In the high-dimensional landscape of machine learning, understanding patterns in large datasets can be challenging due to what’s known as the “curse of dimensionality.” This article delves into the world of Manifold Learning, a powerful technique for dimensionality reduction, focusing specifically on locally linear Emulation (LLE). You’ll explore how this method reduces data dimensions while preserving essential relationships, making datasets more manageable and training faster.
Overview:
- Discover how this technique simplifies complex datasets by projecting them into a lower-dimensional space while retaining core patterns.
- Explore how high-dimensional data lies on low-dimensional manifolds, guiding dimensionality reduction approaches.
- Dive into LLE, a popular method in Manifold Learning that captures non-linear relationships between data points.
- Learn how to use Scikit-learn’s LocallyLinearEmbedding to apply LLE to real datasets.
- Examine how LLE performs against other dimensionality reduction techniques, visualized through the Swiss roll dataset example.
This article was published as a part of the Data Science Blogathon.
Table of Contents
The Curse of Dimensionality
A large number of machine learning datasets involve thousands and sometimes millions of features, which can make training very slow. In addition, there is plenty of space in high dimensions, making the high-dimensional datasets very sparse, as most of the training instances are quite likely to be far from each other. This increases the risk of overfitting since the predictions will be based on much larger extrapolations than those on low-dimensional data. This is called the curse of dimensionality.
There are two main approaches for dimensionality reduction: Projection and Manifold Learning. Here, we will focus on the latter.
What is Manifold Learning?
What is a manifold?
A two-dimensional manifold is any 2-D shape that can be made to fit in a higher-dimensional space by twisting or bending it, loosely speaking.
What is the Manifold Hypothesis?
“The Manifold Hypothesis states that real-world high-dimensional data lie on low-dimensional manifolds embedded within the high-dimensional space.”
In simpler terms, higher-dimensional data usually lies on a much closer lower-dimensional manifold. Manifold learning is the process of modelling the manifold on which training instances lie.

Ref: Figure 2, Gu, Rui-jun, and Wenbo Xu. “An Improved Manifold Learning Algorithm for Data Visualization.” 2006 International Conference on Machine Learning and Cybernetics (2006): 1170-1173.
Locally Linear Embedding (LLE)
Locally linear embedding (LLE) is a Manifold Learning technique used for non-linear dimensionality reduction. An unsupervised learning algorithm produces low-dimensional embeddings of high-dimensional inputs, relating each training instance to its closest neighbour.
How does LLE work?
For each training instance x(i), the algorithm finds its k nearest neighbors and then tries to express x(i) as a linear function of them. In general, if there are m training instances in total, then it tries to find the set of weights w, which minimizes the squared distance between x(i) and its linear representation.
So, the cost function is given by
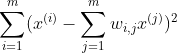
where wi,j =0, if j is not included in the k closest neighbors of i.
Also, it normalizes the weights for each training instance x(i),
.gif)
Finally, each high-dimensional training instance x(i) is mapped to a low-dimensional (say, d dimensions) vector y(i) while preserving the neighborhood relationships. This is done by choosing d-dimensional coordinates, which minimize the cost function,
.gif)
Here the weights wi,j are kept fixed while we try to find the optimum coordinates y(i)
Implementation using Scikit-learn
The following code is used to implement LLE using scikit-learn’s LocallyLinearEmbedding class:
from sklearn.manifold import LocallyLinearEmbedding
lle= LocallyLinearEmbedding(n_neighbors=5, n_components=2)
#X_transformed=lle.fit_transform(X)X_transformed=lle.fit_transform(X)Now, we will compare LLE with PCA and t-SNE on the swiss roll dataset.
