This article was published as a part of the Data Science Blogathon.
Introduction on Apache Cassandra
Apache Cassandra is a scalable database intended to manage massive volumes of data over many commodity computers while maintaining high availability and avoiding a unique failure point. It has high performance, and it is a NO-SQL database. Before understanding Apache Cassandra, let us first understand what a No-SQL database is. Databases are divided into two types: SQL Databases and No-SQL Databases. SQL databases have a set format. On the other hand, SQL databases do not have a set format and follow different methods of storing data.
A database is a collection of data that has been organized systematically. They allow for electronic data storage and manipulation, and data handling is simplified thanks to databases.
No-SQL Database
A NoSQL database, which stands for non SQL or non-relational, is a database that provides a system for data storage and retrieval. This data is represented in ways other than tabular relations seen in relational databases.
NoSQL systems are sometimes known as non-relational databases. Not just SQL is mentioned to stress that they may support query languages similar to SQL.
Design simplicity, horizontal scaling to clusters of computers, and more control over availability are all advantages of a NoSQL database. Data structures used by NoSQL databases differ from those used by relational databases by default, allowing NoSQL to perform some operations more quickly. The problem determines the applicability of a NoSQL database it is supposed to answer, and NoSQL databases’ data design is sometimes more flexible than relational database tables.
Many NoSQL databases compromise consistency, availability, performance, and partition tolerance. Low-level query languages, a lack of standardised interfaces, and huge past investments in relational databases are all stumbling blocks to NoSQL storage adoption.
Benefits of Using a No-SQL Database
- For horizontal scaling, NoSQL databases employ sharding. Sharding is the process of partitioning data and distributing it over numerous machines while maintaining the data’s order. Horizontal scaling entails adding new devices to handle the data, and vertical scaling adds more resources to the present machine.
- Vertical scaling is challenging to execute, whereas horizontal scaling is straightforward. MongoDB, Cassandra, and other flat scaling databases are examples. Because of its scalability, NoSQL can manage large amounts of data, and as the data expands, NoSQL scales to accommodate it efficiently.
- Because they don’t employ a schema and aren’t relational, NoSQL databases are essentially freeform. This NoSQL characteristic is related to design rather than a single language intended to deal with database administration; therefore, depending on your needs, you may utilise a variety of data models with NoSQL.
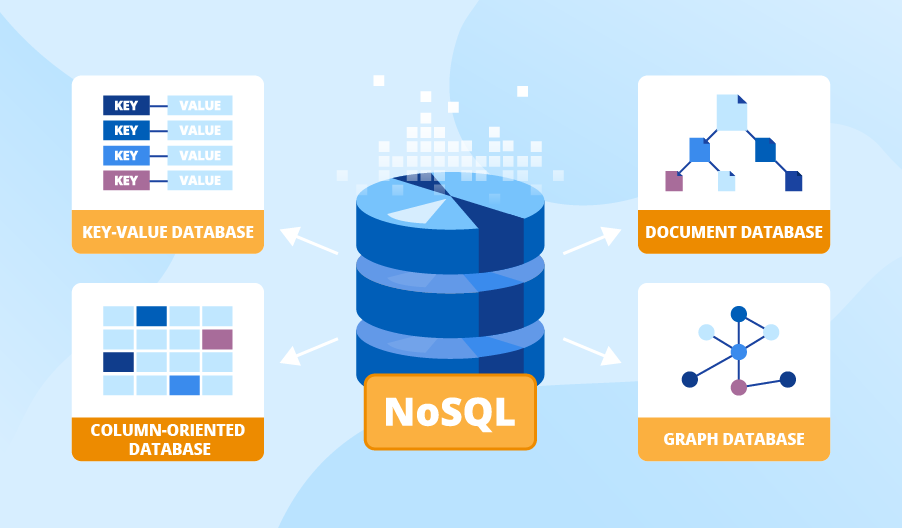
Types of No-SQL Databases
There are four types of NoSQL databases: key-value pair, column-oriented, graph-based, and document-oriented. Each category has its own set of characteristics and limits. None of the databases listed above is superior at solving all of the difficulties. Users should choose a database that meets their product requirements.
What is Apache Cassandra?
Apache Cassandra is an open-source, decentralised/distributed storage system (database) for handling massive volumes of structured data scattered over the globe. There is no single point of failure, making it a highly available service.
Facebook created Cassandra for use in their inbox search tool. Facebook open-sourced Cassandra in 2008, and it joined the Apache Incubator in 2009. It has been a top-level Apache project since early 2010. It’s now a significant component of the Apache Software Foundation, and anyone who wants to profit from it can use it.
Cassandra is a database system that stands out among others and has several benefits over others. Its capacity to manage large volumes makes it especially useful for big businesses. As a result, several giant corporations, including Apple, Facebook, Instagram, Uber, Spotify, Twitter, Cisco, Rackspace, eBay, and Netflix, are now using it.

Importance of Cassandra
Cassandra is essential and is used in many large corporations. Why is Cassandra so important:
- Cassandra is a NoSQL database that is both efficient and extensively utilised. One of the system’s main advantages is that it provides highly available service with no single point of failure. This is critical for firms that cannot afford to lose data or have their system go down, and it provides constant access and availability since there is no single point of failure.
