One of the best-performing algorithms in machine learning is the boosting algorithm. These are characterised by good predictive abilities and accuracy. All the methods of gradient boosting are based on a universal notion. They get to learn through the errors of the former models. Each new model is aimed at correcting the previous mistakes. This way, a weak group of learners is turned into a powerful team in this process.
This article compares 5 popular techniques of boosting. These are Gradient Boosting, AdaBoost, XGBoost, CatBoost, and LightGBM. It describes the way every technique functions and shows major differences, including their strengths and weaknesses. It also addresses the usage of both methods. There are performance benchmarks and code samples.
Table of contents
Introduction to Boosting
Boosting is a method of ensemble learning. It fuses several weak learners with frequent shallow decision trees into a strong model. The models are trained sequentially. Every new model dwells upon the mistakes committed by the former one. You can learn all about boosting algorithms in machine learning here.
It begins with a basic model. In regression, it can be used to forecast the average. Residuals are subsequently obtained by determining the difference between the actual and predicted values. These residuals are predicted by training a new weak learner. This assists in the rectification of past errors. The procedure is repeated until minimal errors are attained or a stop condition is achieved.
This idea is used in various boosting methods differently. Some reweight data points. Others minimise a loss function by gradient descent. Such differences influence performance and flexibility. The ultimate prediction is, in any case, a weighted average of all weak learners.
AdaBoost (Adaptive Boosting)
One of the first boosting algorithms is AdaBoost. It was developed in the mid-1990s. It builds models step by step. Every successive model is dedicated to the errors made in the earlier theoretical models. The point is that there is adaptive reweighting of data points.
How It Works (The Core Logic)
AdaBoost works in a sequence. It doesn’t train models all at once; it builds them one by one.
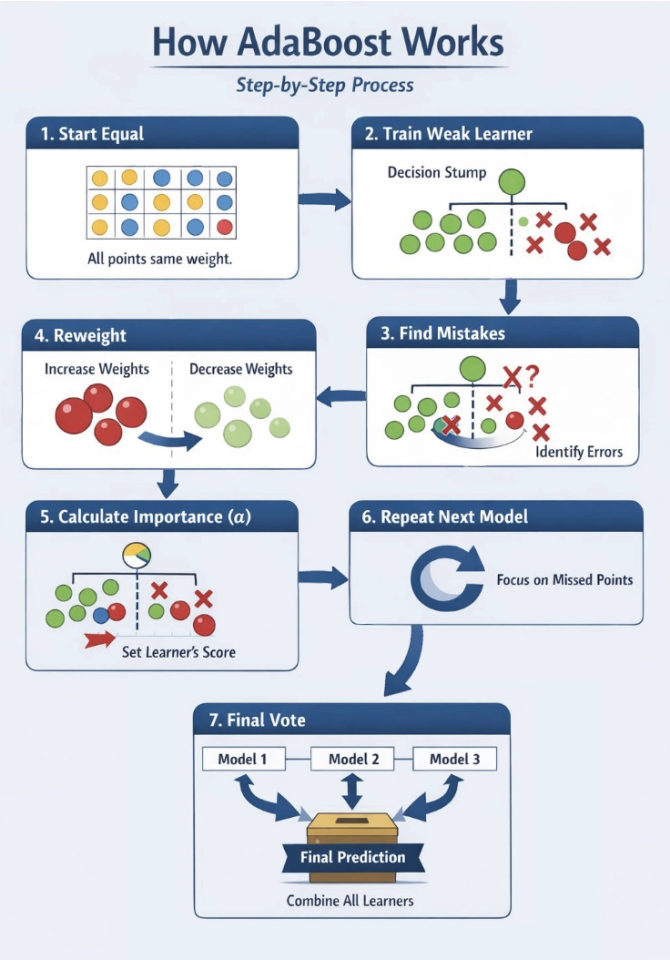
- Start Equal: Give every data point the same weight.
- Train a Weak Learner: Use a simple model (usually a Decision Stump—a tree with only one split).
- Find Mistakes: See which data points the model got wrong.
- Reweight:
Increase weights for the “wrong” points. They become more important.
Decrease weights for the “correct” points. They become less important. - Calculate Importance (alpha): Assign a score to the learner. More accurate learners get a louder “voice” in the final decision.
