Trying to become a Data Scientist in 2026? With all the latest developments in the domain, it’s hard to keep track of the updates. And with so much information online, it might be overwhelming to get started on the right path. But fear not! This guide will provide all you need to know for becoming a Data Scientist. You’ll also get a schedule that you could stick to, to see through this process to fruition.
Table of contents
- Phase 1: The Foundation (Months 1-2)
- Phase 2: The Predictor – ML, DL & Transformers (Months 3-6)
- Phase 3: The Hybrid – RAG & Agents (Months 7-8)
- Phase 4: The Engineer – MLOps & Deployment (Months 9-10)
- Phase 5: The Specialist – Fine-Tuning & Tracks (Ongoing)
- The “Fast Track” Milestone Projects
- Conclusion
- Frequently Asked Questions
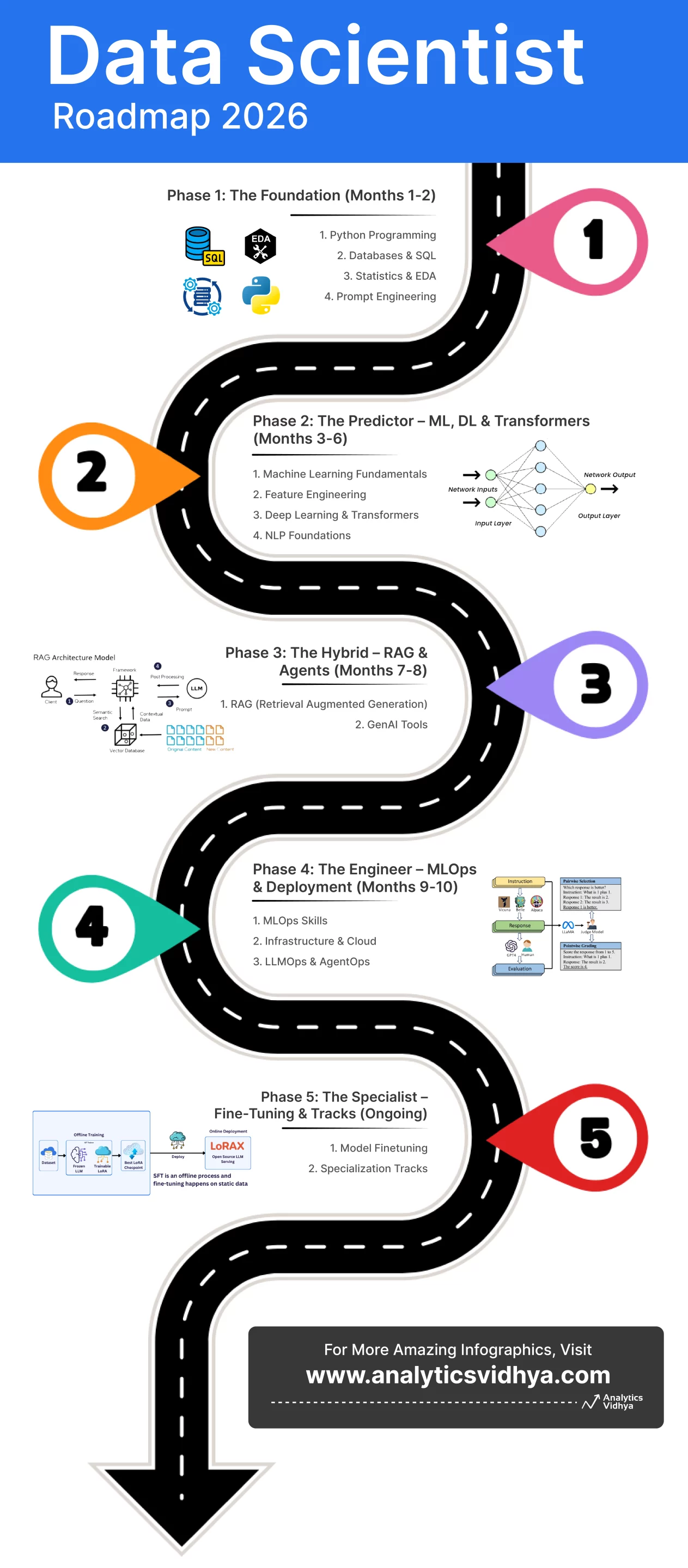
Don’t wanna read? You can skip past to the Data Scientist Roadmap shared at the end of this article, that sums up all that has been described within.
