Overview
- Presenting the top three winning solutions and approaches from the LTFS Data Science FinHack 2
- The problem statement for this hackathon was from the finance industry and geared towards predicting the number of loan applications received
The Power of Data Science Hackathons
I love participating in data science hackathons primarily for two key reasons:
- I get to learn A LOT. The top winning solutions and approaches typically engineer new ways to climb up the leaderboard. This varies from feature engineering to new takes on traditional machine learning algorithms. Whatever the case, they bring a fresh perspective to my learning journey
- Data science hackathons are easily the best medium for evaluating yourself. We get to challenge and pit our knowledge against the top minds in data science. I always take a step back and evaluate my own performance against the top winning solutions
That second point is a key reason why we publish winning solutions and approaches to our hackathons. Our community loves to pour through these winning solutions, understand the thought process of the winners, and incorporate that into their own hackathon framework.

I am excited to bring forward the top three winning solutions and approaches from the LTFS Data Science FinHack 2 hackathon we conducted a few weeks ago. The problem statement was taken straight from the finance industry (more on that soon).
To participate in such hackathons and to practice and hone your data science skills, I highly recommend browsing through our DataHack platform. Make sure you don’t miss out on the next hackathon!
About the LTFS Data Science FinHack 2
Data Science FinHack 2 was a 9-day hackathon held between January 18th and 26th. Here’s a quick introduction to LTFS in case you need one:
Headquartered in Mumbai, LTFS is one of India’s most respected & leading NBFCs providing finance for two wheeler, farm equipment, housing, infra & microfinance. With a strong parentage & stable leadership, it also has a flourishing Mutual Fund & Wealth Advisory business under its broad umbrella.
Data Science FinHack2 was one of Analytics Vidhya’s biggest hackathons. The number of data scientists and aspirants who participated broke the previous record and the number of submissions was out of the roof as well:
- Total Registrations: 6,319
- Total Submissions: 8,090
There were a lot of lucrative prizes on offer along with interview opportunities with LTFS. Here’s the prize money distribution for the top three winners:
- Rank #1: INR 2,00,000
- Rank #2: INR 1,00,000
- Rank #3: INR 50,000
Problem Statement for the LTFS Data Science FinHack 2
I love the problem statement posed by LTFS here. So, let’s spend a moment to understand the challenge in this hackathon before we look at the top three winning solutions.
LTFS receives a lot of requests for its various finance offerings that include housing loans, two-wheeler loans, real estate financing, and microloans. The number of applications received is something that varies a lot with the season. Going through these applications is a manual and tedious process.
Accurately forecasting the number of cases received can help with resource and manpower management resulting in quick response on applications and more efficient processing.
Here was the challenge for the LTFS Data Science FinHack 2 participants:
You have been appointed with the task of forecasting daily cases for the next 3 months for 2 different business segments aggregated at the country level keeping in consideration the following major Indian festivals (inclusive but not exhaustive list): Diwali, Dussehra, Ganesh Chaturthi, Navratri, Holi, etc. (You are free to use any publicly available open-source external datasets). Some other examples could be:
- Weather
- Macroeconomic variables, etc.
Understanding the LTFS Data Science FinHack 2 Dataset
The train data was provided in the following way:
- For business segment 1, historical data was made available at branch ID level
- For business segment 2, historical data was made available at the state level
Train File
| Variable | Definition |
| application_date | Date of application |
| segment | Business Segment (1/2) |
| branch_id | Anonymized id for a branch at which application was received |
| state | State in which application was received (Karnataka, MP etc.) |
| zone | Zone of state in which application was received (Central, East etc.) |
| case_count | (Target) Number of cases/applications received |
Test File
Forecasting was to be done at the country level for the dates provided in the test set for each segment.
| Variable | Definition |
| id | Unique id for each sample in the test set |
| application_date | Date of application |
| segment | Business Segment (1/2) |
Sample Submission
This file contains the exact submission format for the forecasts.
| Variable | Definition |
| id | Unique id for each sample in the test set |
| application_date | Date of application |
| segment | Business Segment (1/2) |
| case_count | (Target) Predicted values for test set |
Evaluation Metric for the LTFS Data Science FinHack 2 Hackathon
The evaluation metric for scoring the forecasts was MAPE (Mean Absolute Percentage Error) M with the formula:

where At is the actual value and Ft is the forecast value.
The final score was calculated using MAPE for both the segments using the following formula:
![]()
You can read more about evaluation metrics in machine learning here:
Winners of the LTFS Data Science FinHack 2 Hackathon
Winning a data science hackathon is a herculean task. You are up against some of the top minds in data science – beating them and finishing in the top echelons of the leaderboard takes a lot of effort and analytical thinking (along with data science skills of course). So, hats off to the winners of the LTFS Data Science FinHack2.
Before we go through their winning approaches, let’s congratulate the winners:
- Rank 1: Team Data Science FinHack 2 (Satya and Priyadarshi)
- Rank 2: Team Data Science FinHack 2 (Abhiroop and Nitesh)
- Rank 3: Zishan Kamal
You can check out the final rankings of all the participants on the contest leaderboard.
The top three finishers have shared their detailed solution and approach from the competition. Let’s go through them each.
Rank #3: Zishan Kamal
- I segregated the data for different segments and processed and treated these 2 segments differently
- Started with a baseline model to predict using last month’s average and explored several simple time-series models, like simple average, moving average, simple exponential smoothing, Double Exponential Smoothing (HOLT’s method), Triple Exponential Smoothing (HOLT-WINTER model)
- I have also explored gradient boosting methods and deep learning methods (LSTM). I finally ended with the Facebook Prophet model for Segment 1 and LightGBM for segment 2
- Carried out outlier treatment and also removed some initial data points since they were not consistent with recent data points
- Feature Engineering – For LightGBM, I generated several date related features but finally kept the following features:
- ‘month’,
- ‘week’,
- ‘day’,
- ‘day_of_week’,
- ‘days_remaining_in_month’,
- ‘days_since’,
- ‘holiday‘
- For the Prophet model, I generated several exogenous features but nothing helped. The final Prophet model was without any exogenous features
- Here’s my Modeling Strategy:

- Cross-Validation Strategy:

- I made few adjustments (case counts for month-end and Sundays) as per cross-validation results since the model was not able to capture that even after introducing several features to help the model identify such patterns
- External dataset for holidays used
- Key Takeaway:
- A simple model can work great sometimes. Proper cross-validation is the key especially when I was using early stopping to avoid overfitting on the validation set
You can check out the full code and solution here.
Rank #2: Abhiroop and Nitesh
Here’s the approach used by Abhiroop and Nitesh:

- Data Exploration:
- Day level trend of Applications Received for Segment 1 & 2. Segment 1 was being highly impacted by the festive seasons while there was no such major change in segment 2:

- Day level year-on-year trend for Segments 1 & 2:

- For segment 2, the first 10 days of each month are almost constant while there is a decline during the month-end irrespective of the weekdays:

- Day level trend of Applications Received for Segment 1 & 2. Segment 1 was being highly impacted by the festive seasons while there was no such major change in segment 2:
- Feature Engineering and External Datasets: Based on the data visualization, we created the following features that helped the model to improve MAPE:
- Derived features from date:
- Day of the month
- Weekdays
- Week number of the month
- Week number of the year
- Month
- Year
- Quarter
- Day of the month (grouped) with Weekdays: most important feature for segment 2
- Lag Feature:
- Lag 365: # of Applications received on the same day last year
- Features from Holiday: (Source)
- Days elapsed since last holiday: 2nd most important feature for segment 1
- Holiday flag
- Derived features from date:
- Modeling Techniques used and hyperparameters used
- Segment 1
- Tbats is built on Seg1 using the seasonal period of 7 and by taking the last 420 days of application count.
- The final prediction for segment 1 has been calculated using the weighted average ensemble from Tbats and XGBoost prediction
- Final Prediction = 0.8*Tbats + 0.2*Xgboost
- Segment 2
- The final prediction for segment 2 was based just on a single XGBoost model
- Following hyperparameters were used based on the time-split validation score:
- Segment 1