- Repeat: The next learner focuses heavily on the points previously missed.
- Final Vote: Combine all learners. Their weighted votes determine the final prediction.
Strengths & Weaknesses
| Strengths | Weaknesses |
|---|---|
| Simple: Easy to set up and understand. | Sensitive to Noise: Outliers get huge weights, which can ruin the model. |
| No Overfitting: Resilient on clean, simple data. | Sequential: It’s slow and cannot be trained in parallel. |
| Versatile: Works for both classification and regression. | Outdated: Modern tools like XGBoost often outperform it on complex data. |
Gradient Boosting (GBM): The “Error Corrector”
Gradient Boosting is a powerful ensemble method. It builds models one after another. Each new model tries to fix the mistakes of the previous one. Instead of reweighting points like AdaBoost, it focuses on residuals (the leftover errors).
How It Works (The Core Logic)
GBM uses a technique called gradient descent to minimize a loss function.
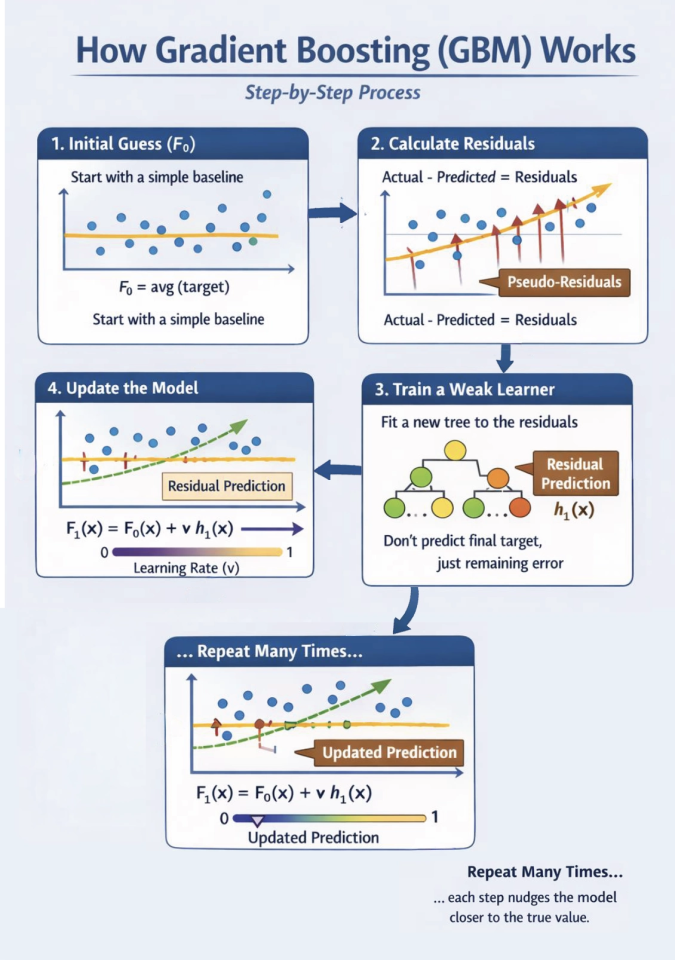
- Initial Guess (F0): Start with a simple baseline. Usually, this is just the average of the target values.
- Calculate Residuals: Find the difference between the actual value and the current prediction. These “pseudo-residuals” represent the gradient of the loss function.
- Train a Weak Learner: Fit a new decision tree (hm) specifically to predict those residuals. It isn’t trying to predict the final target, just the remaining error.
- Update the Model: Add the new tree’s prediction to the previous ensemble. We use a learning rate (v) to prevent overfitting.
- Repeat: Do this many times. Each step nudges the model closer to the true value.
Strengths & Weaknesses
| Strengths | Weaknesses |
|---|---|
| Highly Flexible: Works with any differentiable loss function (MSE, Log-Loss, etc.). | Slow Training: Trees are built one by one. It is hard to run in parallel. |
| Superior Accuracy: Often beats other models on structured/tabular data. | Data Prep Required: You must convert categorical data to numbers first. |
| Feature Importance: It’s easy to see which variables are driving predictions. | Tuning Sensitive: Requires careful tuning of learning rate and tree count. |
XGBoost: The “Extreme” Evolution
XGBoost stands for eXtreme Gradient Boosting. It is a faster, more accurate, and more robust version of Gradient Boosting (GBM). It became famous by winning many Kaggle competitions. You can learn all about it here.