Phase 1: The Foundation (Months 1-2)
For the first two months, you’d be developing a foundation for Data Science.

1. Python Programming
Python is one of the simplest high-level languages that you can learn to create programs. You’d have to cover the language in the following manner:
- Basics: Variables, loops, functions, and OOP (classes, objects, methods).
- Data Science Stack: NumPy (numerical operations), Pandas (cleaning/manipulation), Matplotlib/Seaborn (visualizations).
- Code Quality: Writing modular and clean code.
- Expert Addition: Don’t just write code; prompt LLMs to write, optimize, and debug your Python scripts to double your speed.
If you are interested in learning Python from Scratch, with an emphasis on becoming a Data Scientist, then you can read this blog: Mastering Python
2. Databases & SQL
Having a sound understanding of databases is required for storing information properly. SQL or Structured Query Language is one of the best at doing just that. To get started, follow the following route:
- Master the fundamentals: SELECT, WHERE, GROUP BY, ORDER BY.
- Work with tables: Use JOINS (inner, left, right, full) to combine datasets.
- Optimization: SQL query optimization (indexing, execution order).
- Expert Addition: Learn to connect SQL directly with Python to build end-to-end data pipelines.
Read more: SQL: A Full Fledged Guide from Basics to Advance Level
3. Statistics & EDA
Having a fundamental understanding of statistical models and algorithms is required for becoming a Data Scientist. Make sure you have understand these:
- Descriptive Stats: Mean, Median, Mode, Distributions.
- Probability: Conditional probability and Bayes’ theorem.
- Hypothesis Testing: Significance testing, p-values, correlation vs. causation.
- Visualization: Histograms, Scatter plots, Box Plots, Line/Bar plots.
- Expert Addition: Don’t just show charts; use narratives and patterns to translate numbers into business impact.
Read more: EDA using Python
4. Prompt Engineering
Prompt engineering, even though missing for the traditional foundational stack, is a prerequisite for anything entering the domain in the following years.
- Text-to-Code: Write prompts to convert natural language queries into optimized SQL or Python/Pandas scripts.
- Data Wrangling: Instruct LLMs to generate Regex patterns for cleaning messy strings.
- Feature Ideation: Use prompts to brainstorm domain-specific feature transformations.
- Expert Addition: Prompt models to translate technical metrics (F1-score, AUC) into business summaries for stakeholders.
Read more: Practical Guide on Data Preprocessing and EDA
Bonus: A project on based End-to-end SQL + Python + EDA will help put these skills into practice.
Phase 2: The Predictor – ML, DL & Transformers (Months 3-6)

Descriptive analytics tells you what happened; predictive analytics tells you what will happen. This phase is the core engine of traditional Data Science, focusing on the mathematical rigor required to turn historical patterns into future intelligence.
1. Machine Learning Fundamentals
Before you touch a neural network, you must master the fundamentals. These algorithms are the workhorses of the industry, solving most of real-world business problems with speed, efficiency, and crucial interpretability. Knowing them by heart is required before moving ahead:
- Supervised Models: Linear/Logistic Regression, Decision Trees, Random Forests.
- The Workflow: Master train/validation/test splits and evaluation metrics.
- Gradient Boosting: The industry workhorses – XGBoost, LightGBM, CatBoost.
- Unsupervised: K-Means, Hierarchical Clustering, PCA (dimensionality reduction).
