Job descriptions of Data Engineering roles have changed drastically over the years. In 2026, these read less like data plumbing and more like production engineering. You are expected to ship pipelines that don’t break at 2 AM, scale cleanly, and stay compliant while they do it. So, no – “I know Python and Spark” alone doesn’t cut it anymore.
Instead, today’s stack is centred around cloud warehouses + ELT, dbt-led transformations, orchestration, data quality tests that actually fail pipelines, and boring-but-critical disciplines like schema evolution, data contracts, IAM, and governance. Add lakehouse table formats, streaming, and containerised deployments, and the skill bar goes very high, very fast.
So, if you’re starting in 2026 (or even revisiting your plan to become a data engineer), this roadmap is for you. Here, we cover a month-by-month path to learning the best skills that are required in today’s data engineering roles. If you master these, you will become employable and not just “tool-aware.” Let’s jump right in and explore all that is necessary in the most systematic way possible.
Table of contents
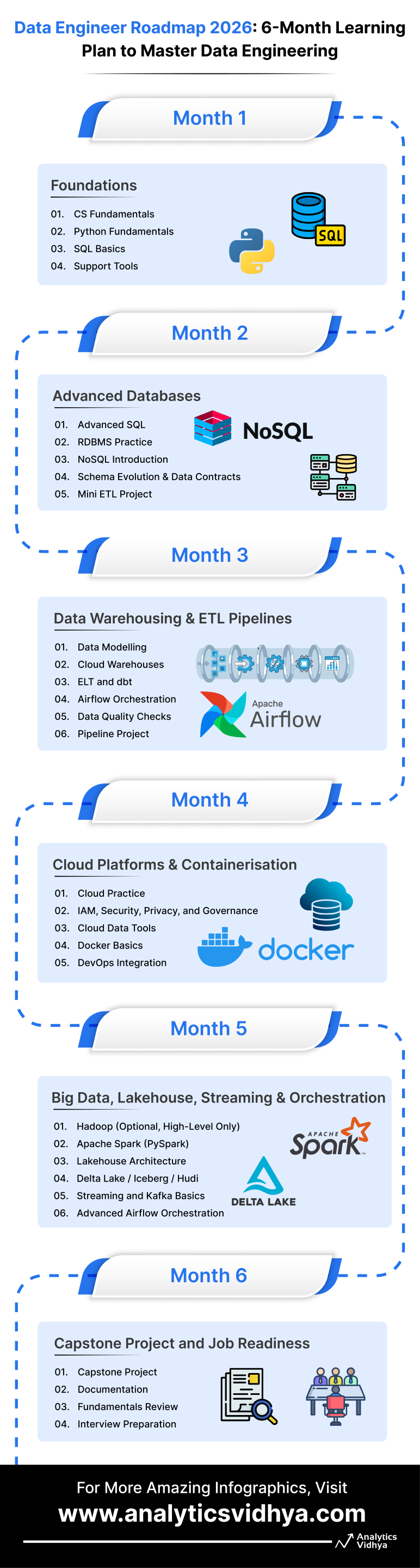
Month 1: Foundations
To Learn: CS Fundamentals, Python, SQL, Linux, Git
Let’s be honest. Month 1 is not the “exciting” month. There is no Spark cluster, shiny dashboards, or Kafka streams. But if you skip this foundation, everything that follows in this roadmap to becoming a data engineer becomes harder than it needs to be. So start early, start strong!
CS Fundamentals
Start with computer science basics. Learn core data structures like arrays, linked lists, trees, and hash tables. Add basic algorithms like sorting and searching. Learn time complexity so you can judge whether your code will scale well. Also, learn object-oriented programming (OOP) concepts, because most real pipelines are built as reusable modules and not single-use scripts.
Python Fundamentals
Next, get solid with Python programming. Focus on clean syntax, functions, control flow, and writing readable code. Learn basic OOP, but more importantly, build the habit of documenting what you write. In 2026, your code will be reviewed, maintained, and reused. So treat it like a product, not a notebook experiment.
SQL Basics
Alongside Python, start SQL basics. Learn SELECT, JOIN, GROUP BY, subqueries, and aggregations. SQL is still the language that runs the data world, and the faster you get comfortable with it, the easier every later month becomes. Use something like PostgreSQL or MySQL, load a sample dataset, and practice daily.