- Another essential feature of Cassandra is its ability to manage large amounts of data. It can manage massive volumes of data across several servers effectively and efficiently, and it can also write large volumes of data quickly without reducing read efficiency.
- Its structure allows users to meet sudden increases in demand, as it allows users to add more hardware to accommodate additional customers and data. This makes it easy to scale without shutdowns or significant adjustments needed. Additionally, its linear scalability is one of the things that helps to maintain the system’s quick response time.
- Cassandra can handle structured, semi-structured, and unstructured data, giving users flexibility with data storage. Cassandra uses multiple data centres, allowing easy data distribution wherever or whenever needed. The properties of ACID (atomicity, consistency, isolation, and durability) are supported by Cassandra.
Cassandra Database
Worldwide data distribution and its requirements were noted in the Cassandra whitepaper, and the ability to duplicate and distribute data between data centres was critical for keeping search latencies low.
Handling failure was one of its design assumptions. Failure was not merely a chance occurrence; it was a permanent problem brought on by ongoing expansion: “Dealing with breakdowns in an infrastructure made up of thousands of components is our usual way of operation… As a result, software systems must be built so that failures are treated as the standard rather than the exception.
Another important Cassandra design feature was the ability to auto-partition data for progressive scaling. The system would be able to add additional nodes to the cluster and rebalance data across the board.
Cassandra introduced automatic peer-to-peer replication to make the system extraordinarily available and assure data durability. With many copies of the same data saved across nodes (data duplication), data would persist even if a few nodes were lost. Furthermore, no one node could be knocked out because the system was peer-to-peer, rendering the system unusable. There was no single point of failure since each transaction used a separate coordinator node.
Cassandra’s ability to store data was also a crucial feature. The system depended on writing files to disc in an immutable (unalterable) state rather than continually updating big monolithic, mutable (alterable) data files. If the data for a specific database record changed, the update would be written to a new immutable file instead. Compaction gathers a number of these immutable files (each of which may have redundant or obsolete data) and writes out a new single composite table file of the most recent data triggered by the periodic, size, or modification rate of the files. Sorted Strings Tables, or SSTables, is the format of these immutable data files.
How Does Cassandra Work?
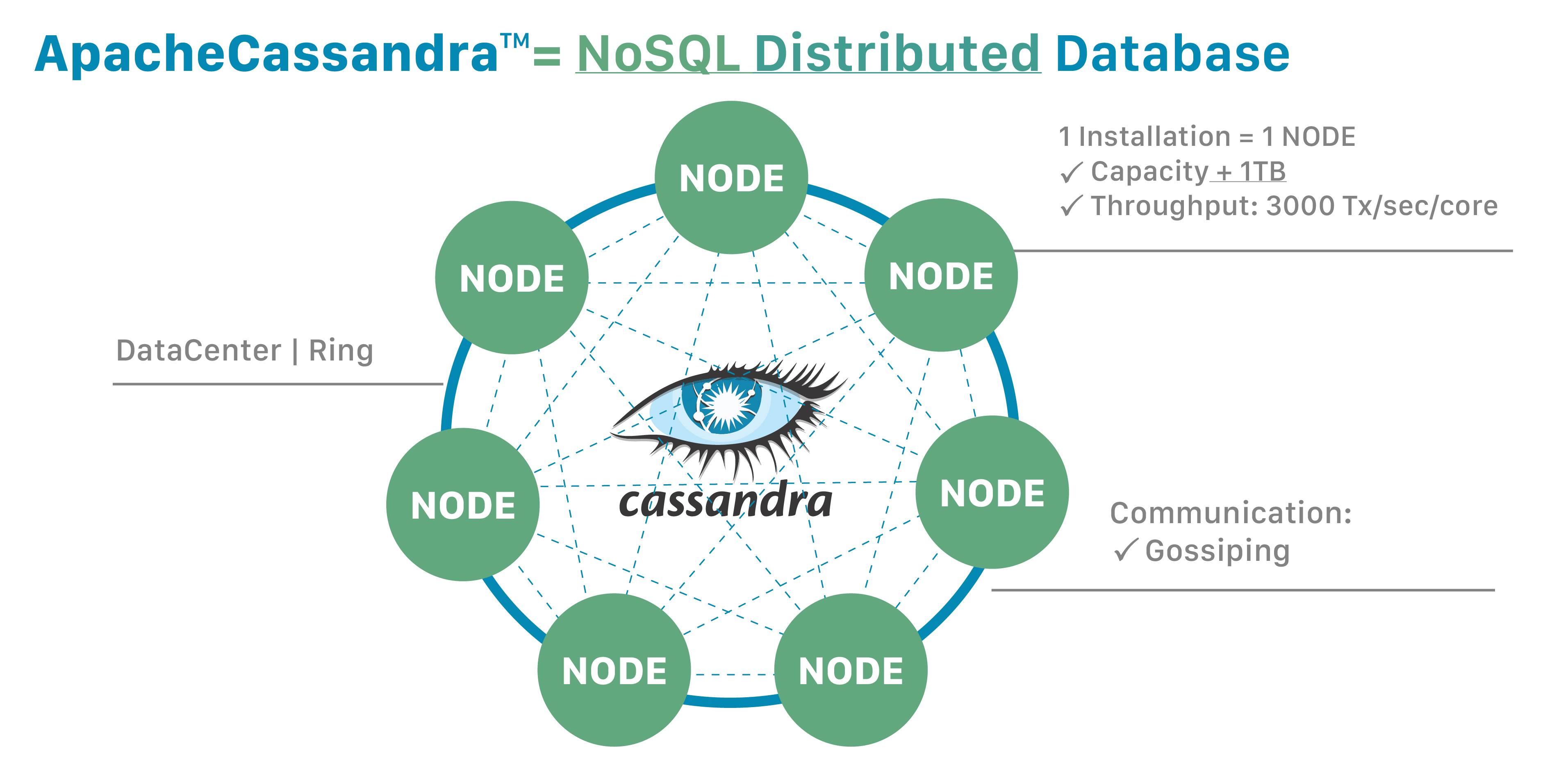
The basic architecture concepts for Cassandra are scalability, performance, and continuous availability. Cassandra has a masterless ring architecture, which doesn’t have a master-slave relationship.
