Entropy is one of the key aspects of Machine Learning. It is a must to know for anyone who wants to make a mark in Machine Learning and yet it perplexes many of us. The focus of this article is to understand the working of entropy in machine learning by exploring the underlying concept of probability theory, how the formula works, its significance, and why it is important for the Decision Tree algorithm.
This article will explore the idea of entropy in machine learning, its significance in data science, and how it is related to decision trees. We will delve into the entropy formula in machine learning as well, which quantifies uncertainty and helps enhance model effectiveness. You will comprehend how entropy measures the impurity of a dataset, impacting the best way to split data in decision trees. By the end, you will completely understand how entropy enhances data-driven decision-making processes.
This article was published as a part of the Data Science Blogathon.
Table of contents
- What is Entropy in Machine Learning?
- The Origin of Entropy
- What is a Decision Tree in Machine Learning?
- Components of a Decision Tree
- Cost Function in a Decision Tree
- How Does Entropy Actually Work?
- Example of Entropy in Machine Learning
- Calculation of Entropy in Python
- Use of Entropy in Decision Tree
- Conclusion
- Frequently Asked Questions
What is Entropy in Machine Learning?
In Machine Learning, entropy measures the level of disorder or uncertainty in a given dataset or system. It is a metric that quantifies the amount of information in a dataset, and it is commonly used to evaluate the quality of a model and its ability to make accurate predictions.
A higher entropy value indicates a more heterogeneous dataset with diverse classes, while a lower entropy signifies a more pure and homogeneous subset of data. Decision tree models can use entropy to determine the best splits to make informed decisions and build accurate predictive models.
The Origin of Entropy
Claude E. Shannon’s 1948 paper on “A Mathematical Theory of Communication” marked the birth of information theory. He aimed to mathematically measure the statistical nature of lost information in phone-line signals and proposed information entropy to estimate uncertainty reduced by a message. Entropy measures the amount of surprise and data present in a variable. In information theory, a random variable’s entropy reflects the average uncertainty level in its possible outcomes. Events with higher uncertainty have higher entropy. Information theory finds applications in machine learning models, including Decision Trees. Understanding entropy helps improve data storage, communication, and decision-making.
What is a Decision Tree in Machine Learning?
The Decision Tree is a popular supervised learning technique in machine learning, serving as a hierarchical if-else statement based on feature comparison operators. It is used for regression and classification problems, finding relationships between predictor and response variables. The tree structure includes Root, Branch, and Leaf nodes, representing all possible outcomes based on specific conditions or rules. The algorithm aims to create homogenous Leaf nodes containing records of a single type in the outcome variable. However, sometimes restrictions may lead to mixed outcomes in the Leaf nodes. To build the tree, the algorithm selects features and thresholds by optimizing a loss function, aiming for the most accurate predictions. Decision Trees offer interpretable models and are widely used for various applications, from simple binary classification to complex decision-making tasks.

Components of a Decision Tree
- Root Node: This is where the tree starts. It represents the entire dataset and is divided into branches based on a chosen feature.
- Internal Nodes: These nodes represent the questions or conditions asked about the features. They lead to further branches or child nodes.
- Branches and Edges: These show the possible outcomes of a condition. They lead to child nodes or leaves.
- Leaves (Terminal Nodes): These are the end points of the tree. They represent the final decision or prediction.
Cost Function in a Decision Tree
The decision tree algorithm learns that it creates the tree from the dataset via the optimization of the cost function. In the case of classification problems, the cost or the loss function is a measure of impurity in the target column of nodes belonging to a root node.
The impurity is nothing but the surprise or the uncertainty available in the information that we had discussed above. At a given node, the impurity is a measure of a mixture of different classes or in our case a mix of different car types in the Y variable. Hence, the impurity is also referred to as heterogeneity present in the information or at every node.
The goal is to minimize this impurity as much as possible at the leaf (or the end-outcome) nodes. It means the objective function is to decrease the impurity (i.e. uncertainty or surprise) of the target column or in other words, to increase the homogeneity of the Y variable at every split of the given data.
To understand the objective function, we need to understand how the impurity or the heterogeneity of the target column is computed. There are two metrics to estimate this impurity: Entropy and Gini. In addition to this, to answer the previous question on how the decision tree chooses the attributes, there are various splitting methods including Chi-square, Gini-index, and Entropy however, the focus here is on Entropy and we will further explore how it helps to create the tree.
Example of Cost Function in a Decision Tree
Now, it’s been a while since I have been talking about a lot of theory stuff. Let’s do one thing: I offer you coffee and we perform an experiment. I have a box full of an equal number of coffee pouches of two flavors: Caramel Latte and the regular, Cappuccino. You may choose either of the flavors but with eyes closed. The fun part is: in case you get the caramel latte pouch then you are free to stop reading this article 🙂 or if you get the cappuccino pouch then you would have to read the article till the end 🙂
This predicament where you would have to decide and this decision of yours that can lead to results with equal probability is nothing else but said to be the state of maximum uncertainty. In case, I had only caramel latte coffee pouches or cappuccino pouches then we know what the outcome would have been and hence the uncertainty (or surprise) will be zero.
The probability of getting each outcome of a caramel latte pouch or cappuccino pouch is:
- P(Coffee pouch == Caramel Latte) = 0.50
- P(Coffee pouch == Cappuccino) = 1 – 0.50 = 0.50
When we have only one result either caramel latte or cappuccino pouch, then in the absence of uncertainty, the probability of the event is:
- P(Coffee pouch == Caramel Latte) = 1
- P(Coffee pouch == Cappuccino) = 1 – 1 = 0
There is a relationship between heterogeneity and uncertainty; the more heterogeneous the event the more uncertainty. On the other hand, the less heterogeneous, or so to say, the more homogeneous the event, the lesser is the uncertainty. The uncertainty is expressed as Gini or Entropy.
How Does Entropy Actually Work?
Claude E. Shannon had expressed this relationship between the probability and the heterogeneity or impurity in the mathematical form with the help of the following equation:
H(X) = – Σ (pi * log2 pi)
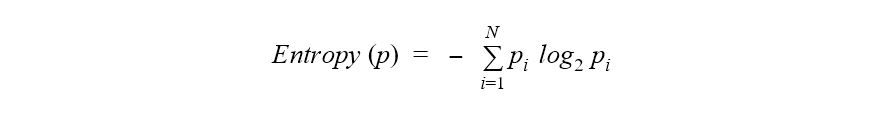
The uncertainty or the impurity is represented as the log to base 2 of the probability of a category (pi). The index (i) refers to the number of possible categories. Here, i = 2 as our problem is a binary classification.
This equation is graphically depicted by a symmetric curve as shown below. On the x-axis is the probability of the event and the y-axis indicates the heterogeneity or the impurity denoted by H(X).
Example of Entropy in Machine Learning
We will explore how the curve works in detail and then shall illustrate the calculation of entropy for our coffee flavor experiment.