Support Tools
Finally, don’t ignore the “supporting tools.” Learn basic Linux/Unix shell commands (bash) because servers and pipelines live there. Set up Git and start pushing everything to GitHub/GitLab from day one. Version control is not optional in production teams.
Month 1 Goal
By the end of Month 1, your goal is simple: you should be able to write clean Python, query data confidently with SQL, and work comfortably in a terminal with Git. That baseline will carry you through the entire roadmap.
Month 2: Advanced Databases
To Learn: Advanced SQL, RDBMS Practice, NoSQL, Schema Evolution & Data Contracts, Mini ETL Project
Month 2 is where you move from “I can write queries” to “I can design and query databases properly.” In most data engineering roles, SQL is one of the main filters. So this month in the roadmap to becoming a data engineer is about becoming genuinely strong at it, while also expanding into NoSQL and modern schema practices.
Advanced SQL
Start upgrading your SQL skill set. Practice complex multi-table JOINs, window functions (ROW_NUMBER, RANK, LEAD/LAG), and CTEs. Also learn basic query tuning: how indexes work, how to read query plans, and how to spot slow queries. Efficient SQL at scale is one of the most repeated requirements in data engineering job interviews.
RDBMS Practice
Pick a relational database like PostgreSQL or MySQL and build proper schemas. Try designing a simple analytics-friendly structure, such as a star schema (fact and dimension tables), using a realistic dataset like sales, transactions, or sensor logs. This gives you hands-on practice with data modelling.
NoSQL Introduction
Now add one NoSQL database to your toolkit. Choose something like MongoDB (document store) or DynamoDB (key-value). Learn what makes NoSQL different: flexible schemas, horizontal scaling, and faster writes in many real-time systems. Also understand the trade-off: you often give up complex joins and rigid structure for speed and flexibility.
Schema Evolution & Data Contracts
This is a 2026 skill that matters a lot more than it did earlier. Learn how to handle schema changes safely: adding columns, renaming fields, maintaining backward/forward compatibility, and using versioning. Alongside that, understand the idea of data contracts, which are clear agreements between data producers and consumers, so pipelines don’t break when data formats change.
Mini ETL Project
End the month with a small but complete ETL pipeline. Extract data from a CSV or public API, clean and transform it using Python, then load it into your SQL database. Automate it with a simple script or scheduler. Do not aim for complexity. The goal, instead, is to build confidence in moving data end-to-end.
Month 2 Goal
By the end of Month 2, you should be able to write strong SQL queries, design sensible schemas, understand when to use SQL vs NoSQL, and build a small and reliable ETL pipeline.
Month 3: Data Warehousing & ETL Pipelines
To Learn: Data Modelling, Cloud Warehouses, ELT with dbt, Airflow Orchestration, Data Quality Checks, Pipeline Project
Month 3 in this roadmap is where you start working like a modern data engineer. You move beyond databases and enter real-world analytics, building warehouse-based pipelines at scale. This is also the month where you learn two important tools that show up everywhere in 2026 data teams: dbt and Airflow.
Data Modelling
Start with data modelling for analytics. Learn star and snowflake schemas, and understand why fact tables and dimension tables make reporting faster and simpler. You do not need to become a modelling expert in one month, but you should understand how good modelling reduces confusion for downstream teams.
Cloud Warehouses
Next, get hands-on with a cloud data warehouse. Pick one: BigQuery, Snowflake, or Redshift. Learn how to load data, run queries, and manage tables. These warehouses are built for OLAP workloads and are central to most modern analytics stacks.
ELT and dbt
Now shift from classic ETL thinking to ELT. In 2026, most teams load raw data first and do transformations inside the warehouse. This is where dbt becomes important. Learn how to:
- create models (SQL transformations)
- manage dependencies between models
- write tests (null checks, uniqueness, accepted values)
- document your models so others can use them confidently
Airflow Orchestration
Once you have ingestion and transformations, you need automation. Install Airflow (local or Docker) and build simple Directed Acyclic Graphs or DAGs. Learn how scheduling works, how retries work, and how to monitor pipeline runs. Airflow is not just a “scheduler.” It is the control centre for production pipelines.