All nodes in Cassandra serve the same purpose; there is no idea of a controller node, and all nodes communicate with one another via a distributed, scalable protocol. Reads are channelled onto specified nodes, and writes are dispersed across nodes using a hash function.
Cassandra stores data by equally distributing it among its cluster of nodes. Each node is in charge of a portion of the data, and data partitioning is the process of spreading data among nodes.
Data Modelling in Cassandra
Cassandra is a column store database with a large number of columns. It uses a partitioned row store with configurable consistency as its data model. Rows are arranged into tables; the partition key is the first component of a table’s primary key; rows are clustered inside a partition by the remaining columns of the key. In addition to the primary key, other columns may be indexed individually. Tables can be created, discarded, and changed at runtime without affecting updates or queries.
Joins and subqueries are not possible in Cassandra. On the other hand, Cassandra encourages denormalisation with features such as collections. In an RDBMS, a column family (named “table” from CQL3) resembles a table. Rows and columns are contained in column families, and a row key identifies each row individually. There are numerous columns in each row, each with a name, value, and timestamp. Different rows in the same column family do not have to share the same set of columns, and a column can be added to one or many rows at any moment, unlike a table in an RDBMS.
Cassandra CQL
Cassandra has a Cassandra query language shell (cqlsh) that users may use to connect with it. We may use this shell to run Cassandra Query Language (CQL). CQL is a typed language that supports various data types, including native, collection, user-defined, tuple, and custom data types.
CQL stores data in tables with rows and columns, just like SQL. Many interactions and implementations are similar, such as getting all the rows in a database and controlling entity rights and resources. CQL should be simple if you know how to use SQL commands like SELECT, INSERT, UPDATE, and DELETE.
However, there are some differences. In SQL, for example, a column may be used in the WHERE clause, but only columns that are rigorously defined in the primary key can be used as a limiting column in CQL. In addition, each query must have at least one partition key declared in CQL.
Conclusion on Apache Cassandra
We analysed the need and use of No-SQL databases and how they compare to SQL databases. In many cases, No-SQL databases have clear benefits. Cassandra is an excellent example of a No-SQL database, and Cassandra provides many benefits to the organisation using it. We had a look at the features of the Cassandra database. To sum it up:
- Apache Cassandra is a scalable database system. It allows a company to expand its hardware to suit the growing data demands of a specific industry.
-
The absence of a master-slave paradigm characterises decentralisation. There isn’t a single weak point in this. Every node in this system has the potential to deliver a whole or partial duplicate of the database to a user. As a result of the decentralisation process, there will be no network congestion or bottlenecks, and each node in the cluster will be identical.
- Apache Cassandra allows you to distribute data rapidly, reliably, and quickly. Cassandra cluster configuration and tuning enable users to distribute data in whatever way they wish
- Apache Cassandra is already fault-tolerant, but it also boasts a long lifespan. It’s shown promise, especially for applications that rely on data and can’t afford to lose it.
Apache Cassandra is a fantastic database to use. Decentralisation, data dispersion, scalability, and availability, to name a few, are all features and services that may be incredibly valuable to a business.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Prateek is a dynamic professional with a strong foundation in Artificial Intelligence and Data Science, currently pursuing his PGP at Jio Institute. He holds a Bachelor's degree in Electrical Engineering and has hands-on experience as a System Engineer at TCS Digital, where he excelled in API management and data integration. Prateek also has a background in product marketing and analytics from his time with start-ups like AppleX and Milkie Way, Inc., where he was involved in growth campaigns and technical blog management. Recognized for his structured thinking and problem-solving abilities, he has received accolades like the Dr. Sudarshan Chakraborty Award for Best Student Performance. Fluent in multiple languages and passionate about technology, Prateek continues to expand his expertise in the rapidly evolving AI and tech landscape.






