This article was published as a part of the Data Science Blogathon.
Introduction
Sarcasm? Well, why would someone talk bad about data science, in a data science competition, on a data science website? Well here’s why.
Ok, say let’s divide that question into three parts.
-
Why would someone talk bad about data science?
And here are the two additional statements:
-
In a data science competition
-
On a data science website
Ok, so first this data science website is Analytics Vidhya. Let’s abbreviate it as AV. let’s consider two more data science websites ABC and XYZ.
And to get an answer to this question there is only one thing we need and that’s a very well-known 4 letter word, DATA!!
So since we need data to answer the question “Why would someone talk bad about data science in a data science competition on a data science website”, we go around asking people what is their answer to that question. So do we ask random people on the streets about a specific question on a specific topic like the viral youtube videos do? HELL NO!
We are smart people (debatable!). So we ask people who are pretty experienced about the topic, I mean the users of the three data science websites- AV, ABC, and XYZ
Now we get the answer to all questions and for this blog let’s keep it a binary outcome. That is, a person would reply to the question, “ why would someone talk bad about data science?” in two ways:
-
That someone is unaware
-
That someone knows what he is talking about
Let’s call that second person who knows what he is talking about ”aware”.
So we have to outcomes “unaware” and “aware”.

Let’s assume that every data science website is holding only one such competition. We are just simplifying additional statements which we took in the beginning as only one additional statement. Don’t worry we will expand into more additional statements later.
Every person has a name but let’s simplify this and let’s give every person an ID (Coz we might be smart but we like to be lazy).
So, the data we collected would look something like this
| Person ID | Website using | His answer |
| 0001 | AV |
unaware |
| 0002 | ABC | aware |
| 0003 | XYZ |
unaware |
| 0004 | AV | unaware |
| 0005 | XYZ | aware |
| … | … | … |
Now, just looking at the head of this data of 5 rows we can say that the only 2 AV users, who are at the top of this data voted the answer as “unaware”. This is surely not enough but it gives a feeling that the AV users think that the answer is that someone who is asking this question is unaware.
The XYZ uses seem confused as one of their answers is “unaware” and one of the answers is “aware”
These conclusions which I am drawing from looking at just five rows are nonsensical but let’s face it, that’s what we all do. We have a problem. We ask 4 to 5 people and then make a decision based on our emotions about how we feel about those four to five people and how do we judge those 4 to 5 people? We look at their histories, their experiences with that specific topic we are asking, and other unrelated things as well, just to meet our cause.
This history and experiences of those participants in our survey are our features that may or may not directly affect the answer.
Apart from which data science website they use, it can also depend on which data science competitions they usually participate in, for example, in long-duration competitions or short-duration competitions? Features can also be normal human features like gender, age, IQ, creative ability, etc.
Before I jump to the final question that is why should someone talk bad about data science, let’s ask a preliminary question that is if we know what features a person possesses can we determine if he or she is more probable to answer “unaware” or “aware”

Approach #1
These features can be thought of as questions asked to the people joining the survey as in what is your gender? What data science website do you use? and so on…
If you are asking one or two people and making a conclusion after that, it would be a very biased and inaccurate conclusion. A more stylish word for this is overfitting data.
Now as many people give you an answer based on their features, let’s assume that the majority of the AV users answer “unaware”. So it will be kind of safe to conclude that if a new person claims to be an AV user then the person would most likely give “unaware” as their answer. The more luxurious word for this majority classifying process would be ensemble classifier.
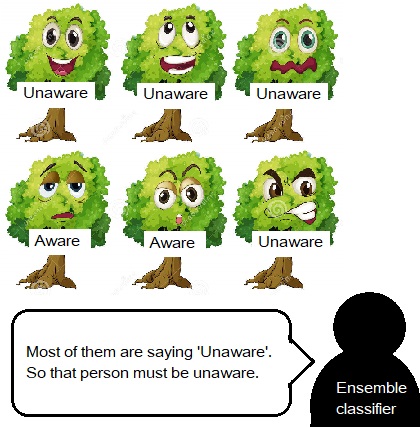
And since you want to diversify the answers of people with very similar features, you don’t ask all the same questions to them. Instead, you pick up a subset of questions to ask them. And HOLY SMOKES! you just bootstrapped your data and created a bootstrapped aggregated forest.
With trees being the participants of the survey you just implemented the very famous yet infamous Random Forest Regression.
Approach #2
By now you are thinking that let me skip this approach now that I know what approach 1 is all about and quickly skip to the conclusion because it’s getting less spicy.
But seriously? Do you really want to miss the Neural Network approach story?.
The first layer refers to the inputs you got from the people about their features.
Then there are many hidden layers that tune those inputs according to weights and biases and spit out one single output node which tells us uh whether the person would give “unaware” or “aware” as the answer.
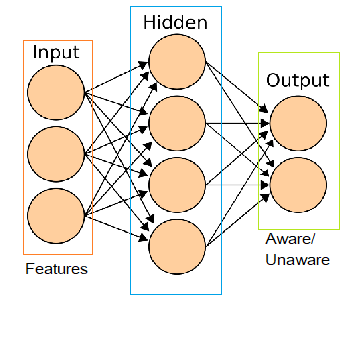
This is how a neural network works when you use it from the user end. From the neural network’s training point of view, there are many other interesting kinds of stuff happening like gradient descent, backpropagation, etc But we will not go into that.
So now, as we said that the output layer would have only a single node which would be either on (unaware) or off (aware).
But that was just the initial assumption. LET’S CRUSH IT! let’s not give the option of “unaware” and “aware” to the people who are in the survey and we will let them give their answer in a sentence to the question “Why would someone talk bad about data science?”
Now let’s bring in the tank feature of machine learning Natural Language Processing. We will find which words and phrases mean the same using NLP and simply use Unsupervised Learning to cluster the answers of the people into categories like
-
This person is unaware
-
The person knows what he is talking about
-
This person is outrageously wrong
-
This person is arrogant about his opinion
-
This person is being bold about reality
-
And so on…

Then with all the clusters, we have obtained, they will become the output nodes for a neural network and EUREKA! We have a neural network ready, that will predict whether a person will give a particular answer based on his or her features.
Conclusion
Now the real deal, the initial question was “why would someone talk bad about data science?”
[ Write in the comments what’s your answer to this question. ]
Well truly speaking, we don’t know and nor can we find an answer which will satisfy all of us?
But you do have your personal answer to this question. Right?
And you do want to surround yourself with people who have that same answer. Right?
So, next time you see a person and want to decide whether you want to be friends with him/her or not. remember this blog. Remember that there was someone brave and foolish enough to give an intuitive algorithm to describe who you should be friends with based on the answer to the question “Why is data science bad for health?”
Linkedin Link – https://www.linkedin.com/in/soumyadeep-auddy-270a89141/
Images used link – https://drive.google.com/drive/folders/1fowIwIlElvStT9J3rkpnp_8_n8lVIlMv?usp=sharing
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.






