There are many different ways in which machine learning models make decisions. Decision Trees and Random Forests are two of the most common decision-making processes used in ML. Hence, there is always confusion, comparison, and debate about Random Forest vs. Decision Tree. They both have advantages, disadvantages, and specific use cases, based on which we can choose the right one specific to our requirements and project. This article will provide you with all the information required to make this choice between decision tree vs random forest.
Learning Objectives
- A brief Introduction to Decision Trees and an overview of random forests.
- Clash of Random Forest and Decision Tree (in Code!): Why did random forest outperform decision tree, and when should we choose which algorithm?

Table of contents
Random Forest vs Decision Tree Explained by Analogy
Let’s start with a thought experiment to illustrate the difference between a decision tree and a random forest model.
Suppose a bank has to approve a small loan amount for a customer and needs to make a decision quickly. The bank checks the person’s credit history and financial condition and finds that they haven’t repaid the older loan yet. Hence, the bank rejects the application. But here’s the catch—the loan amount was very small for the bank’s immense coffers, and they could have easily approved it in a very low-risk move. Therefore, the bank lost the chance of making some money.
Now, a few days later, another loan application comes in, but this time, the bank comes up with a different strategy—multiple decision-making processes. Sometimes, it checks for credit history first, and sometimes, it checks for the customer’s financial condition and loan amount first. Then, the bank combines the results from these multiple decision-making processes and decides to give the loan to the customer.
The bank profited from this method even though it took longer than the previous one. This is a classic example of collective decision-making outperforming a single decision-making process. Now, here’s my question: Do you know what these two processes represent?
Machine Learning is a sub-branch of Artificial Intelligence. These are decision trees and a random forest! We’ll explore this idea in detail here, dive into the major differences between these two methods, and answer the key question—which machine learning algorithm should you choose?
Overview of Random Forest vs Decision Tree
| Aspect | Random Forest | Decision Tree |
|---|---|---|
| Nature | Ensemble of multiple decision trees | Single decision tree |
| Bias-Variance Trade-off | Lower variance, reduced overfitting | Higher variance, prone to overfitting |
| Predictive Accuracy | Generally higher due to ensemble | Less interpretable due to the ensemble |
| Robustness | More robust to outliers and noise | Sensitive to outliers and noise |
| Training Time | Slower due to multiple tree construction | Faster as it builds a single tree |
| Interpretability | Provides feature importance but less reliable | More interpretable as a single tree |
| Feature Importance | Provides feature importance scores | Provides feature importance but is less reliable |
| Usage | Suitable for complex tasks, high-dimensional data | Simple tasks, easy interpretation |
What Are Decision Trees?
A decision tree is a supervised machine-learning algorithm that can be used for both classification and regression problems. The algorithm builds its model in the structure of a tree along with decision nodes and leaf nodes. A decision tree is a series of sequential decisions made to reach a specific result. Here’s an illustration of a decision tree in action (using our above example):

Let’s understand how this tree works
First, it checks if the customer has a good credit history. Based on that, it classifies the customer into two groups: customers with good credit history and customers with bad credit history. Then, it checks the customer’s income and again classifies him/her into two groups. Finally, it checks the loan amount requested by the customer. Based on the outcomes from checking these three features, the decision tree decides whether the customer’s loan should be approved.
The features/attributes and conditions can change based on the data and complexity of the problem, but the overall idea remains the same. So, a decision tree makes a series of decisions based on a set of features/attributes present in the data: credit history, income, and loan amount.
Now, you might be wondering:
Why did the decision tree check the credit score first and not the income?
This is known as feature importance, and the sequence of attributes to be checked is decided based on criteria like the Gini Impurity Index or Information Gain. The explanation of these concepts is outside the scope of our article here, but you can refer to either of the below resources to learn all about decision trees:
- Tree-Based Algorithms: A Complete Tutorial from Scratch (in R & Python)
- Getting Started with Decision Trees (Free Course)
What Is Random Forest?
The decision tree algorithm is quite easy to understand and interpret. However, data scientists mostly use random forests; a single tree is not sufficient for producing effective results. This is where the Random Forest algorithm comes into the picture.

