“You can’t prove a hypothesis; you can only improve or disprove it.” – Christopher Monckton
Every day we find ourselves testing new ideas, finding the fastest route to the office, the quickest way to finish our work, or simply finding a better way to do something we love. The critical question, then, is whether our idea is significantly better than what we tried previously. These ideas that we come up with on such a regular basis – that’s essentially what a hypothesis is. Testing these ideas to figure out which one works and which one is best left behind is called hypothesis testing. Sometimes, this involves statistical analysis like a t-test to determine the significance of our findings.

Hypothesis testing is one of the most fascinating things we do as data scientists. No idea is off-limits at this stage of our project. One of the most popular ways to test a hypothesis in machine learning is a concept called the t-test. In this article, we will learn about the various nuances of a t-test and then look at the three different t-test types. We will also implement each type of t-test in R to visualize how they work in practical scenarios.
Learning Objectives
- To introduce the concept of t-tests and their importance in data science.
- To explain the different types of t-tests and when each type is appropriate to use.
- To provide hands-on experience in implementing t-tests in R with step-by-step tutorials.
- To demonstrate how to interpret the output generated by t-tests and make inferences based on the test results.
Note: You should go through the below article if you need to brush up on your hypothesis-testing concepts: Guide to Master Hypothesis Testing in Statistics.
Table of contents
What is T-Test?
A t-test is a statistical hypothesis test that is used to determine whether there is a significant difference between the means of two groups. It helps you assess whether any observed difference between the groups is statistically significant or not.
The t-test is based on the t-distribution, which is a mathematical distribution similar to the normal distribution but with heavier tails. The test calculates a t-statistic, which measures the difference between the means of the two groups in terms of the standard error of the difference. The larger the t-statistic, the more likely that the difference between the groups’ means is significant.
When Should We Perform a T-test?
Let’s first understand where a t-test can be used before we dive into its different types and their implementations. I strongly believe the best way to learn a concept is by visualizing it through an example. So let’s take a simple example to see where a t-test comes in handy.
Consider a telecom company that has two service centres in the city. The company wants to find out whether the average time required to service a customer is the same in both stores.
The company measures the average time taken by 50 random customers in each store. Store A takes 22 minutes, while Store B averages 25 minutes. Can we say that Store A is more efficient than Store B in terms of customer service?
It does seem that way, doesn’t it? However, we have only looked at 50 random customers out of the many people who visit the stores. Simply looking at the average sample time might not be representative of all the customers who visit both stores.
This is where the ttest comes into play. It helps us understand if the difference between two sample means is actually real or simply due to chance.
How T-Test is Used?
- Get Data: First, scientists gather information from two groups they want to compare, like test scores from students who studied differently.
- Guesses: They make guesses about whether there’s a big difference between the groups or not. One guess says there’s no difference (null hypothesis), and the other says there is (alternative hypothesis).
- Pick the Right Test: Depending on the data, they choose which type of t-tests to use.
- Check the Data: Before doing the t-test, they make sure the data is okay to use.
- Do the Math: They use formulas to calculate a number called the t-value, which shows how much the groups differ from each other.
- Check the Result: They also calculate another number called the p-value, which tells them how likely it is to see the differences they found if there really isn’t a difference between the groups.
- Make a Decision: If the p-value is really small, they say there’s probably a real difference between the groups. If it’s not so small, they say there might not be a big difference after all.
Assumptions for Performing a T-test
There are certain assumptions we need to heed before performing a t-test:
- The data should follow a continuous or ordinal scale (the IQ test scores of students, for example)
- The observations in the data should be randomly selected
- The data should resemble a bell-shaped curve when we plot it, i.e., it should be normally distributed. You can refer to this article to get a better understanding of the normal distribution.
- A large sample size should be taken for the data to approach a normal distribution (although a t test is essential for small samples as their distributions are non-normal)
- Variances among the groups should be equal (for independent two-sample t-test)
So what are the different types of t-tests? When should we perform each type? We’ll answer these questions in the next section and see how we can perform each t-test type in R.
Types of T-tests (With Solved Examples in R)
There are three types of t-tests we can perform based on the data at hand:
- One sample t-test
- Independent two-sample t-test
- Paired sample t-test
In this section, we will look at each of these types in detail. I have also provided the R code for each t-test type so you can follow along as we implement them. It’s a great way to learn and see how useful these t-tests are!
One-Sample t-test
In a one-sample t-test, we compare the average (or mean parameter) of one group against the set average (or mean). This set average can be any theoretical value (or it can be the population mean).