Also Read: Beginner’s Guide to Machine Learning Concepts and Techniques

2. Feature Engineering
Algorithms are only as good as the data you feed them. Feature engineering is the art of transforming raw noise into signals that models can actually understand, often making the difference between a mediocre model and a production-grade one. Go through the following disciplines to acquaint yourself with feature analysis:
- Image Preprocessing: Digital Image Processing operations and OpenCV basics.
- Time-series: Lag features, seasonality detection.
- Expert Addition: Learn content-based and collaborative filtering techniques.
Read more: Digital Image Processing using OpenCV
3. Deep Learning & Transformers
When data becomes unstructured, with filetypes such as images, text, audio, traditional ML fails. This is where you build the “brain,” utilizing deep architectures to capture complex, non-linear patterns that simple regression approaches can never see.
- Neural Networks: Layers, loss functions, activations.
- Architectures: Convolutional Neural Networks (Images), Recurrent Neural Networks (Time-series/Text).
- Transformers: Understand Encoders and Decoders.
- Expert Addition: Learn to take pre-trained models and adapt them to your specific data instead of training from scratch.
Checkout: Free course on NLP and DL
4. NLP (Natural Language Processing) Foundations
Text is the largest source of data in the world. Internet, which was the primary information source for training LLMs initially, is the largest public text library. Mastering NLP means unlocking the ability to quantify language, turning unstructured words into math that machines can process, analyze, and learn from.
- Text Features: Bag-of-Words, TF-IDF, Word2Vec.
- Embeddings: Master vector representations of text. Essential for working with vector databases.
Bonus: Creating a Multimodal ML system combining text + image models that is served via API, would provide sufficient challenge for the completion of this phase.
Phase 3: The Hybrid – RAG & Agents (Months 7-8)

The modern Data Scientist is a hybrid. You work isn’t limited to just predicting numbers! Rather you are generating content and answers. This phase bridges the gap between traditional information retrieval and the new wave of generative creativity.
