This article was published as a part of the Data Science Blogathon.
Introduction on Apache Oozie
Apache Oozie is a tool that allows us to run any application or job in any sequence within Hadoop’s distributed environment. We may schedule the job to run at a specified time with Oozie.
What is Apache Oozie?
Apache Oozie is a Hadoop job scheduler that allows you to launch and manage processes in a distributed environment. It enables the execution of numerous complicated jobs in a sequential manner to complete a larger task. Two or more jobs can also be configured to operate in parallel inside a series of tasks.
One of the most appealing features of Oozie is that it is strongly connected with the Hadoop stack, supporting a variety of Hadoop tasks including Hive, Pig, and Sqoop, as well as system-specific processes such as Java and Shell.

Oozie is a Java Web application that is open source and licenced under the Apache 2.0 licence. It is in charge of triggering workflow operations, which then employ the Hadoop execution engine to complete the task. As a result, Oozie may take advantage of the current Hadoop infrastructure for load balancing, failover, and other functions.
Oozie uses callback and polling to identify job completion. When Oozie starts a job, it assigns it a unique callback HTTP URL and notifies that URL when the work is finished. Oozie can poll the job for completion if it fails to activate the callback URL.
It is Divided Into Two Sections:
1. Workflow engine: A workflow engine’s function is to store and operate workflows made up of Hadoop tasks like MapReduce, Pig, and Hive.
2. The coordinator engine executes workflow jobs according to preset schedules and data availability.
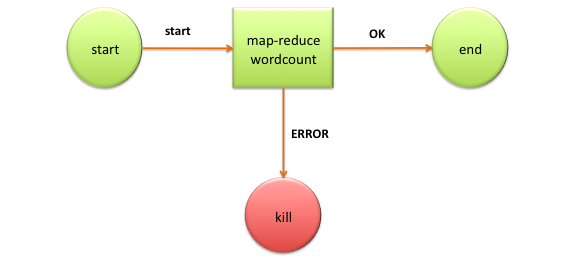
In Apache Oozie, there are Three Sorts of Jobs:
Oozie Workflow jobs are Directed Acyclic Graphs (DAGs) that define a set of activities to be performed.
Workflow jobs triggered by time and data availability are called Oozie Coordinator Jobs.
Oozie Bundles are a collection of many coordinators and workflow jobs in one bundle.
Why Use Oozie?
There are many reasons to use Oozie. It has many features and is easy to implement. Let us see some of the best reasons to use Oozie:
- The primary goal of Oozie is to handle various types of tasks that are processed in the Hadoop environment. A user specifies work dependencies using Directed Acyclic Graphs. Oozie reads this data and ensures that tasks are completed in the right sequence as stated in a process. As a result, the user’s time to handle the entire workflow is saved. In addition, Oozie allows you to choose the frequency with which a job is executed.
- Oozie is scalable and can run thousands of workflows (each containing dozens of tasks) on a Hadoop cluster in real-time.
- Oozie is also quite adaptable. Jobs can be simply started, stopped, suspended, and restarted. Rerunning failed processes is a breeze with Oozie. It’s easy to see how tough it might be to make up for jobs that were missed or failed due to delay or failure. It’s even possible to bypass a failed node entirely.
- Callback and polling are used by Apache Oozie to detect task completion. When Oozie begins a job, it assigns it a unique callback HTTP URL and notifies that URL when the work is finished. Oozie can poll the job for completion if it fails to activate the callback URL.
Oozie Features
Oozie has multiple features, the main features of Oozie are as follows:
- Oozie includes a client API and a command-line interface that may be used to start, control, and monitor jobs from a Java programme.
- Its Web Service APIs allow users to manage tasks from anywhere.
- Oozie offers the ability to run jobs that are scheduled to run on a regular basis.
- Oozie provides the ability to send email reminders when jobs are completed.
What is Apache Oozie Workflow, and How Does it Work?
A Hadoop Job is an Apache Oozie workflow. It is a DAG that has a collection of action and control nodes. Each action represents a Hadoop job, Pig, Hive, Sqoop, or Hadoop DistCp job in a directed acyclic graph (DAG) that captures control dependency. There are alternative actions outside Hadoop jobs, such as a Java application, a shell script, or an email notice.