#Importing the required libraries
from collections import OrderedDict
from functools import partial
from time import time
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from matplotlib.ticker import NullFormatter
from sklearn import manifold, datasets
from sklearn.decomposition import PCA
#This import is needed to silence pyflakes
Axes3D
#Then we load the swiss roll dataset
n_points = 1000
X, color = datasets.make_swiss_roll(n_points, random_state=0)
n_neighbors = 10
n_components = 2
# Creating the plot
fig = plt.figure(figsize=(15, 8))
fig.suptitle("Manifold Learning with %i points, %i neighbors"
% (1000, n_neighbors), fontsize=14)
# Adding 3d scatter plot
ax = fig.add_subplot(231, projection='3d')
ax.scatter(X[:, 0], X[:, 1], X[:, 2], c=color, cmap=plt.cm.Spectral)
ax.view_init(4, -72)
# Making a dictionary 'methods' containing LLE, t-SNE and PCA
LLE = partial(manifold.LocallyLinearEmbedding,
n_neighbors, n_components, eigen_solver='auto')
methods = OrderedDict()
methods['LLE'] = LLE(method='standard')
methods['t-SNE'] = manifold.TSNE(n_components=n_components, init='pca',
random_state=0)
methods['PCA']=PCA(n_components=2)
# Plotting the results
for i, (label, method) in enumerate(methods.items()):
t0 = time()
Y = method.fit_transform(X)
t1 = time()
print("%s: %.2g sec" % (label, t1 - t0))
ax = fig.add_subplot(2, 3, 2 + i+(i>1))
ax.scatter(Y[:, 0], Y[:, 1], c=color, cmap=plt.cm.Spectral)
ax.set_title("%s (%.2g sec)" % (label, t1 - t0))
ax.xaxis.set_major_formatter(NullFormatter())
ax.yaxis.set_major_formatter(NullFormatter())
ax.axis('tight')
plt.show()Output: We get the following plot:

The use of manifold learning is based on the assumption that our dataset or the task we are doing will be much simpler if it is expressed in lower dimensions. But this may not always be true. So, dimensionality reduction may reduce training time, but whether or not it will lead to a better solution depends on the dataset.
Conclusion
In conclusion, manifold learning, particularly Locally Linear Embedding (LLE), effectively tackles high-dimensional data by capturing its underlying structures in a reduced space. While dimensionality reduction techniques like LLE streamline training and visualization, their efficacy ultimately depends on the dataset’s complexity and structure. By simplifying data without sacrificing core relationships, manifold learning continues to enhance the interpretability and efficiency of machine learning models, making it a valuable tool in the field.
References:
- Roweis, S. T., & Saul, L. K. (2000).Nonlinear dimensionality reduction by locally linear embedding. Science(New York, N.Y.), 290(5500), 2323–2326.
- Manifold Hypothesis Definition | Deep AI
- https://scikit-learn.org/stable/modules/generated/sklearn.manifold.LocallyLinearEmbedding.html#sklearn.manifold.LocallyLinearEmbedding
- https://scikit-learn.org/stable/auto_examples/manifold/plot_compare_methods.html#sphx-glr-auto-examples-manifold-plot-compare-methods-py
Frequently Asked Questions
Q1. What is the manifold algorithm?
A. The manifold algorithm reduces data dimensions by assuming that high-dimensional data points lie on a low-dimensional manifold. Techniques like locally linear Emulation (LLE) and t-SNE model the data’s structure, simplifying complex datasets while retaining their essential relationships.
Q2. How to define a manifold?
A. A manifold is a continuous, lower-dimensional surface embedded within a higher-dimensional space. For example, a 2D plane twisted in 3D space is a 2D manifold, which can capture the essence of complex data in simpler terms, facilitating analysis and visualization.
Q3. Is manifold learning the same as dimensionality reduction?
A. Manifold learning is a type of dimensionality reduction that models data structures by assuming they lie on low-dimensional manifolds. Unlike linear techniques (e.g., PCA), manifold learning focuses on preserving non-linear relationships, making it suitable for complex datasets with underlying structures.
Q4. What is the curse of dimensionality in manifold learning?
A. The curse of dimensionality refers to the challenges arising from high-dimensional data, such as increased sparsity and slower training. As dimensions increase, data points spread further apart, making it harder to capture meaningful patterns and leading to potential overfitting in machine learning models.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.