Key Enhancements (Why it’s “Extreme”)
Unlike standard GBM, XGBoost includes smart math and engineering tricks to improve performance.
- Regularization: It uses $L1$ and $L2$ regularization. This penalizes complex trees and prevents the model from “overfitting” or memorizing the data.
- Second-Order Optimization: It uses both first-order gradients and second-order gradients (Hessians). This helps the model find the best split points much faster.
- Smart Tree Pruning: It grows trees to their maximum depth first. Then, it prunes branches that don’t improve the score. This “look-ahead” approach prevents useless splits.
- Parallel Processing: While trees are built one after another, XGBoost builds the individual trees by looking at features in parallel. This makes it incredibly fast.
- Missing Value Handling: You don’t need to fill in missing data. XGBoost learns the best way to handle “NaNs” by testing them in both directions of a split.
Strengths & Weaknesses
| Strengths | Weaknesses |
|---|---|
| Top Performance: Often the most accurate model for tabular data. | No Native Categorical Support: You must manually encode labels or one-hot vectors. |
| Blazing Fast: Optimized in C++ with GPU and CPU parallelization. | Memory Hungry: Can use a lot of RAM when dealing with massive datasets. |
| Robust: Built-in tools handle missing data and prevent overfitting. | Complex Tuning: It has many hyperparameters (like eta, gamma, and lambda). |
LightGBM: The “High-Speed” Alternative
LightGBM is a gradient boosting framework released by Microsoft. It is designed for extreme speed and low memory usage. It is the go-to choice for massive datasets with millions of rows.
Key Innovations (How It Saves Time)
LightGBM is “light” because it uses clever math to avoid looking at every piece of data.
- Histogram-Based Splitting: Traditional models sort every single value to find a split. LightGBM groups values into “bins” (like a bar chart). It only checks the bin boundaries. This is much faster and uses less RAM.
- Leaf-wise Growth: Most models (like XGBoost) grow trees level-wise (filling out an entire horizontal row before moving deeper). LightGBM grows leaf-wise. It finds the one leaf that reduces error the most and splits it immediately. This creates deeper, more efficient trees.
- GOSS (Gradient-Based One-Side Sampling): It assumes data points with small errors are already “learned.” It keeps all data with large errors but only takes a random sample of the “easy” data. This focuses the training on the hardest parts of the dataset.
- EFB (Exclusive Feature Bundling): In sparse data (lots of zeros), many features never occur at the same time. LightGBM bundles these features together into one. This reduces the number of features the model has to process.
- Native Categorical Support: You don’t need to one-hot encode. You can tell LightGBM which columns are categories, and it will find the best way to group them.
Strengths & Weaknesses
| Strengths | Weaknesses |
|---|---|
| Fastest Training: Often 10x–15x faster than original GBM on large data. | Overfitting Risk: Leaf-wise growth can overfit small datasets very quickly. |
| Low Memory: Histogram binning compresses data, saving huge amounts of RAM. | Sensitive to Hyperparameters: You must carefully tune num_leaves and max_depth. |
| Highly Scalable: Built for big data and distributed/GPU computing. | Complex Trees: Resulting trees are often lopsided and harder to visualize. |
CatBoost: The “Categorical” Specialist
CatBoost, developed by Yandex, is short for Categorical Boosting. It is designed to handle datasets with many categories (like city names or user IDs) natively and accurately without needing heavy data preparation.
Key Innovations (Why It’s Unique)
CatBoost changes both the structure of the trees and the way it handles data to prevent errors.
- Symmetric (Oblivious) Trees: Unlike other models, CatBoost builds balanced trees. Every node at the same depth uses the exact same split condition.
Benefit: This structure is a form of regularization that prevents overfitting. It also makes “inference” (making predictions) extremely fast. - Ordered Boosting: Most models use the entire dataset to calculate category statistics, which leads to “target leakage” (the model “cheating” by seeing the answer early). CatBoost uses random permutations. A data point is encoded using only the information from points that came before it in a random order.
- Native Categorical Handling: You don’t need to manually convert text categories to numbers.
– Low-count categories: It uses one-hot encoding.