- Feature Importance Plot: Derived features like days elapsed since last holiday, modified week number (custom_date_key), flags for holidays, yearly lag of count, day of the month were found to be quite helpful in improving the model accuracy.
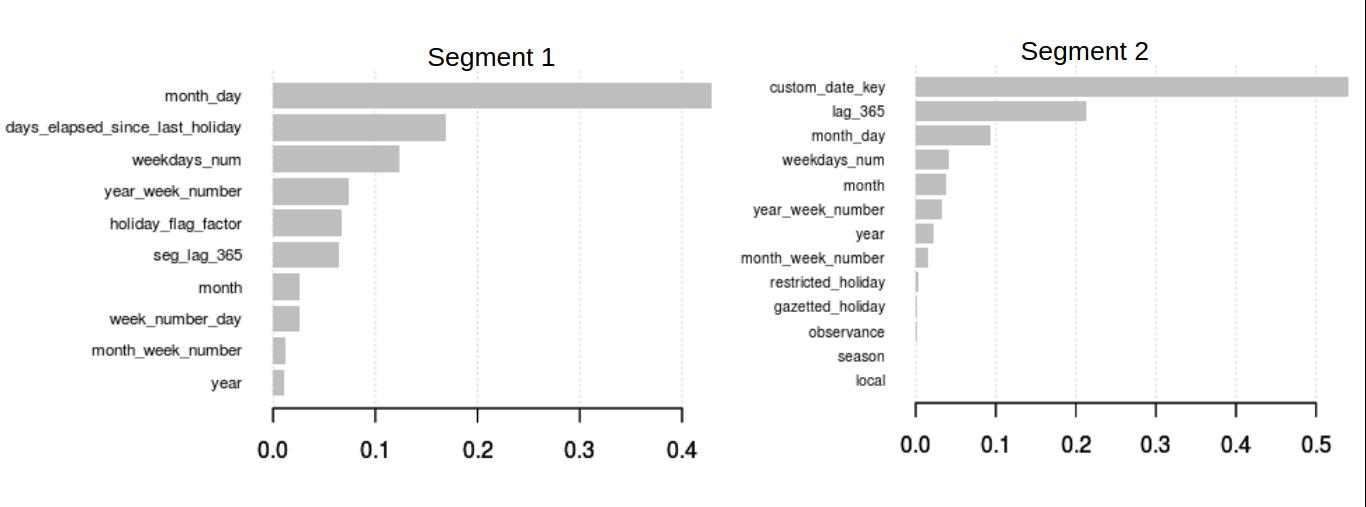
You can check out the full solution and code here.
And now, the winning solution for the LTFS Data Science FinHack 2 hackathon!
Rank #1: Satya and Priyadarshi
- Derive Steady State
- Metric time series often show a change in behavior across duration. Therefore, before we perform any behavioral analysis, it becomes evident to capture these changes and find the recent steady-state. We performed the following steps:
- Detected all possible changes in training data using the “ruptures” library in Python
- Computed statistical measures like mean, median and standard deviation for regions between detected changes
- Retained only changes that persisted for a duration > minimum duration threshold, and, had changed in statistical measure > minimum significance threshold
- Metric time series often show a change in behavior across duration. Therefore, before we perform any behavioral analysis, it becomes evident to capture these changes and find the recent steady-state. We performed the following steps:

