoding (LabelEncoder()): Converts string labels (e.g., “positive”, “negative”) into numerical values, making them suitable for machine learning models.
- Vectorization (TfidfVectorizer()): Converts text data into numerical features using TF-IDF, focusing on the 3,000 most important features from the “text” column.
- Train Classifier (LogisticRegression()): Uses logistic regression as the classifier for training the model with the encoded labels and vectorized text data.
- CleanLearning (CleanLearning()): Applies CleanLearning to the logistic regression model. This method refines the model’s ability to handle noisy labels by considering them during training.
- Prediction Probabilities (predict_proba()): After training, the model predicts class probabilities for each sample, which are used to identify potential noisy labels.
- find_label_issues(): Uses the predicted probabilities and the true labels to detect which samples have noisy labels (i.e., likely mislabels).
- Display Noisy Labels: Retrieves and displays the samples with noisy labels based on their indices, allowing you to review and potentially clean them.
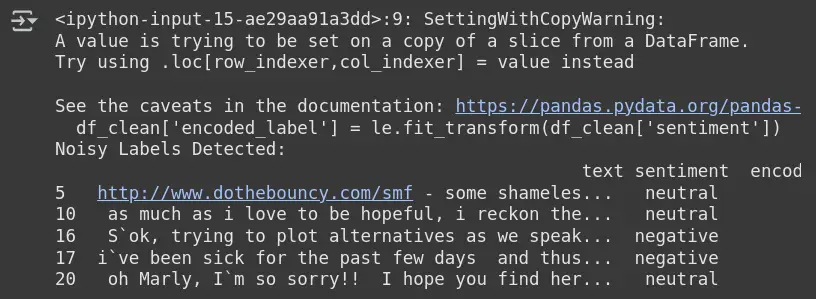
Observation
Output: Noisy Labels Detected
- Cleanlab flags samples where the predicted sentiment (from model) doesn’t match the provided label.
- Example: Row 5 is labeled neutral, but the model thinks it might not be.
- These samples are likely mislabeled or ambiguous based on model behaviour.
- It helps to identify, relabel, or remove problematic samples for better model performance.
Conclusion
Preprocessing is key to building reliable machine learning models. It removes inconsistencies, standardises inputs, and improves data quality. But most workflows miss one thing that is noisy labels. Cleanlab fills that gap. It detects mislabeled data, outliers, and low-quality samples automatically. No manual checks needed. This makes your dataset cleaner and your models smarter.
Cleanlab preprocessing doesn’t just boost accuracy, it saves time. By removing bad labels early, you reduce training load. Fewer errors mean faster convergence. More signal, less noise. Better models, less effort.
Frequently Asked Questions
Q1. What is Cleanlab used for?
Ans. Cleanlab helps detect and fix mislabeled, noisy, or low-quality data in labeled datasets. It’s useful across domains like text, image, and tabular data.
Q2. Does Cleanlab require model retraining?
Ans. No. Cleanlab works with the output of existing models. It doesn’t need retraining to detect label issues.
Q3. Do I need deep learning models to use Cleanlab?
Ans. Not necessarily. Cleanlab can be used with both traditional ML models and deep learning models, as long as you provide predicted probabilities.
Q4. Is Cleanlab easy to integrate into existing projects?
Ans. Yes, Cleanlab is designed for easy integration. You can quickly start using it with just a few lines of code, without major changes to your workflow.
Q5. What types of label noise does Cleanlab handle?
Ans. Cleanlab can handle various types of label noise, including mislabeling, outliers, and uncertain labels, making your dataset cleaner and more reliable for training models.
Hi, I'm Vipin. I'm passionate about data science and machine learning. I have experience in analyzing data, building models, and solving real-world problems. I aim to use data to create practical solutions and keep learning in the fields of Data Science, Machine Learning, and NLP.