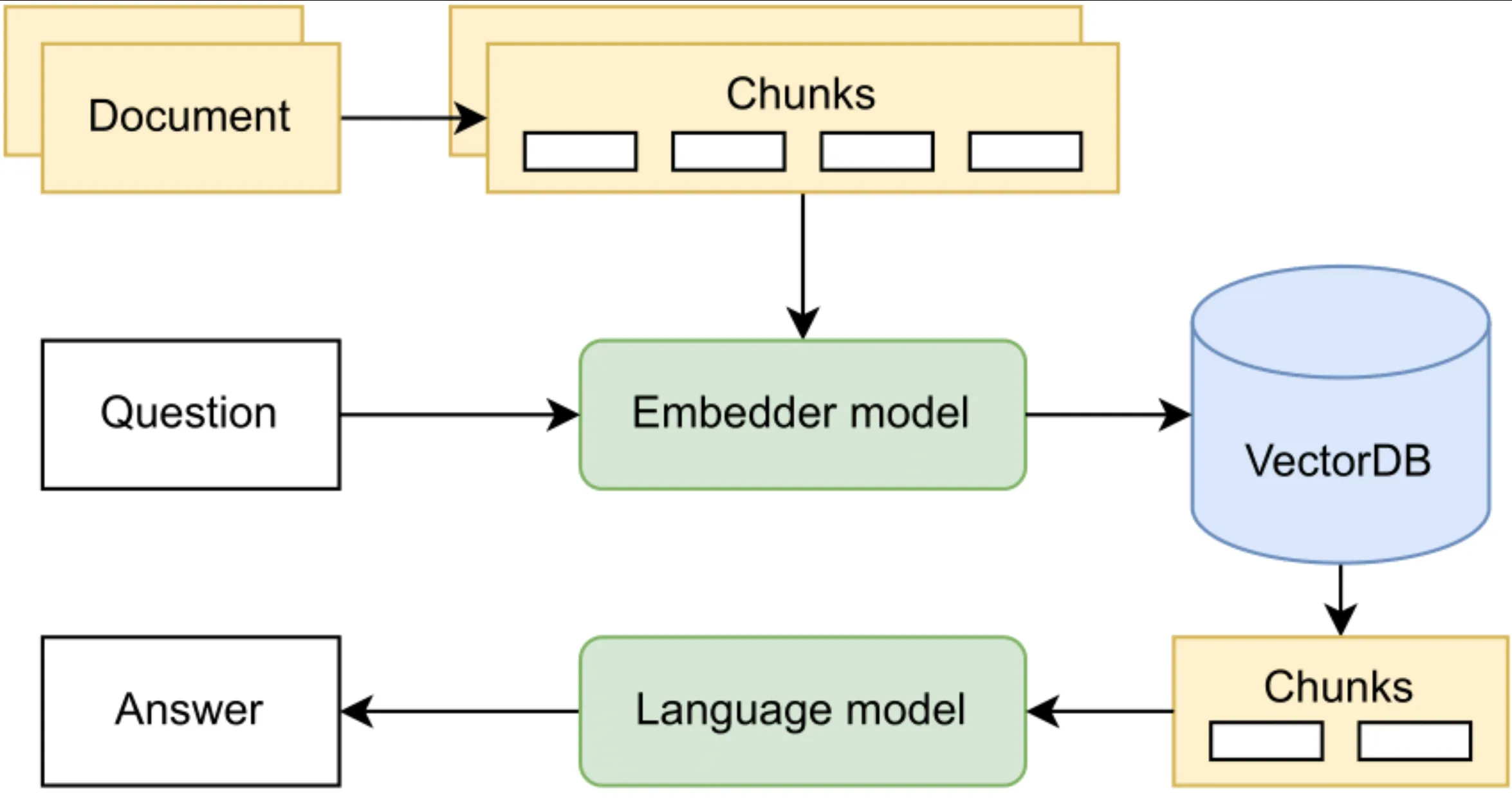
1. RAG (Retrieval Augmented Generation)
LLMs are powerful but unguided. RAG architecture connects a frozen model to your live, proprietary data, ensuring your AI knows your business, not just the generic internet.
- Vector Databases: FAISS, Chroma.
- Strategy: Chunking and document processing strategies.
- Optimization: Query rewriting and retrieval optimization.
- Expert Addition: Don’t guess; use metrics for grounding, faithfulness, and relevance to score your system.
2. AI Agents
Chatbots talk, but Agents act. This marks the shift from passive information retrieval to active task execution, allowing AI to use tools, browse the web, and solve multi-step problems autonomously.
- ReAct Pattern: Reasoning + Action based planning.
- Tool Calling: Giving the AI the ability to execute external actions (APIs, search).
- Orchestration: Multi-agent architectures where agents talk to agents.
3. GenAI Tools
You wouldn’t build a website in assembly, and you shouldn’t build agents from scratch. These frameworks are the scaffolding that lets you prototype complex cognitive architectures in hours rather than weeks.
- LangChain: For building pipelines.
- LangGraph: For defining complex agent state machines.
- Expert Addition: Use it for tracing, debugging, and evaluating agent performance in real-time.
Also Read: Generative AI Roadmap 2026
Bonus: Developing a “Chat with your Company Policy” tool using RAG and ChromaDB, would put to test all that you’ve learned in this phrase.
Phase 4: The Engineer – MLOps & Deployment (Months 9-10)

A model that just sits on a laptop, creates zero value. This phase is about the rigorous engineering required to take a fragile script and turn it into a robust, scalable system that serves thousands of users without crashing.
1. MLOps Skills
Data science is experimental, but production is engineering. MLOps brings the discipline of DevOps to machine learning, ensuring reproducibility, versioning, and stability in a field known for chaos.
- Tracking: Use MLflow or Weights & Biases to track experiments.
- Versioning: DVC for data; Model Registry for models.