The sequence in which these operations are executed is determined by the node’s position in the process. Any new action will not begin until the preceding one has finished. The control nodes in a workflow oversee the action execution flow. The control nodes’ start and finish determine the start and end of the workflow. The fork and join control nodes aid in the execution of simultaneous tasks. The decision control node is a switch/case statement that uses job information to pick a certain execution path inside the workflow.
Types of Nodes on Oozie Workflow
Nodes play an important role in Oozie, let us have a look at the important nodes in the Oozie workflow:
Start and End Note
The start and end nodes establish the workflow’s start and finish points. Optional fail nodes are included in these nodes.
Action Nodes
Action nodes define the actual processing tasks. When a given action node completes and the following node in the workflow is run, the system sends a remote notification to Oozie. The action nodes include HDFS commands as well.
Fork and Join Nodes
A fork and join node is used to perform parallel execution of jobs in the workflow. Fork nodes allow two or more nodes to execute at the same time. In some circumstances, we must wait for some specified jobs to finish their work before using this connect node.
Control Flow Nodes
Nodes in the control flow make judgments regarding prior tasks. The outcome of the preceding nodes is used to create control nodes. If-else sentences that evaluate to true or false are called control flow nodes.
Apache Oozie Control Flow Nodes
Start control nodes, end control nodes, and kill control nodes are used to specify the beginning and end of a process, while decision, fork, and join nodes are used to govern the workflow execution route.
The Nodes in the Apache Oozie Control flow are listed below:
- Start control node
- End control node
- Kill control node
- Decision control node
- Fork and Join control node
1) Start Control Node
The start control node is where a workflow job begins. It is a point of entry for workflow jobs. Each workflow definition will contain a start node, and when the task is launched, it will default to the node specified in the start node.
Syntax:
... ...
2) End Control Node
The end node marks the end of a workflow job, indicating that it was successfully finished. When a workflow job reaches its conclusion, it is effectively completed.
The actions will be stopped if one or more actions initiated by the workflow job are still running when the end node is reached. In this case, the workflow job is still regarded to have been completed successfully. One end node is required in a workflow specification.
Syntax:
...
...
3) Kill Control Node
A workflow job is terminated using the Kill control node. The actions will be killed if one or more actions begun by the workflow job are still running when the kill node is reached.
Syntax:
...
[MESSAGE-TO-LOG]
...
4) Decision Control Node
A decision node is used in a process to allow it to choose which execution route it should take. It’s made up of a list of predicates and transitions, as well as a default transition. Predicates are estimated in the order of appearance until one of them evaluates to true, at which point the appropriate transition is made. If none of the predicates evaluates to true, then the default transition is used.
Syntax:
...
[PREDICATE]
...
[PREDICATE]
...
5) Fork and Join Control Node
The fork node divides the execution path into many concurrent pathways, while the join node waits for all concurrent execution paths from previous fork nodes to arrive. Both the Fork and Join nodes should be used together.
Syntax:
...
...
...
...
Conclusion
We had a look at what is Apache Oozie, now to sum up:
- Apache Oozie is a web application written in Java that works with Apache Hadoop installations. Apache Oozie is a task management tool for big data systems that work in the Hadoop ecosystem with other individual products like YARN, MapReduce, and Pig.
- Individual job tasks are grouped into logical work units by Apache Oozie. It enables more advanced scheduling and work management.
- Engineers may use Oozie to build complicated data processes that make Hadoop operations easier to manage.
Apache Oozie is available under an Apache Foundation software licence and is part of the Hadoop toolset, which is considered an open-source software system rather than a commercial, vendor-licensed system by the community. Since Hadoop has become so popular for analytics and other types of enterprise computing, tools like Oozie are increasingly being considered as solutions for data handling projects within enterprise IT.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Prateek is a dynamic professional with a strong foundation in Artificial Intelligence and Data Science, currently pursuing his PGP at Jio Institute. He holds a Bachelor's degree in Electrical Engineering and has hands-on experience as a System Engineer at TCS Digital, where he excelled in API management and data integration. Prateek also has a background in product marketing and analytics from his time with start-ups like AppleX and Milkie Way, Inc., where he was involved in growth campaigns and technical blog management. Recognized for his structured thinking and problem-solving abilities, he has received accolades like the Dr. Sudarshan Chakraborty Award for Best Student Performance. Fluent in multiple languages and passionate about technology, Prateek continues to expand his expertise in the rapidly evolving AI and tech landscape.