Random Forest is a tree-based machine-learning algorithm that leverages the power of multiple decision trees to make decisions. As the name suggests, it is a “forest” of trees!
But why do we call it a “random” forest? That’s because it is a forest of randomly created decision trees. Each node in the decision tree works on a random subset of features to calculate the output. The random forest then combines the output of individual decision trees to generate the final output. Bootstrapping is the process of randomly selecting items from the training dataset. This is a haphazard technique. It assembles randomized decisions based on several decisions and makes the final decision based on the majority voting.
In simple words:
The Random Forest Algorithm combines the output of multiple (randomly created) Decision Trees to generate the final output.
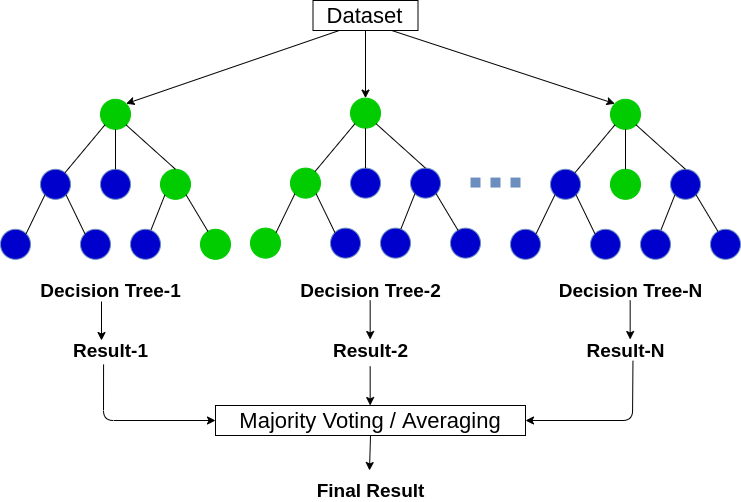
This process of combining the output of multiple individual models (also known as weak learners) is called Ensemble Learning. If you want to read more about how the random forest and other ensemble learning algorithms work, check out the following articles:
- Building a Random Forest from Scratch & Understanding Real-World Data Products
- A Beginner’s Guide to Random Forest Hyperparameter Tuning
- A Comprehensive Guide to Ensemble Learning (with Python codes)
- How to build Ensemble Models in Machine Learning? (with code in R)
Now, the question is, how can we decide between a decision tree and a random forest algorithm? Let’s see them both in action before we make any conclusions!
Random Forest vs. Decision Tree in Python
In this section, we will use Python to solve a binary classification problem using a decision tree and a random forest. We will then compare their results and see which one best suits our problem.
We’ll work on the Loan Prediction dataset from Analytics Vidhya’s DataHack platform. This is a binary classification problem in which we have to determine whether a person should be given a loan based on a certain set of features.
Note: You can go to the DataHack platform and compete with other people in various online machine-learning competitions to win exciting prizes.
Ready to code?
Step 1: Loading the Libraries and Dataset
Let’s start by importing the required Python libraries and our dataset:
The dataset comprises 614 rows and 13 features, including credit history, marital status, loan amount, and gender. Here, the target variable is Loan_Status, which indicates whether a person should be given a loan or not.
Step 2: Data Preprocessing
Now comes the most crucial part of any data science project: data preprocessing and feature engineering. In this section, I will deal with the categorical variables in the data and input the missing values.
I will impute the missing values in the categorical variables with the mode and the continuous variables with the mean (for the respective columns). We will also label encode the categorical values in the data. You can read this article to learn more about Label Encoding.
Python Code:
import pandas as pd
import numpy as np
# Importing dataset
df=pd.read_csv('dataset.csv')
print(df.head())
df['Gender']=df['Gender'].map({'Male':1,'Female':0})
df['Married']=df['Married'].map({'Yes':1,'No':0})
df['Education']=df['Education'].map({'Graduate':1,'Not Graduate':0})
df['Dependents'].replace('3+',3,inplace=True)
df['Self_Employed']=df['Self_Employed'].map({'Yes':1,'No':0})
df['Property_Area']=df['Property_Area'].map({'Semiurban':1,'Urban':2,'Rural':3})
df['Loan_Status']=df['Loan_Status'].map({'Y':1,'N':0})
#Null Value Imputation
rev_null=['Gender','Married','Dependents','Self_Employed','Credit_History','LoanAmount','Loan_Amount_Term']
df[rev_null]=df[rev_null].replace({np.nan:df['Gender'].mode(),
np.nan:df['Married'].mode(),
np.nan:df['Dependents'].mode(),
np.nan:df['Self_Employed'].mode(),
np.nan:df['Credit_History'].mode(),
np.nan:df['LoanAmount'].mean(),
np.nan:df['Loan_Amount_Term'].mean()})
print(df.head())Step 3: Creating Train and Test Sets
Now, let’s split the dataset in an 80:20 ratio for training and test set, respectively:
X=df.drop(columns=['Loan_ID','Loan_Status']).values
Y=df['Loan_Status'].values
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.2, random_state = 42)
Let’s take a look at the shape of the created train and test sets:
print('Shape of X_train=>',X_train.shape)
print('Shape of X_test=>',X_test.shape)
print('Shape of Y_train=>',Y_train.shape)
print('Shape of Y_test=>',Y_test.shape)

Great! Now we are ready for the next stage, where we’ll build the decision tree and random forest models!
Step 4: Building and Evaluating the Model
Since we have both the training and testing sets, it’s time to train our models and classify the loan applications. First, we will train a decision tree on this dataset:
# Building Decision Tree
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(criterion = 'entropy', random_state = 42)
dt.fit(X_train, Y_train)
dt_pred_train = dt.predict(X_train)
Next, we will evaluate this model using F1-Score. F1-Score is the harmonic mean of precision and recall given by the formula:

You can learn more about this and various other evaluation metrics here:
Let’s evaluate the performance of our model using the F1 score:

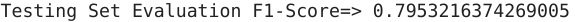
Here, you can see that the decision tree performs well on in-sample evaluation, but its performance decreases drastically on out-of-sample evaluation. Why do you think that’s the case? Unfortunately, our decision tree model is overfitting on the training data. Will random forest solve this issue?
Building a Random Forest Model
Let’s see a random forest model in action:


Here, we can see that the random forest model performed much better than the decision tree in the out-of-sample evaluation. Let’s discuss the reasons behind this in the next section.
Why Did Our Random Forest Model Outperform the Decision Tree?
Random forest leverages the power of multiple decision trees. It does not rely on the importance of features given by a single decision tree. Let’s take a look at the feature importance given by different algorithms to different features:
feature_importance=pd.DataFrame({
'rfc':rfc.feature_importances_,
'dt':dt.feature_importances_
},index=df.drop(columns=['Loan_ID','Loan_Status']).columns)
feature_importance.sort_values(by='rfc',ascending=True,inplace=True)
index = np.arange(len(feature_importance))
fig, ax = plt.subplots(figsize=(18,8))
rfc_feature=ax.barh(index,feature_importance['rfc'],0.4,color='purple',label='Random Forest')
dt_feature=ax.barh(index+0.4,feature_importance['dt'],0.4,color='lightgreen',label='Decision Tree')
ax.set(yticks=index+0.4,yticklabels=feature_importance.index)
ax.legend()
plt.show()As you can clearly see in the above graph, the decision tree model prioritizes a particular set of features. However, the random forest chooses features randomly during the training process. Therefore, it does not depend heavily on any specific set of features. This is a special characteristic of random forests over bagging trees. You can read more about the classifier for bagging trees here.
Therefore, a random forest can better generalize the data. This randomized feature selection makes a random forest much more accurate than a decision tree.
How to Choose Between Decision Tree & Random Forest?
So, what is the final verdict in the Random Forest vs Decision Tree debate? How do we decide which one is better and which one to choose?
Random Forest is suitable for situations with a large dataset and no major concern for interpretability.
Decision trees are much easier to interpret and understand. We take multiple decision trees in a random forest and then aggregate the result. Since a random forest combines multiple decision trees, it becomes more difficult to interpret. Here’s the good news: interpreting a random forest is not impossible. Here is an article that talks about interpreting results from a random forest model:
- Decoding the Black Box: An Important Introduction to Interpretable Machine Learning Models in Python.
Also, a Random Forest has a higher training time than a single decision tree. You should consider this because as we increase the number of trees in a random forest, the time to train each also increases. That can often be crucial when working with a tight deadline in a machine learning project.
But I will say this – despite instability and dependency on a particular set of features, decision trees are helpful because they are easier to interpret and faster to train. Anyone with very little knowledge of data science/data analytics can also use decision trees to make quick, data-driven decisions.
Conclusion
Hope by now you’ve figured out how to pick a side in the random forest vs decision tree debate. A decision tree is a choice collection, while a random forest is a collection of decision trees. It can get tricky when you’re new to machine learning, but hopefully, this article has clarified the differences and similarities between decision tree vs random forest. Note that the random forest is a predictive modeling tool, not a descriptive one. The random forest has complex data visualization and accurate predictions, but the decision tree has simple visualization and less accurate predictions. The advantages of Random Forest are that it prevents overfitting and is more accurate in predictions.
Key Takeaways
- A decision tree is simpler and more interpretable but prone to overfitting, while a random forest is complex and prevents the risk of overfitting.
- Random forest is more robust and generalized when performing on new data, and it is widely used in various domains such as finance, healthcare, and deep learning.
Frequently Asked Questions
Q1. Which algorithm is better: decision tree or random forest?
A. Random forest is a strong modeling technique and much more robust than a decision tree. Many Decision trees are aggregated to limit overfitting and errors due to bias and achieve the final result.
Q2. How do you choose between a decision tree and a random forest?
A. A decision tree is a combination of decisions, and a random forest is a combination of many decision trees. A random forest is slow, but a decision tree is fast and easy on large data, especially on regression tasks.
Q3. What is a decision tree?
A. It is a supervised learning algorithm utilized for both classification and regression tasks. It consists of a hierarchical tree structure with a root node, branches, internal nodes, and leaf nodes.
Q4. Is random forest more accurate than a decision tree?
A. Random forests are generally more accurate than individual decision trees because they combine multiple trees and reduce overfitting, providing better predictive performance and robustness.
He is a data science aficionado, who loves diving into data and generating insights from it. He is always ready for making machines to learn through code and writing technical blogs. His areas of interest include Machine Learning and Natural Language Processing still open for something new and exciting.







Hello Sir, This is so helpful especially to me as an interested researcher in ML and DA. Kindly more of these will be of help.
Thank you, Ogwoka Thaddeus.
Nice article...easily understandable.Highly recommended for beginners n non programmers
Thank you, Srujana Soppa. I am glad you enjoyed it.
Good Explaination...Thanks
You're welcome, Shahnawaz Sayyed.