- CI/CD: Automate your ML pipelines.
2. Infrastructure & Cloud
Your model needs a home that scales. Understanding containers and cloud infrastructure is what separates a hobbyist from a professional who can deploy their work anywhere, anytime and to any number of people.
- Containerization: Docker is mandatory.
- APIs: FastAPI or Flask to serve your models.
- Cloud: AWS/Azure basics (EC2, S3, Lambda).
- Expert Addition: Don’t just deploy; track drift, latency, and accuracy in production.
3. LLMOps & AgentOps
Deterministic code is easy to monitor; probabilistic AI is not. This emerging field focuses on the unique challenges of keeping erratic LLMs and agents safe, reliable, and cost-effective in the wild.
- Guardrails: Implement safety layers to prevent hallucinations.
- Reliability: Build retries, memory management, and failure recovery for agents.
- Expert Addition:Telemetry for vector databases and agent workflows.
Also Read: LLMOps for Machine Learning
Bonus: An Autonomous Travel Planning Agent using LangGraph that searches live flights/hotels. This would prove possible while offering challenge if you’ve went through this phase.
Phase 5: The Specialist – Fine-Tuning & Tracks (Ongoing)

Generalists are good, but specialists get paid. Once you have the breadth, you need the depth. This phase is about picking a lane and becoming the undeniable expert in a specific domain.
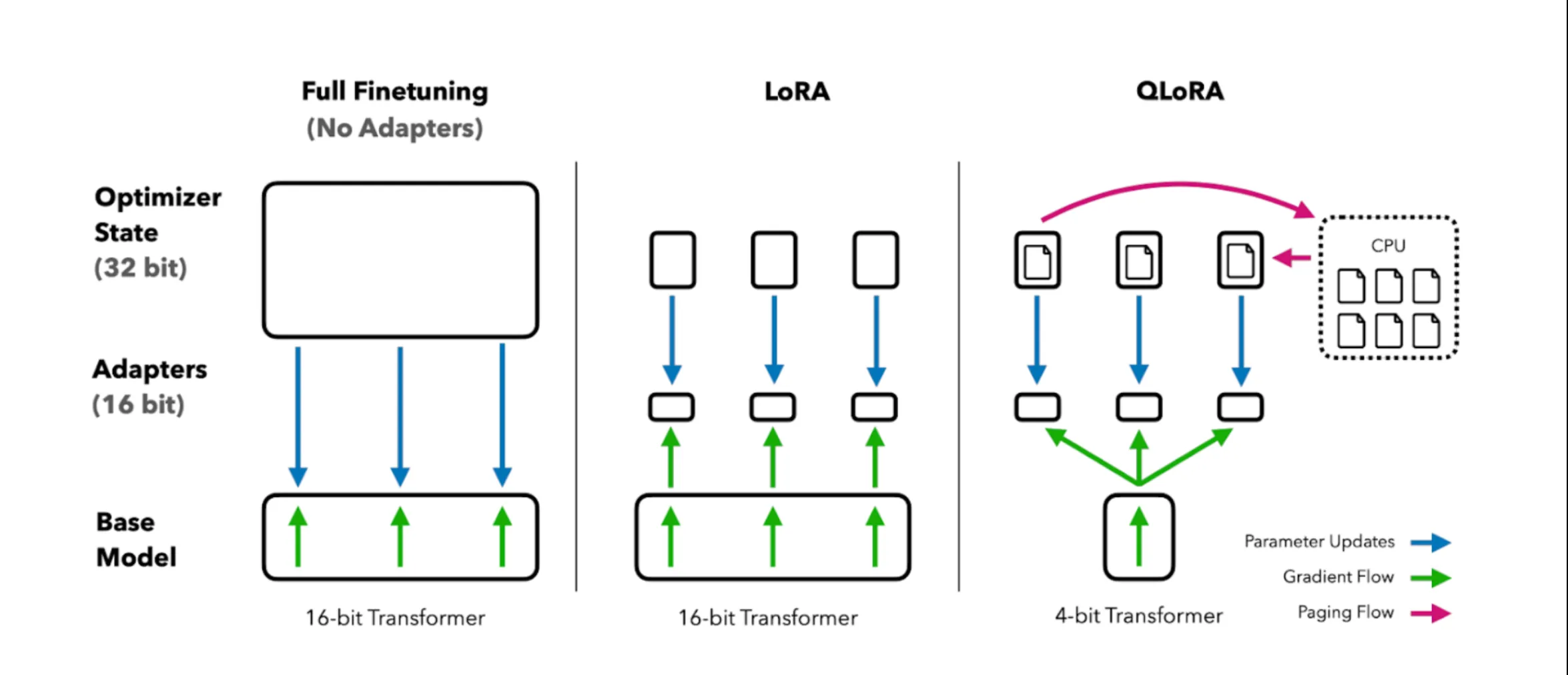
1. Model Finetuning
Prompting has a ceiling. Fine-tuning is how you shatter that ceiling, rewriting the model’s internal weights to behave exactly how your specific domain demands, creating assets that general models can’t touch.