Data Quality Checks
This is a non-negotiable 2026 skill. Add automated checks for:
- nulls and missing values
- freshness (data arriving on time)
- ranges and invalid values
Use dbt tests, and if you want deeper validation, try Great Expectations. The key point: when data is bad, the pipeline should fail early.
Pipeline Project
End Month 3 with a complete warehouse pipeline:
- fetch data daily from an API or files
- load raw data into your warehouse
- transform it with dbt into clean tables
- schedule everything with Airflow
- add data tests so failures are visible
This project becomes a strong portfolio piece because it resembles a real workplace workflow.
Month 3 Goal
By the end of Month 3, you should be able to load data into a cloud warehouse, transform it using dbt, automate the workflow with Airflow, and add data quality checks that prevent bad data from quietly entering your system.
Month 4: Cloud Platforms & Containerisation
To Learn: Cloud Practice, IAM Basics, Security & Governance, Cloud Data Tools, Docker, DevOps Integration
Month 4 in the data engineer roadmap is where you stop thinking only about pipelines and start thinking about how those pipelines run in the real world. In 2026, data engineers are expected to understand cloud environments, basic security, and how to deploy and maintain workloads in consistent environments, and month 4 in this roadmap prepares you for just that.
Cloud Practice
Pick one cloud platform: AWS, GCP, or Azure. Learn the core services that data teams use:
- storage (S3 / GCS / Blob Storage)
- compute (EC2 / Compute Engine / VMs)
- managed databases (RDS / Cloud SQL)
- basic querying tools (Athena, BigQuery, Synapse-style querying)
Also learn basic cloud concepts like regions, networking basics (high-level is fine), and cost awareness.
IAM, Security, Privacy, and Governance
Now focus on access control and safety. Learn IAM basics: roles, policies, least privilege, and service accounts. Understand how teams handle secrets (API keys, credentials). Learn what PII is and how it is protected using masking and access restrictions. Also get familiar with governance ideas like:
- row/column-level security
- data catalogues
- governance tools (Lake Formation, Unity Catalog)
You do not need to become a security specialist, but you must understand what “secure by default” looks like.
Cloud Data Tools
Explore one or two managed data services in your chosen cloud. Examples:
- AWS Glue, EMR, Redshift
- GCP Dataflow, Dataproc, BigQuery
- Azure Data Factory, Synapse
Even if you do not master them, understand what they do and what they are replacing (self-managed Spark clusters, manual scripts, etc.).
Docker Basics
Now learn Docker. The goal is simple: package your data workload so it runs the same everywhere. Containerise one thing you have already built, such as:
- your Python ETL job
- your Airflow setup
- a small dbt project runner
Learn how to write a Dockerfile, build an image, and run containers locally.
DevOps Integration
Finally, connect your work to a basic engineering workflow:
- use Docker Compose to run multi-service setups (Airflow + Postgres, etc.)
- set up a simple CI pipeline (GitHub Actions) that runs checks/tests on each commit
This is how modern teams keep pipelines stable.
Month 4 Goal
By the end of Month 4, you should be able to use one cloud platform comfortably, understand IAM and basic governance, run a data workflow in Docker, and apply simple CI practices to keep your pipeline code reliable.
Month 5: Big Data, Lakehouse, Streaming, and Orchestration
To Learn: Spark (PySpark), Lakehouse Architecture, Table Formats (Delta/Iceberg/Hudi), Kafka, Advanced Airflow
Month 5 in this roadmap to becoming a data engineer is about handling scale. Even if you are not processing massive datasets on day one, most teams still expect data engineers to understand distributed processing, lakehouse storage, and streaming systems. This month builds that layer.
Hadoop (Optional, High-Level Only)
In 2026, you do not need deep Hadoop expertise. But you should know what it is and why it existed. Learn what HDFS, YARN, and MapReduce were built for, and what problems they solved at the time. Remember, only study these for your awareness. Do not try to master them, because most modern stacks have moved toward Spark and lakehouse systems.
Apache Spark (PySpark)
Spark is still the default choice for batch processing at scale. Learn how Spark works with DataFrames, what transformations and actions mean, and how SparkSQL fits into real pipelines. Spend time understanding the basics of partitioning and shuffles, because these two concepts explain most performance issues. Practice by processing a larger dataset than what you typically use Pandas for, and compare the workflow.