Consider the following example – A research scholar wants to determine if the average eating time for a (standard size) burger differs from a set value. Let’s say this value is 10 minutes. How do you think the research scholar can go about determining this?
He/she can broadly follow the below steps:
- Select a group of people
- Record the individual eating time of a standard-size burger
- Calculate the average eating time for the group
- Finally, compare that average value with the set value of 10
That, in a nutshell, is how we can perform a one-sample t-test. Here’s the formula to calculate this:

where,
- t = t-statistic
- m = mean of the group
- µ = theoretical value or population mean
- s = standard deviation of the group
- n = group size or sample size
Note: As mentioned earlier in the assumptions, that large sample size should be taken for the data to approach a normal distribution. (Although t-test is essential for small samples as their distributions are non-normal).
Once we have calculated the t-value, the next task is to compare it with the critical value of the t-test. We can find this in the below t-test table against the degree of freedom (n-1) and the level of significance:
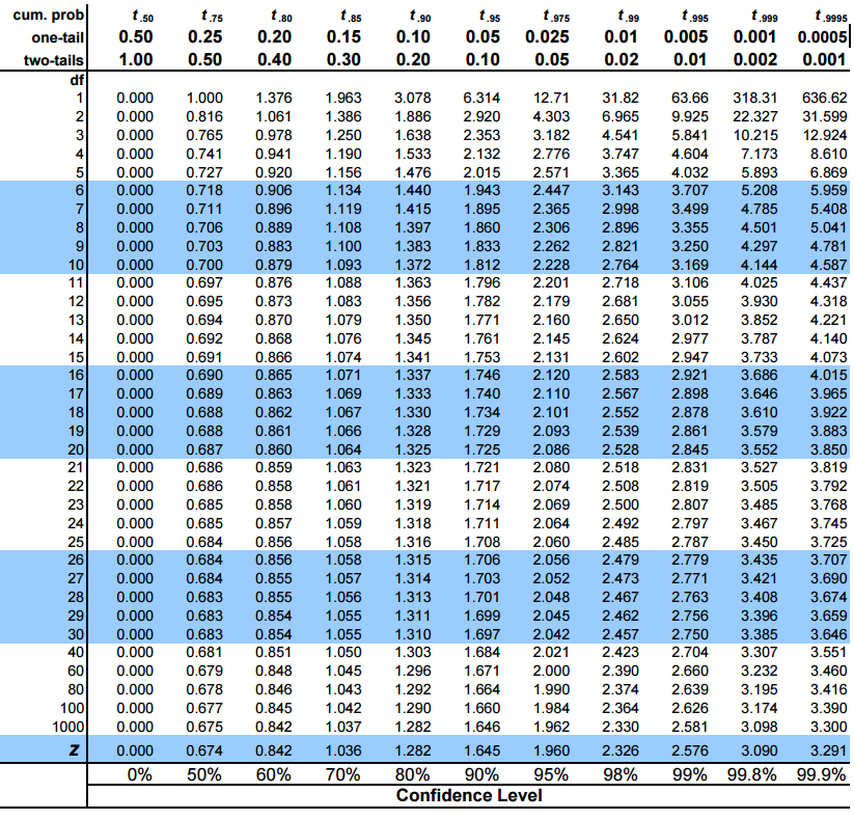
This method helps us check whether the difference between the means is statistically significant or not. Let’s further solidify our understanding of a one-sample t-test by performing it in R.
Implementing the One-Sample t-test in R
A mobile manufacturing company has taken a sample of mobiles of the same model from the previous month’s data. They want to check whether the average screen size of the sample differs from the desired length of 10 cm. You can download the data here.
Step 1: First, import the data.
Step 2: Validate it for correctness in R:
#Step 1 - Importing Data
#_______________________________________________________
#Importing the csv data
data<-read.csv(file.choose())
#Step 2 - Validate data for correctness
#______________________________________________________
#Count of Rows and columns
dim(data)
#View top 10 rows of the dataset
head(data,10)Output:
#Count of Rows and columns
[1] 1000 1
> #View top 10 rows of the dataset
Screen_size.in.cm.
1 10.006692
2 10.081624
3 10.072873
4 9.954496
5 9.994093
6 9.952208
7 9.947936
8 9.988184
9 9.993365
10 10.016660
Step 3: Remember the assumptions we discussed earlier? We are going to check them now.
#Step 3 - Check for assumptions
#______________________________________________________
#1. Data is continuous.
#2. Observations are randomly selected.
#3. To check the data is normally distributed, we will use the following codes:
qqnorm(data$Screen_size.in.cm.)
qqline(data$Screen_size.in.cm.,col="red")We get the below Q-Q plot:

Almost all the values lie on the red line. We can confidently say that the data follows a normal distribution.
Step 4: Conduct a one-sample t-test:
#Step 5 - Conduct one-sample t-test
#Null Hypothesis: Mean screensize of sample does not differ from 10 cm
#Alternate Hypothesis: Mean screensize of sample differ from 10 cm
t.test(data$Screen_size.in.cm.,mu=10)Output:
One Sample t-test
data: data$Screen_size.in.cm.
t = -0.39548, df = 999, p-value = 0.6926
alternative hypothesis: true mean is not equal to 10
95 percent confidence interval:
9.996361 10.002418
sample estimates:
mean of x
9.99939The t-statistic comes out to be -0.39548. Note that we can treat negative values as their positive counterpart here. Now, refer to the table mentioned earlier for the t-critical value. The degree of freedom here is 999, and the confidence interval is 95%.
The t-critical value is 1.962. Since the t-statistic is less than the t-critical value, we fail to reject the null hypothesis and can conclude that the average screen size of the sample does not differ from 10 cm.
We can also verify this from the p-value, which is greater than 0.05. Therefore, we fail to reject the null hypothesis at a 95% confidence interval.
Independent Two-Sample t-test
The two-sample t-test is used to compare the means of two different samples.
Let’s say we want to compare the average height of the male employees to the average height of the females. Of course, the number of males and females should be equal for this comparison. This is where a two-sample t-test is used.
Here’s the formula to calculate the t-statistic for a two-sample t-test:

where,
- mA and mB are the means of two different samples
- nA and nB are the sample sizes
- S2 is an estimator of the common variance of two samples, such as:

Here, the degree of freedom is nA + nB – 2.
We will follow the same logic we saw in a one-sample t-test to check if the average of one group is significantly different from another group. That’s right – we will compare the calculated t-statistic with the t-critical value.
Let’s take an example of an independent two-sample t-test and solve it in R.
Implementing the Two-Sample t-test in R
For this section, we will work with two sample data of the various models of a mobile phone. We want to check whether the mean screen size of sample 1 differs from the mean screen size of sample 2. You can download the data here.
Step 1: Again, first import the data.
Step 2: Validate it for correctness in R:
#Step 1 - Importing Data
#_______________________________________________________
#Importing the csv data
data<-read.csv(file.choose())
#Step 2 - Validate data for correctness
#______________________________________________________
#Count of Rows and columns
dim(data)
#View top 10 rows of the dataset
head(data,10)Step 3: We need to check the assumptions as we did above. I will leave that exercise up to you now.
Also, in this case, we will check the homogeneity of variance:
#Homogeneity of variance
var(data$screensize_sample1)
var(data$screensize_sample2)Output:
#Homogeneity of variance
> var(data$screensize_sample1)
[1] 0.00238283
> var(data$screensize_sample2)
[1] 0.002353585Great, the variances are equal. We can move ahead.
Step 4: Conduct the independent two-sample t-test:
#Step 4 - Conduct two-sample t-test
#Null Hypothesis: There is no difference between the mean of two samples
#Alternate Hypothesis: There is difference between the men of two samples
t.test(data$screensize_sample1,data$screensize_sample2,var.equal = T)Note: Rewrite the above code with “var.equal = F” if you get unequal or unknown variances. This will be a case of Welch’s t-test, which is used to compare the means of two samples with unequal variances.
Output:
Two Sample t-test
data: data$screensize_sample1 and data$screensize_sample2
t = 1.3072, df = 1998, p-value = 0.1913
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-0.001423145 0.007113085
sample estimates:
mean of x mean of y
10.000976 9.998131What can you infer from the above output? We can confirm that the t-statistic is again less than the t-critical value, so we fail to reject the null hypothesis. Hence, we can conclude that there is no difference between the mean screen size of both samples.
We can verify this again using the p-value. It comes out to be greater than 0.05. Therefore, we fail to reject the null hypothesis at a 95% confidence interval. There is no difference between the mean of the two samples.
Paired Sample t-test
The paired sample t-test is quite intriguing. Here, we measure one group at two different times. We compare separate means for a group at two different times or under two different conditions. Confused? Let me explain.
A certain manager realized that the productivity level of his employees was trending significantly downwards. This manager decided to conduct a training program for all his employees to increase their productivity levels.
How will the manager measure if the productivity levels have increased? It’s simple – just compare the productivity level of the employees before versus after the training program.
Here, we are comparing the same sample (the employees) at two different times (before and after the training). This is an example of a paired t-test. The formula to calculate the t-statistic for a paired t-test is:

where,
- t = t-statistic
- m = mean of the group
- µ = theoretical value or population mean
- s = standard deviation of the group
- n = group size or sample size
We can take the degree of freedom in this test as n – 1 since only one group is involved. Now, let’s solve an example in R.
Implementing the Paired t-test in R
The manager of a tyre manufacturing company wants to compare the rubber material for two lots of tires. One way to do this – check the difference between the average kilometers covered by one lot of tires until they wear out.
You can download the data from here. Let’s do this!
Step 1: First, import the data.
Step 2: Validate it for correctness in R:
#Step 1 - Importing Data
#_______________________________________________________
#Importing the csv data
data<-read.csv(file.choose())
#Step 2 - Validate data for correctness
#______________________________________________________
#Count of Rows and columns
dim(data)
#View top 10 rows of the dataset
head(data,10)Step 3: We now check the assumptions just as we did in a one-sample t-test. Again, I will leave this to you.
Step 4: Conduct the paired t-test:
#Step 4 - Conduct two-sample t-test
#Null Hypothesis: There is no difference between the means of tyres before and after changing the rubber material.
#Alternate Hypothesis: There is a difference between the means of tyres before and after changing the rubber material.
t.test(data$tyre_1,data$tyre_2,paired = T)Output:
Paired t-test
data: data$tyre_1 and data$tyre_2
t = -5.2662, df = 24, p-value = 2.121e-05
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-2201.6929 -961.8515
sample estimates:
mean of the differences
-1581.772You must be a pro at deciphering this output by now! The p-value is less than 0.05. We can reject the null hypothesis at a 95% confidence interval and conclude that there is a significant difference between the means of tyres before and after the rubber material replacement.
The negative mean in the difference depicts that the average kilometres covered by tyre 2 are more than the average kilometres covered by tyre 1.
T-Test Formulas
Here are the two Most Common T test Formula:
Here are the two most common:
- Independent Samples t-test: This is ued to compare the means of two independent groups. The formula is: t = (X₁ – X₂) / √(Sp² / n₁ + Sp² / n₂) where:
- X₁ and X₂ are the means of the two groups
- Sp² is the pooled variance (calculated using the formula in the link below)
- n₁ and n₂ are the number of observations in each group
- One-Sample t-test: This is used to compare the mean of a single sample to a hypothesized population mean. The formula is: t = (X – μ) / (Sx / √n) where:
- X is the sample mean
- μ is the hypothesized population mean
- Sx is the sample standard deviation
- n is the number of observations in the sample
What is the difference between a t-test and an Anova?
- T-test:
- A t-test is used when comparing the means of two groups to determine if they are significantly different from each other.
- It is typically used when you have a categorical independent variable with two levels (e.g., comparing test scores between two groups of students – males vs. females).
- There are different types of t-tests: independent samples t-test (when the groups are independent of each other) and paired samples t-test (when the groups are related or matched).
- ANOVA (Analysis of Variance):
- ANOVA is used when comparing the means of three or more groups to determine if at least one group is significantly different from the others.
- It is used when you have a categorical independent variable with three or more levels (e.g., comparing test scores among students in different grades – 9th, 10th, 11th, and 12th).
- ANOVA tests if there is any significant variance between the group means and doesn’t tell you which specific groups differ from each other.
Conclusion
In this article, we learned about the concept of t-tests in statistics, their assumptions, and also the three different types of t-tests with their implementations in R. The t-test has both statistical significance as well as practical applications in the real world. If you are new to statistics, want to cover your basics, and also want to get a start in data science, I recommend taking the Introduction to Data Science course. It gives you a comprehensive overview of both descriptive and inferential statistics before diving into data science techniques.
Key Takeaways
- T-tests are a type of hypothesis testing used in statistical analysis and data analysis to determine if there is a significant difference between the means of two groups.
- There are 3 types of t-tests which are explained in the article with their implementation.
- Implementation of t-tests in R, including both paired and unpaired t-tests.
Frequently Asked Humanities
Q1. What is a null hypothesis in a t-test?
A. In a t-test, the null hypothesis is a statement about a population parameter that the researcher wants to evaluate. The null hypothesis states that there is no difference or no relationship between the two groups or data samples being studied. In other words, it is a hypothesis of no effect or no difference.
Q2. When should the t-test be used?
A. Use a t-test to compare means of two groups in hypothesis testing. It tells you if the difference is significant or just a random chance.
Q3. What are the two uses of t-test?
A. T-tests compare averages of two groups (e.g., men vs. women’s height).
They also check if one group’s average differs from a known value (e.g., newborn weight vs. national average).
Q4. What is the normal t-test?
A. The “normal” t-test typically refers to the independent samples t-test, which is the most commonly used form of t-test. It’s called “normal” not because it assumes a normal distribution (though that’s often the case in its application), but because it’s the standard and frequently used version of the t-test. This test compares the means of two independent groups to determine if they are significantly different from each other.







I have an interview lined up for this week and I have already bookmarked this article for my preparation. Thanks a lot
Hello Karan, Best of luck for the interview.
Great article!
Thanks for the appreciation.
Very good article, thanks