- Techniques: LoRA, QLoRA, and PEFT frameworks.
- Data: Dataset preparation is 80% of the work.
- Evaluation: Safety checks for tuned models.
2. Specialization Tracks
Data Science is too big to master everything. Whether it’s vision, forecasting, or language, choosing a track allows you to focus your energy and build a portfolio that stands out in a crowded market.
- NLP Specialization: Advanced text processing.
- Computer Vision: Advanced image/video analysis.
- Time-Series: Advanced forecasting.
- Agentic Systems: Complex multi-agent swarms.
The “Fast Track” Milestone Projects
Knowing all there is to Data Science doesn’t suffice. You need to progress till the end, in a measurable manner. To stay motivated, build these 5 projects as you learn more:
- Project Alpha (Foundation): End-to-end SQL + Python + EDA project with insights and LLM-supported executive summaries.
- Project Beta (Prediction): A Multimodal ML system combining text + image models served via API.
- Project Gamma (RAG): A “Chat with your Company Policy” tool using RAG and ChromaDB.
- Project Delta (Agents): An Autonomous Travel Planning Agent using LangGraph that searches live flights/hotels.
And to top it off:
- Capstone (Production): A Cloud-hosted RAG system with FastAPI backend, vector DB, LangSmith tracing, and full CI/CD. This would be an apt finale for your journey to becoming a Data Scientist, a culmination and test of what you had learnt throughout the way.
Doing these projects would not only build momentum, but would give you the experience required for assuming the position of a Data Scientist.
Conclusion
If you take this roadmap even mostly seriously, you won’t just learn data science—you’ll push past those limited to traditional materials. This path is built to turn you into someone teams would want to hire, founders would want to work with, and investors keep an eye on. The future will be shaped by people who understand math, know how to work with models, build agents, fine-tune them, and ship systems that actually scale. You now have the blueprint. The only part no roadmap can give you is the discipline to show up every day and level up with intent. But a graphic outlining the same would for sure help:
Frequently Asked Questions
Q1. What’s the main goal of this 2026 learning path?
A. To take you from beginner to a job-ready data scientist who can build models, deploy systems, work with LLMs, and design agents, not just analyze data.
Q2. How long does the roadmap take to complete?
A. About a year. The schedule is split into focused phases covering foundations, ML, deep learning, RAG, agents, MLOps, and specialization.
Q3. What projects should I build while learning?
A. Five milestone projects: an end-to-end analytics project, a multimodal ML system, a RAG app, an autonomous agent, and a full production-grade deployment.
I specialize in reviewing and refining AI-driven research, technical documentation, and content related to emerging AI technologies. My experience spans AI model training, data analysis, and information retrieval, allowing me to craft content that is both technically accurate and accessible.