Lakehouse Architecture
Now move to lakehouse architecture. Many teams want the low-cost storage of a data lake, but with the reliability of a warehouse. Lakehouse systems aim to provide that middle ground. Learn what changes when you treat data on object storage as a structured analytics system, especially around reliability, versioning, and schema handling.
Delta Lake / Iceberg / Hudi
These table formats are a big part of why lakehouse works in practice. Learn what they add on top of raw files: better metadata management, ACID-style reliability, schema enforcement, and support for schema evolution. You do not need to master all three, but you should understand why they exist and what problems they solve in production pipelines.
Streaming and Kafka Basics
Streaming matters because many organisations want data to arrive continuously rather than in daily batches. Start with Kafka and learn how topics, partitions, producers, and consumers work together. Understand how teams use streaming pipelines for event data, clickstreams, logs, and real-time monitoring. The goal is to understand the architecture clearly, not to become a Kafka operator.
Advanced Airflow Orchestration
Finally, level up your orchestration skills by writing more production-style Airflow DAGs. You can try to:
- add retries and alerting
- run Spark jobs through Airflow operators
- set up failure notifications
- schedule batch and near-real-time jobs
This is very close to what production orchestration looks like.
Month 5 Goal
By the end of Month 5 as a data engineer, you should be able to run batch transformations in Spark, explain how lakehouse systems work, understand why Delta/Iceberg/Hudi matter, and describe how Kafka-based streaming pipelines operate. You should also be able to orchestrate these workflows with Airflow in a reliable, production-minded way.
Month 6: Capstone Project and Job Readiness
To Learn: End-to-End Pipeline Design, Documentation, Fundamentals Revision, Interview Preparation
Month 6 in this data engineer roadmap is where everything comes together. The goal is to build one complete project that proves you can work like a real data engineer. This single capstone will matter more than ten small tutorials, because it demonstrates full ownership of a pipeline.
Capstone Project
Build an end-to-end pipeline that covers the modern 2026 stack. Here’s what your Month 6 capstone should include. Keep it simple, but make sure every part is present.
- Ingest data in batch (daily files/logs) or as a stream (API events)
- Land raw data in cloud storage such as S3 or GCS
- Transform the data using Spark or Python
- Load cleaned outputs into a cloud warehouse like Snowflake or BigQuery
- Orchestrate the workflow using Airflow
- Run key components in Docker so the project is reproducible
- Add data quality checks for nulls, freshness, duplicates, and invalid values
Make sure your pipeline fails clearly when data breaks. This is one of the strongest signals that your project is production-minded and not just a demo.
Documentation
Documentation is not an extra task. It is part of the project. Create a clear README that explains what your pipeline does, why you made certain choices, and how someone else can run it. Add a simple architecture diagram, a data dictionary, and clean code comments. In real teams, strong documentation often separates good engineers from average ones.
Fundamentals Review
Now revisit the basics. Review SQL joins, window functions, schema design, and common query patterns. Refresh Python fundamentals, especially data manipulation and writing clean functions. You should be able to explain key trade-offs such as ETL vs ELT, OLTP vs OLAP, and SQL vs NoSQL without hesitation.
Interview Preparation
Spend time practising interview-style questions. Solve SQL puzzles, work on Python coding exercises, and prepare to discuss your capstone in detail. Be ready to explain how you handle retries, failures, schema changes, and data quality issues. In 2026 interviews, companies care less about whether you “used a tool” and more about whether you understand how to build reliable pipelines.
Month 6 Goal
By the end of Month 6, you should have a complete, well-documented data engineering project, strong fundamentals in SQL and Python, and clear answers for common interview questions. Because now, you have completely surpassed the learning stage and are ready to put your skills to use in a real job.
Conclusion
As I said before, in 2026, data engineering is no longer just about knowing tools. It now revolves around building pipelines that are reliable, secure, and easy to operate at scale. If you follow this six-month roadmap religiously and finish it with a strong capstone, there is no way you won’t be ready as a modern-day data engineer.
Not just on papers, you will have the skills that modern teams actually look for: solid SQL and Python, warehouse-first ELT, orchestration, data quality, governance awareness, and the ability to ship end-to-end systems. At that point of this roadmap, you will have already become a data engineer. All you will then need is a job to make it official.