- Compute Temporal Behavior
- Step 1 – Data segregation using Clustering: We segregated the data to handle complex temporal behavior.
- Cluster the data using clustering techniques (used k-means)
- Find the best temporal behavior (pattern) in each cluster
- If different clusters in a dataset show different patterns, we consider that data has a complex pattern and segregate it on the basis of clusters
- Otherwise, we do not segregate the data
- Insights derived from the given data:
- Segment 1: We found 2 strong clusters as follows:
- Cluster 1: Case count range (0-2724) – Best pattern: Day of Week
- Cluster 2: Case count range (2772 – 4757) – Best pattern: Day of Week
- Segregation not needed as both clusters had the same pattern.
- Segment 2: We found 3 strong clusters as follows:
- Cluster 1: Case count range (0-8623) – Best pattern: Day of Month
- Cluster 2: Case count range (9519-19680) – Best pattern: Day of Week(Sun)
- Cluster 3: Case count range (20638 – 32547) – Best pattern: Day of Month
- Segregated data based on clusters & patterns, as clusters had different patterns
- Segment 1: We found 2 strong clusters as follows:
- Step 2 – Compute temporal behavior:
- We performed the following steps to find the best temporal behavior:
- Assumption: Data contains either Day of Week or Day of Month pattern (We can add more complex patterns if required)
- Divide data into buckets of each pattern (Day of Week and Day of Month). For example: for pattern type = Day of Week, all values of Monday in one bucket and all values of Tuesday in another bucket, etc.
- Compute intra-bucket variation factor to find variation in values within a bucket. Used coefficient of variation
- Compute inter-bucket variation factor to find variation in values across buckets
- Compute average inter and intra-bucket variation for each pattern type. For example: For pattern type = Day of week, average intra-bucket variation is 0.12 & average inter-bucket variation is 0.7
- Rank the patterns with the following objective:
- Minimizing intra-bucket variation
- Maximizing inter-bucket variation
- Choose the top-ranked pattern as the best representative pattern
- Step 1 – Data segregation using Clustering: We segregated the data to handle complex temporal behavior.
- Profile Festive Behavior
- We treated the behavior during festivals differently from the normal behavior of training data. This was done to ensure that behavioral patterns and variation during festivals are correctly captured and passed on for forecasting
- We performed the following steps :
- Referred Google to find all bank holidays in the given test and train data duration
- Using the derived temporal pattern in the previous step, we aggregated data (Month wise for Day of Month and Week wise for Day of Week pattern) specific to each festival and computed statistical measures. For example: Finding deviation for August 15th (Independence Day) P = 15th August (say Day of week = Sunday). If data has Day of week pattern S = Statistical measures of previous few Sundays and if data has Day of the Month pattern then, S = Statistical measures of 15th day of past few months(April 15, May 15, June 15, July 15)
- Compute deviation between P and S to finding variation factors
- Use this change/deviation factor to model festival behavior for forecasting
- Compute Representative Values
- We computed representative values using the derived temporal patterns and multiple statistical measures. We performed the following steps:
- Prepare a bucket of values using the derived temporal pattern
- We fit a linear equation of each bucket using the sklearn library in Python to model a bucket and derive slope
- De-trend values in each bucket using the above-derived slope factor
- Derive statistical measures like mean+k(std), median+(l)MAD, Nth quantile) for a different set of k, l, N values. For example: Normal distribution range : k = [-2,2]
- Out of these derived measures, choose the one which best fits the values in the bucket. best fit value = min Error (f (mean, median, quantile))
- Compute representative values; representative value model = f(best fit value, slope)
- We computed representative values using the derived temporal patterns and multiple statistical measures. We performed the following steps:
- Predict Future Date
- By the time we reach this step, we are ready with the models across different temporal dimension values for normal as well festival days and used the same in this step to forecast future dates. We performed the following steps for the given future dates:
- Get temporal behavior of data
- Get best-fit value for the above fetched temporal behavior
- Add the trend to the representative value to get the final forecasted value
- By the time we reach this step, we are ready with the models across different temporal dimension values for normal as well festival days and used the same in this step to forecast future dates. We performed the following steps for the given future dates:
forecasted value = f(future time stamp, representative value model, festive behavior)
Here is the full code and solution for the winning approach.
Evolution of the Result for the Winning Solution



Final Thoughts
3 supreme winning solutions! That was quite a learning experience for me personally. Time series hackathons are a tricky prospect but there is a lot to glean from these winning solutions.
Which is your favorite winning solution from this list? Would you approach the problem in a different manner? Share your ideas in the comments section below!
Make sure you visit the DataHack platform for more such data science hackathons and practice problems!
Ideas have always excited me. The fact that we could dream of something and bring it to reality fascinates me. Computer Science provides me a window to do exactly that. I love programming and use it to solve problems and a beginner in the field of Data Science.







Hi Team, Is it possible to share the data used by this Hackathon so that we can explore and understand solution