The log2 pi has a very unique property that is when there are only two outcomes say probability of the event = pi is either 1 or 0.50 then in such scenario log2 pi takes the following values (ignoring the negative term):
Now, the above values of the probability and log2 pi are depicted in the following manner:

The catch is when the probability, pi becomes 0, then the value of log2 p0 moves towards infinity and the curve changes its shape to:

The entropy or the impurity measure can only take value from 0 to 1 as the probability ranges from 0 to 1 and hence, we do not want the above situation. So, to make the curve and the value of log2 pi back to zero, we multiply log2 pi with the probability i.e. with pi itself.
Therefore, the expression becomes (pi* log2 pi) and log2 pi returns a negative value and to remove this negativity effect, we multiply the resultant with a negative sign and the equation finally becomes:
H(X) = – Σ (pi * log2 pi)
Now, this expression can be used to show how the uncertainty changes depending on the likelihood of an event.
The curve finally becomes and holds the following values:

This scale of entropy from 0 to 1 is for binary classification problems. For a multiple classification problem, the above relationship holds, however, the scale may change.
Calculation of Entropy in Python
We shall estimate the entropy for three different scenarios. The event Y is getting a caramel latte coffee pouch. The heterogeneity or the impurity formula for two different classes is as follows:
H(X) = – [(pi * log2 pi) + (qi * log2 qi)]
where,
- pi = Probability of Y = 1 i.e. probability of success of the event
- qi = Probability of Y = 0 i.e. probability of failure of the event
Case 1
| Coffee flavor | Quantity of Pouches | Probability |
|---|---|---|
| Caramel Latte | 7 | 0.7 |
| Cappuccino | 3 | 0.3 |
| Total | 10 | 1 |
H(X) = – [(0.70 * log2 (0.70)) + (0.30 * log2 (0.30))] = 0.88129089
This value 0.88129089 is the measurement of uncertainty when given the box full of coffee pouches and asked to pull out one of the pouches when there are seven pouches of caramel latte flavor and three pouches of cappuccino flavor.
Case 2
| Coffee flavor | Quantity of Pouches | Probability |
|---|---|---|
| Caramel Latte | 5 | 0.5 |
| Cappuccino | 5 | 0.5 |
| Total | 10 | 1 |
H(X) = – [(0.50 * log2 (0.50)) + (0.50 * log2 (0.50))] = 1
Case 3
| Coffee flavor | Quantity of Pouches | Probability |
|---|---|---|
| Caramel Latte | 10 | 1 |
| Cappuccino | 0 | 0 |
| Total | 10 | 1 |
H(X) = – [(1.0 * log2 (1.0) + (0 * log2 (0)] ~= 0
In scenarios 2 and 3, can see that the entropy is 1 and 0, respectively. In scenario 3, when we have only one flavor of the coffee pouch, caramel latte, and have removed all the pouches of cappuccino flavor, then the uncertainty or the surprise is also completely removed and the aforementioned entropy is zero. We can then conclude that the information is 100% present.
import numpy as np
# Case 1: 7 caramel latte and 3 cappuccino coffee pouches:
-((0.70 * np.log2(0.70)) + (0.30 * np.log2(0.30)))
# Case 2: 5 caramel latte and 5 cappuccino coffee pouches:
-((0.50 * np.log2(0.50)) + (0.50 * np.log2(0.50)))
# Case 3: 10 caramel latte and 0 cappuccino coffee pouches:
-((1 * np.log2(1)) + (0 * np.log2(0)))
So, in this way, we can measure the uncertainty available when choosing between any one of the coffee pouches from the box. Now, how does the decision tree algorithm use this measurement of impurity to build the tree?
Use of Entropy in Decision Tree
As we have seen above, in decision trees the cost function is to minimize the heterogeneity in the leaf nodes.
The goal is to identify the attributes and their thresholds that, when the data is split into two, achieve the highest possible homogeneity, resulting in the maximum reduction of entropy between the two levels of the tree.
At the root level, the entropy of the target column is estimated via the formula proposed by Shannon for entropy. At every branch, the entropy computed for the target column is the weighted entropy. The weighted entropy means taking the weights of each attribute. The weights are the probability of each of the classes. The more the decrease in the entropy, the more is the information gained.
Entropy reduces information gain. You calculate information gain as 1 minus entropy. Information gain equals the entropy of the parent node minus the entropy of the child node. Data patterns show information gain.The entropy and information gain for the above three scenarios is as follows:
| Entropy | Information Gain | |
|---|---|---|
| Case 1 | 0.88129089 | 0.11870911 |
| Case 2 | 1 | 0 |
| Case 3 | 0 | 1 |
Estimation of Entropy and Information Gain at Node Level
The following tree has a root node that contains a total of four values. It splits into two branches at the first level: Branch 1 holds one value, while Branch 2 contains three values.
The entropy at the root node is 1.