– High-count categories: It uses advanced target statistics while avoiding the “leaking” mentioned above. - Minimal Tuning: CatBoost is famous for having excellent “out-of-the-box” settings. You often get great results without touching the hyperparameters.
Strengths & Weaknesses
| Strengths | Weaknesses |
|---|---|
| Best for Categories: Handles high-cardinality features better than any other model. | Slower Training: Advanced processing and symmetric constraints make it slower to train than LightGBM. |
| Robust: Very hard to overfit thanks to symmetric trees and ordered boosting. | Memory Usage: It requires a lot of RAM to store categorical statistics and data permutations. |
| Lightning Fast Inference: Predictions are 30–60x faster than other boosting models. | Smaller Ecosystem: Fewer community tutorials compared to XGBoost. |
The Boosting Evolution: A Side-by-Side Comparison
Choosing the right boosting algorithm depends on your data size, feature types, and hardware. Below is a simplified breakdown of how they compare.
Key Comparison Table
| Feature | AdaBoost | GBM | XGBoost | LightGBM | CatBoost |
|---|---|---|---|---|---|
| Main Strategy | Reweights data | Fits to residuals | Regularized residuals | Histograms & GOSS | Ordered boosting |
| Tree Growth | Level-wise | Level-wise | Level-wise | Leaf-wise | Symmetric |
| Speed | Low | Moderate | High | Very High | Moderate (High on GPU) |
| Cat. Features | Manual Prep | Manual Prep | Manual Prep | Built-in (Limited) | Native (Excellent) |
| Overfitting | Resilient | Sensitive | Regularized | High Risk (Small Data) | Very Low Risk |
Evolutionary Highlights
- AdaBoost (1995): The pioneer. It focused on hard-to-classify points. It is simple but slow on big data and lacks modern math like gradients.
- GBM (1999): The foundation. It uses calculus (gradients) to minimize loss. It is flexible but can be slow because it calculates every split exactly.
- XGBoost (2014): The game changer. It added Regularization ($L1/L2$) to stop overfitting. It also introduced parallel processing to make training much faster.
- LightGBM (2017): The speed king. It groups data into Histograms so it doesn’t have to look at every value. It grows trees Leaf-wise, finding the most error-reducing splits first.
- CatBoost (2017): The category master. It uses Symmetric Trees (every split at the same level is the same). This makes it extremely stable and fast at making predictions.
When to Use Which Method
The following table clearly marks when to use which method.
| Model | Best Use Case | Pick It If | Avoid It If |
|---|---|---|---|
| AdaBoost | Simple problems or small, clean datasets | You need a fast baseline or high interpretability using simple decision stumps | Your data is noisy or contains strong outliers |
| Gradient Boosting (GBM) | Learning or medium-scale scikit-learn projects | You want custom loss functions without external libraries | You need high performance or scalability on large datasets |
| XGBoost | General-purpose, production-grade modeling | Your data is mostly numeric and you want a reliable, well-supported model | Training time is critical on very large datasets |
| LightGBM | Large-scale, speed- and memory-sensitive tasks | You are working with millions of rows and need rapid experimentation | Your dataset is small and prone to overfitting |
| CatBoost | Datasets dominated by categorical features | You have high-cardinality categories and want minimal preprocessing | You need maximum CPU training speed |
Pro Tip: Many competition-winning solutions don’t choose just one. They use an Ensemble averaging the predictions of XGBoost, LightGBM, and CatBoost to get the best of all worlds.
Conclusion
Boosting algorithms transform weak learners into strong predictive models by learning from past errors. AdaBoost introduced this idea and remains useful for simple, clean datasets, but it struggles with noise and scale. Gradient Boosting formalized boosting through loss minimization and serves as the conceptual foundation for modern methods. XGBoost improved this approach with regularization, parallel processing, and strong robustness, making it a reliable all-round choice.
LightGBM optimized speed and memory efficiency, excelling on very large datasets. CatBoost solved categorical feature handling with minimal preprocessing and strong resistance to overfitting. No single method is best for all problems. The optimal choice depends on data size, feature types, and hardware. In many real-world and competition settings, combining multiple boosting models often delivers the best performance.
Hi, I am Janvi, a passionate data science enthusiast currently working at Analytics Vidhya. My journey into the world of data began with a deep curiosity about how we can extract meaningful insights from complex datasets.