Now, to compute the entropy at the child node 1, the weights are taken as ⅓ for Branch 1 and ⅔ for Branch 2 and are calculated using Shannon’s entropy formula. As we had seen above, the entropy for child node 2 is zero because there is only one value in that child node meaning there is no uncertainty and hence, the heterogeneity is not present.
H(X) = – [(1/3 * log2 (1/3)) + (2/3 * log2 (2/3))] = 0.9184
The information gain for the above tree is the reduction in the weighted average of the entropy.
Information Gain = 1 – ( ¾ * 0.9184) – (¼ *0) = 0.3112
Conclusion
Information Entropy or Shannon’s entropy quantifies the amount of uncertainty (or surprise) involved in the value of a random variable or the outcome of a random process. Its significance in the decision tree is that it allows us to estimate the impurity or heterogeneity of the target variable. Subsequently, to achieve the maximum level of homogeneity in the response variable, the child nodes are created in such a way that the total entropy of these child nodes must be less than the entropy of the parent node.
Keytakeways
Entropy plays a fundamental role in machine learning, enabling us to measure uncertainty and information content in data. Understanding entropy is crucial for building accurate decision trees and improving various learning models.Hope you get a proper understanding of entropy in machine learning.
Aspiring data scientists can deepen their knowledge and expertise in machine learning and artificial intelligence through Analytics Vidhya’s BlackBelt program. This esteemed program offers comprehensive training, empowering learners to master advanced concepts, tackle real-world challenges, and become ML/AI experts. Explore the program today!
Frequently Asked Questions
Q1. What is entropy in a decision tree?
A. In decision trees, entropy is a measure of impurity used to evaluate the homogeneity of a dataset. It helps determine the best split for building an informative decision tree model.
Q2. What does high entropy mean in machine learning?
A. In machine learning, high entropy implies a higher level of disorder or uncertainty in the data. It suggests that the data is more heterogeneous, making it challenging for models to make accurate predictions.
Q3. What do you mean by gain and entropy?
A. Gain and entropy are related concepts in decision tree algorithms. Gain measures the reduction in entropy achieved by splitting a dataset, helping to identify the best attribute for partitioning the data.
Q4. What is the meaning of entropy in AI?
A. In AI, entropy is a fundamental concept used in various applications, including decision-making, data compression, and reinforcement learning. It quantifies uncertainty and information content, guiding AI models to make informed decisions and predictions.
Q5. What is cross entropy loss?
A. Cross-entropy loss, also known as log loss, is a common loss function used in machine learning for classification tasks. It measures the difference between the predicted probability distribution of a model and the true probability distribution of the target variable.
Hi there! I am Neha Seth. I work as a Data Scientist in Larsen & Toubro Infotech (LTI). I hold a Postgraduate Program in Data Science & Engineering from the Great Lakes Institute of Management and a Bachelors in Statistics. I have been featured as Top 10 Most Popular Guest Authors in 2020 on Analytics Vidhya (AV).
My area of interest lies in NLP and Deep Learning. I have also passed the CFA Program. You can reach out to me on LinkedIn and can read my other blogs for AV.







Great article !
Beautiful work keep it up !! Amazing and vivid inputs added in this article
Very informative and nicely done